目錄
- 一、基礎第三方庫使用
- 二、爬蟲的網頁抓取
- 三、動態網頁和靜態網頁的區分
- 四、動態網頁和靜態網頁的抓取
一、基礎第三方庫使用
1.基本使用方法
"""例"""
from urllib import request
response = request.urlopen(r'http://bbs.pinggu.org/')
#返回狀態 200證明訪問成功
print("返回狀態碼: "+str(response.status))
#讀取頁面信息轉換文本并進行解碼,如果本身是UTF-8就不要,具體看頁面格式
#搜索“charset”查看編碼格式
response.read().decode('gbk')[:100]

2.Request
使用request()來包裝請求,再通過urlopen()獲取頁面。俗稱偽裝。讓服務器知道我們是通過瀏覽器來訪問的頁面,有些情況可能會被直接斃掉。
url = r'http://bbs.pinggu.org/'
headers = {'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': r'http://www.lagou.com/zhaopin/Python/?labelWords=label',
'Connection': 'keep-alive'}
req = request.Request(url, headers=headers)
page = request.urlopen(req).read()
page = page.decode('gbk')
page[:100]

包含data的方法。
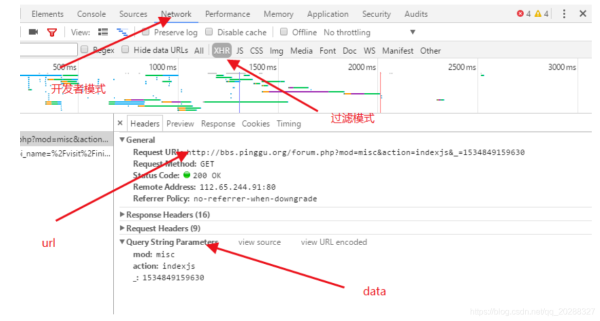
import urllib.parse
url = r'https://new-api.meiqia.com/v1/throttle/web?api_name=%2Fvisit%2Finitent_id=7276v=1534848690048'
headers = {'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': r'http://www.lagou.com/zhaopin/Python/?labelWords=label',
'Connection': 'keep-alive'}
values={'api_name':'/visit/init','ent_id':'7276','v':'1534848690048'}
data = urllib.parse.urlencode(values).encode(encoding='UTF8')
req = request.Request(url, data,headers=headers)
page = request.urlopen(req).read()
page = page.decode('gbk')
3.異常處理
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
req = Request("http://www.jb51.net /")
try:
response = urlopen(req)
except HTTPError as e:
print('服務器無法滿足請求.')
print('錯誤代碼: ', e.code)
except URLError as e:
print('不能訪問服務器.')
print('原因: ', e.reason)
else:
print("OK!")
print(response.read().decode("utf8"))

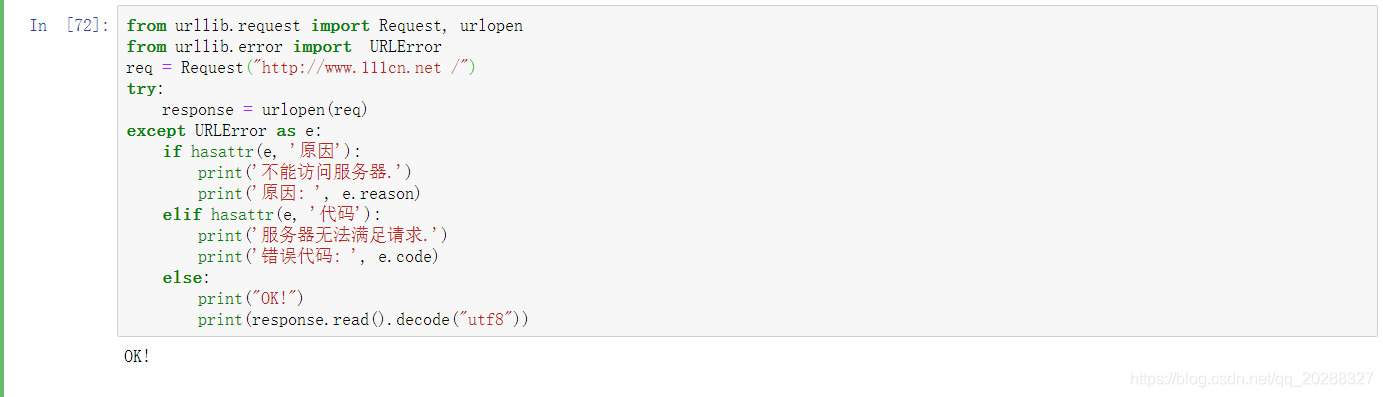
from urllib.request import Request, urlopen
from urllib.error import URLError
req = Request("http://www.jb51.net /")
try:
response = urlopen(req)
except URLError as e:
if hasattr(e, '原因'):
print('不能訪問服務器.')
print('原因: ', e.reason)
elif hasattr(e, '代碼'):
print('服務器無法滿足請求.')
print('錯誤代碼: ', e.code)
else:
print("OK!")
print(response.read().decode("utf8"))
4.HTTP認證
import urllib.request
# 私密代理授權的賬戶
user = "user_name"
# 私密代理授權的密碼
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理隨便選擇即可
proxyserver = "177.87.168.97:53281"
# 1. 構建一個密碼管理對象,用來保存需要處理的用戶名和密碼
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加賬戶信息,第一個參數realm是與遠程服務器相關的域信息,一般沒人管它都是寫None,后面三個參數分別是 代理服務器、用戶名、密碼
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 構建一個代理基礎用戶名/密碼驗證的ProxyBasicAuthHandler處理器對象,參數是創建的密碼管理對象
# 注意,這里不再使用普通ProxyHandler類了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通過 build_opener()方法使用這些代理Handler對象,創建自定義opener對象,參數包括構建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 構造Request 請求
request = urllib.request.Request("http://bbs.pinggu.org/")
# 6. 使用自定義opener發送請求
response = opener.open(request)
# 7. 打印響應內容
print (response.read())
5.ROBOT協議
目標網址后加/robots.txt,例如:https://www.jd.com/robots.txt
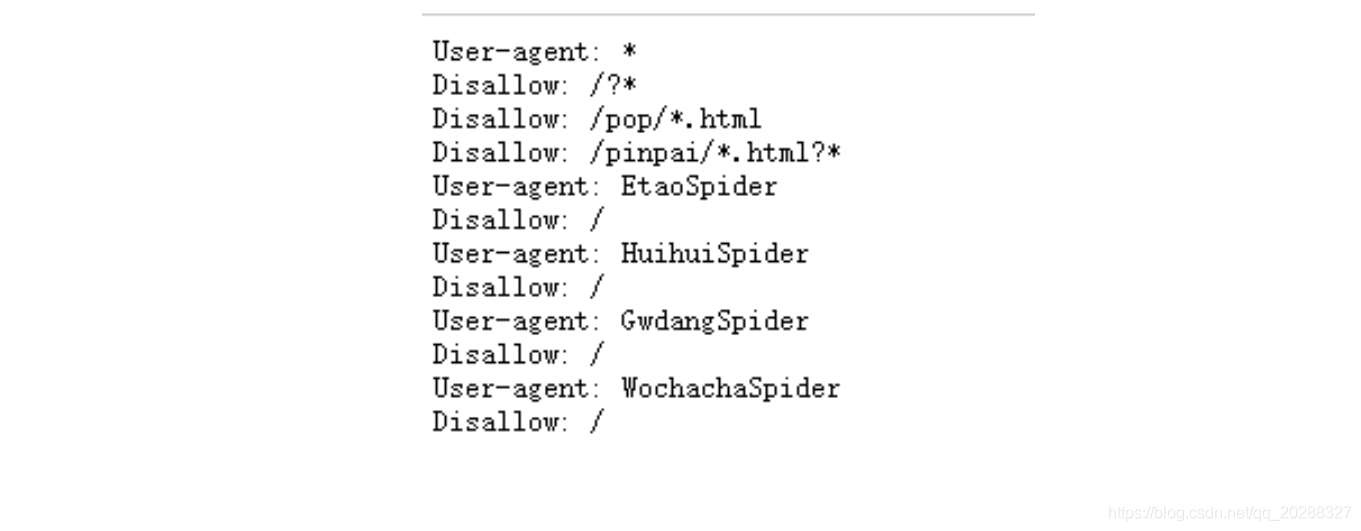
第一個的意思就是說對于所有的爬蟲,不能爬取在/?開頭的路徑,也不能訪問和/pop/*.html 匹配的路徑。
后面四個用戶代理的爬蟲不允許訪問任何資源。
所以Robots協議的基本語法如下:
- User-agent: 這里是爬蟲的名字
- Disallow: /該爬蟲不允許訪問的內容。
二、爬蟲的網頁抓取
1.爬蟲的用途
實現瀏覽器的功能,通過制定的URL,直接返回用戶所需要的數據。
一般步驟:
- 查找域名對應的IP地址 (比如:119.75.217.109是哪個網站?)。
- 向對應的IP地址發送get或者post請求。
- 服務器相應結果200,返回網頁內容。
- 開始抓你想要的東西吧。
2.網頁分析
獲取對應內容之后進行分析,其實就需要對一個文本進行處理,把你需要的內容從網頁中的代碼中提取出來的過程。BeautifulSoup可實現慣用的文檔導航、查找、修改文檔功能。如果lib文件夾下沒有BeautifulSoup的使用命令行安裝即可。
pip install BeautifulSoup
3.數據提取
# 想要抓取我們需要的東西需要進行定位,尋找到標志
from bs4 import BeautifulSoup
soup = BeautifulSoup('meta content="all" name="robots" />',"html.parser")
tag=soup.meta
# tag的類別
type(tag)
>>> bs4.element.Tag
# tag的name屬性
tag.name
>>> 'meta'
# attributes屬性
tag.attrs
>>> {'content': 'all', 'name': 'robots'}
# BeautifulSoup屬性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> '[document]'
# 字符串的提取
markup='b>a rel="external nofollow" target="_blank">房產/a>/b>'
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> '房產'
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 應用舉例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
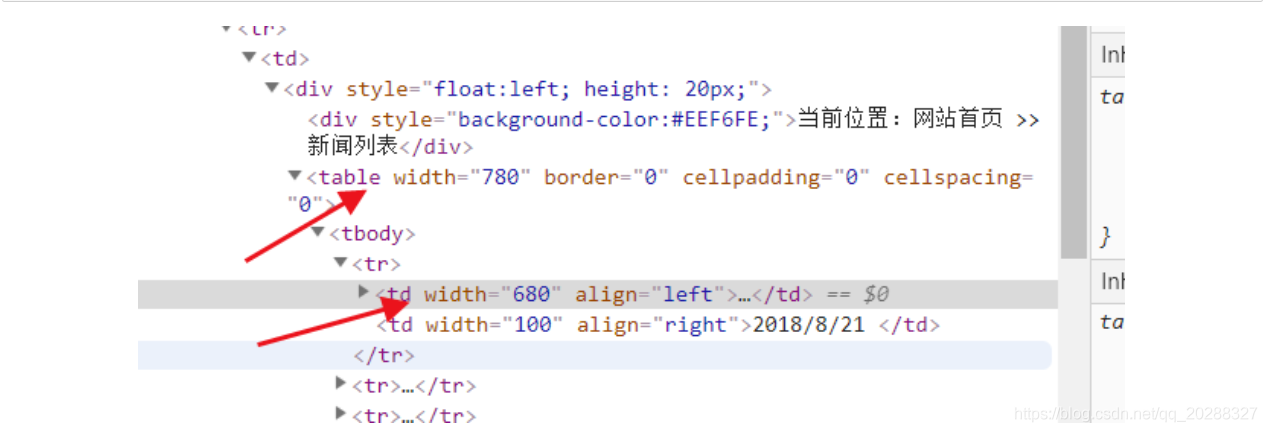
#通過頁面解析得到結構數據進行處理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find('table',width='780')
# 解析
for i in lptable.find_all("td",width="680"):
title = i.b.strong.a.text
]
# href = i.find('a')['href']
date = href.split("/")[4]
print (title,href,date)

4.Xpath 應用舉例
XPath 是一門在 XML 文檔中查找信息的語言。XPath 可用來在 XML 文檔中對元素和屬性進行遍歷。XPath 是 W3C XSLT 標準的主要元素,并且 XQuery 和 XPointer 都構建于 XPath 表達之上。
四種標簽的使用方法
- // 雙斜杠 定位根節點,會對全文進行掃描,在文檔中選取所有符合條件的內容,以列表的形式返回。
- / 單斜杠 尋找當前標簽路徑的下一層路徑標簽或者對當前路標簽內容進行操作
- /text() 獲取當前路徑下的文本內容
- /@xxxx 提取當前路徑下標簽的屬性值
- | 可選符 使用|可選取若干個路徑 如//p | //div 即在當前路徑下選取所有符合條件的p標簽和div標簽。
- . 點 用來選取當前節點
- … 雙點 選取當前節點的父節點
from lxml import etree
html="""
!DOCTYPE html>
html>
head lang="en">
title>test/title>
meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
/head>
body>
div id="content">
ul id="ul">
li>NO.1/li>
li>NO.2/li>
li>NO.3/li>
/ul>
ul id="ul2">
li>one/li>
li>two/li>
/ul>
/div>
div id="url">
a rel="external nofollow" title="crossgate">crossgate/a>
a rel="external nofollow" title="pinggu">pinggu/a>
/div>
/body>
/html>
"""
#這里使用id屬性來定位哪個div和ul被匹配 使用text()獲取文本內容
selector=etree.HTML(html)
content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
for i in content:
print (i)

#這里使用//從全文中定位符合條件的a標簽,使用“@標簽屬性”獲取a便簽的href屬性值
con=selector.xpath('//a/@href')
for i in con:
print (i)

#使用絕對路徑 #使用相對路徑定位 兩者效果是一樣的
con=selector.xpath('/html/body/div/a/@title')
print (len(con))
print (con[0],con[1])

三、動態網頁和靜態網頁的區分
來源百度:
靜態網頁的基本概述
靜態網頁的網址形式通常是以.htm、.html、.shtml、.xml等為后后綴的。靜態網頁,一般來說是最簡單的HTML網頁,服務器端和客戶端是一樣的,而且沒有腳本和小程序,所以它不能動。在HTML格式的網頁上,也可以出現各種動態的效果,如.GIF格式的動畫、FLASH、滾動字母等,這些“動態效果”只是視覺上的,與下面將要介紹的動態網頁是不同的概念。
靜態網頁的特點
- 靜態網頁每個網頁都有一個固定的URL,且網頁URL以.htm、.html、.shtml等常見形式為后綴,而不含有“?”。
- 網頁內容一經發布到網站服務器上,無論是否有用戶訪問,每個靜態網頁的內容都是保存在網站服務器上的,也就是說,靜態網頁是實實在在保存在服務器上的文件,每個網頁都是一個獨立的文件。
- 靜態網頁的內容相對穩定,因此容易被搜索引擎檢索。
- 靜態網頁沒有數據庫的支持,在網站制作和維護方面工作量較大,因此當網站信息量很大時完全依靠靜態網頁制作方式比較困難。
- 靜態網頁的交互性交叉,在功能方面有較大的限制。
動態網頁的基本概述
動態網頁是以.asp、.jsp、.php、.perl、.cgi等形式為后綴,并且在動態網頁網址中有一個標志性的符號——“?”。動態網頁與網頁上的各種動畫、滾動字幕等視覺上的“動態效果”沒有直接關系,動態網頁也可以是純文字內容的,也可以是包含各種動畫的內容,這些只是網頁具體內容的表現形式,無論網頁是否具有動態效果,采用動態網站技術生成的網頁都稱為動態網頁.動態網站也可以采用靜動結合的原則,適合采用動態網頁的地方用動態網頁,如果必要使用靜態網頁,則可以考慮用靜態網頁的方法來實現,在同一個網站上,動態網頁內容和靜態網頁內容同時存在也是很常見的事情。
動態網頁應該具有以下幾點特色:
- 交互性:即網頁會根據用戶的要求和選擇而動態改變和響應。例如訪問者在網頁填寫表單信息并提交,服務器經過處理將信息自動存儲到后臺數據庫中,并打開相應提示頁面。
- 自動更新:即無需手動操作,便會自動生成新的頁面,可以大大節省工作量。例如,在論壇中發布信息,后臺服務器將自動生成新的網頁。
- 隨機性:即當不問的時間、不問的人訪問同一網址時會產生不同的頁面效果。例如,登錄界面自動循環功能。
- 動態網頁中的“?”對搜索引擎檢索存在一定的問題,搜索引擎一般不可能從一個網站的數據庫中訪問全部網頁,或者出于技術方面的考慮,搜索蜘蛛不去抓取網址中“?”后面的內容,因此采用動態網頁的網站在進行搜索引擎推廣時需要做一定的技術處理才能適應搜索引擎的要求。
總結來說:頁面內容變了網址也會跟著變基本都是靜態網頁,反之是動態網頁。
四、動態網頁和靜態網頁的抓取
1.靜態網頁
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=1"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]

import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]

總結:上面2個url差別在最后一個數字,在原網頁上每點下一頁網址和內容同時變化,我們判斷:該網頁為靜態網頁。
2.動態網頁
import requests
from bs4 import BeautifulSoup
url = "http://news.cqcoal.com/blank/nl.jsp?tid=238"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text
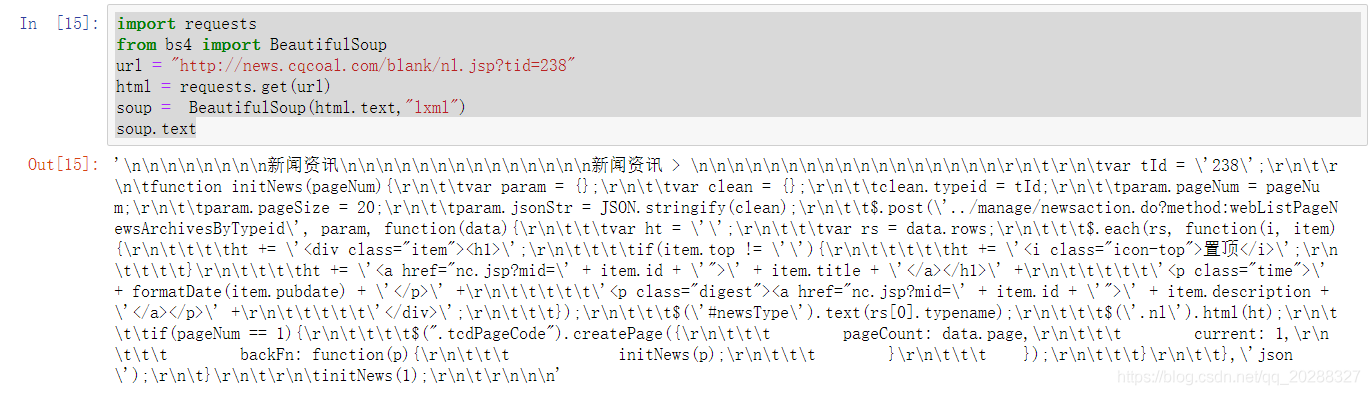
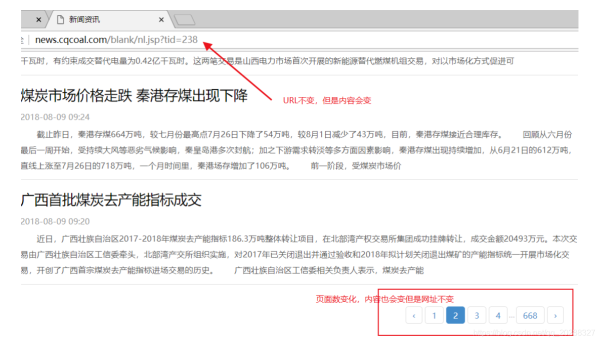
抓取該網頁看不到任何的信息證明是動態網頁,正確抓取方法如下。
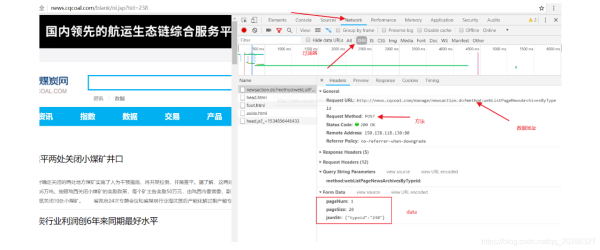
import urllib
import urllib.request
import requests
url = "http://news.cqcoal.com/manage/newsaction.do?method:webListPageNewsArchivesByTypeid"
post_param = {'pageNum':'1',\
'pageSize':'20',\
'jsonStr':'{"typeid":"238"}'}
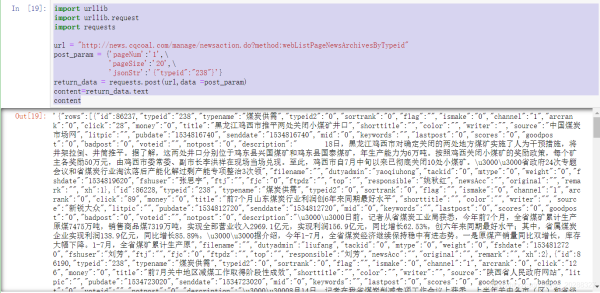
return_data = requests.post(url,data =post_param)
content=return_data.text
content
到此這篇關于教你如何使用Python快速爬取需要的數據的文章就介紹到這了,更多相關Python爬取數據內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python爬取豆瓣電影TOP250數據
- python爬取鏈家二手房的數據
- Python手拉手教你爬取貝殼房源數據的實戰教程
- Python數據分析之Python和Selenium爬取BOSS直聘崗位
- python爬蟲之爬取谷歌趨勢數據
- python selenium實現智聯招聘數據爬取
- python爬蟲之教你如何爬取地理數據
- Python爬蟲爬取全球疫情數據并存儲到mysql數據庫的步驟
- Python爬取騰訊疫情實時數據并存儲到mysql數據庫的示例代碼
- Python爬蟲之自動爬取某車之家各車銷售數據
