scrapy 框架結構
思考
- scrapy 為什么是框架而不是庫?
- scrapy是如何工作的?
項目結構
在開始爬取之前,必須創建一個新的Scrapy項目。進入您打算存儲代碼的目錄中,運行下列命令:
注意:創建項目時,會在當前目錄下新建爬蟲項目的目錄。
這些文件分別是:
- scrapy.cfg:項目的配置文件
- quotes/:該項目的python模塊。之后您將在此加入代碼
- quotes/items.py:項目中的item文件
- quotes/middlewares.py:爬蟲中間件、下載中間件(處理請求體與響應體)
- quotes/pipelines.py:項目中的pipelines文件
- quotes/settings.py:項目的設置文件
- quotes/spiders/:放置spider代碼的目錄
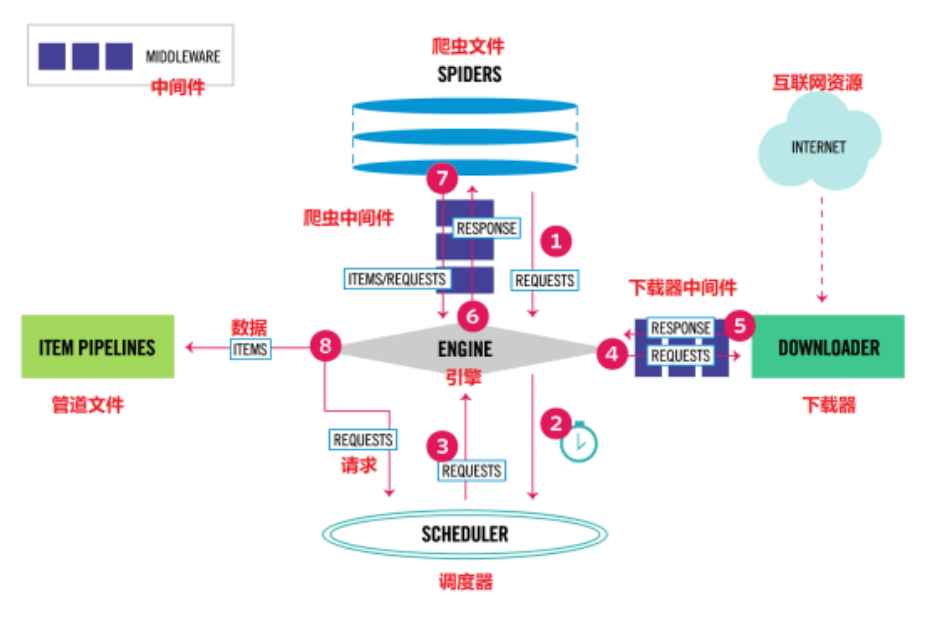
Scrapy原理圖

各個組件的介紹
1.Engine。引擎,處理整個系統的數據流處理、觸發事務,是整個框架的核心。
2.ltem。項目,它定義了爬取結果的數據結構,爬取的數據會被賦值成該ltem對象。
3.Scheduler。調度器,接受引擎發過來的請求并將其加入隊列中,在引擎再次請求的時候將請求提供給引擎。
4.Downloader。下載器,下載網頁內容,并將網頁內容返回給蜘蛛。
5.Spiders。蜘蛛,其內定義了爬取的邏輯和網頁的解析規則,它主要負責解析響應并生成提結果和新的請求。
6.Item Pipeline。項目管道,負責處理由蜘蛛從網頁中抽取的項目,它的主要任務是清洗、驗證和存儲數據。
7.Downloader Middlewares。下載器中間件,位于引擎和下載器之間的鉤子框架,主要處理引擎與下載器之間的請求及響應。
8.Spider Middlewares。蜘蛛中間件,位于引擎和蜘蛛之間的鉤子框架,主要處理蜘蛛輸入的響應和輸出的結果及新的請求。
數據的流動
- Scrapy Engine(引擎):負責Spider、ltemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。
- Scheduler(調度器):負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。
- Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
- Spider(爬蟲)︰負責處理所有Responses,從中分析提取數據,獲取ltem字段需要的數據,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器),
- ltem Pipeline(管道):負責處理Spider中獲取到的ltem,并進行進行后期處理(詳細分析、過濾、存儲等)的地方.
- Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件。
- Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
到此這篇關于Python爬蟲基礎之簡單說一下scrapy的框架結構的文章就介紹到這了,更多相關scrapy的框架結構內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python爬蟲基礎講解之scrapy框架
- python爬蟲scrapy框架的梨視頻案例解析
- 簡述python Scrapy框架
- Python Scrapy框架第一個入門程序示例
