開發工具
**Python版本:**3.6.4
相關模塊:
scikit-learn模塊;
jieba模塊;
numpy模塊;
以及一些Python自帶的模塊。
環境搭建
安裝Python并添加到環境變量,pip安裝需要的相關模塊即可。
逐步實現
(1)劃分數據集
網上用于垃圾郵件識別的數據集大多是英文郵件,所以為了表示誠意,我花了點時間找了一份中文郵件的數據集。數據集劃分如下:
訓練數據集:
7063封正常郵件(data/normal文件夾下);
7775封垃圾郵件(data/spam文件夾下)。
測試數據集:
共392封郵件(data/test文件夾下)。
(2)創建詞典
數據集里的郵件內容一般是這樣的:

首先,我們利用正則表達式過濾掉非中文字符,然后再用jieba分詞庫對語句進行分詞,并清除一些停用詞,最后再利用上述結果創建詞典,詞典格式為:
{“詞1”: 詞1詞頻, “詞2”: 詞2詞頻…}
這些內容的具體實現均在**“utils.py”**文件中體現,在主程序中(train.py)調用即可:

最終結果保存在**“results.pkl”**文件內。
大功告成了么?當然沒有!!!
現在的詞典里有52113個詞,顯然太多了,有些詞只出現了一兩次,后續特征提取的時候一直空占著一個維度顯然是不明智的做法。因此,我們只保留詞頻最高的4000個詞作為最終創建的詞典:

最終結果保存在**“wordsDict.pkl”**文件內。
(3)特征提取
詞典準備好之后,我們就可以把每封信的內容轉換為詞向量了,顯然其維度為4000,每一維代表一個高頻詞在該封信中出現的頻率,最后,我們將這些詞向量合并為一個大的特征向量矩陣,其大小為:
(7063+7775)×4000
即前7063行為正常郵件的特征向量,其余為垃圾郵件的特征向量。
上述內容的具體實現仍然在**“utils.py”**文件中體現,在主程序中調用如下:
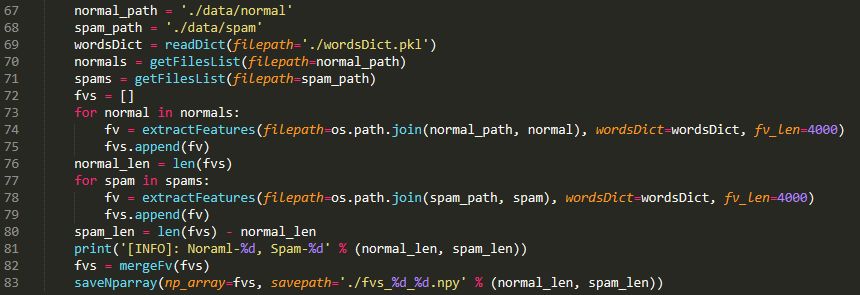
最終結果保存在**“fvs_%d_%d.npy”**文件內,其中第一個格式符代表正常郵件的數量,第二個格式符代表垃圾郵件的數量。
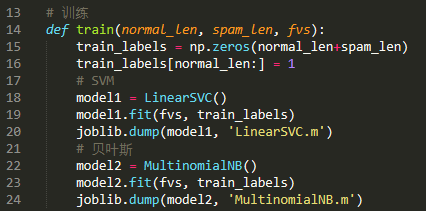
(4)訓練分類器
我們使用scikit-learn機器學習庫來訓練分類器,模型選擇樸素貝葉斯分類器和SVM(支持向量機):
(5)性能測試
利用測試數據集對模型進行測試:
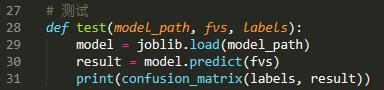
結果如下:


可以發現兩個模型的性能是差不多的(SVM略勝于樸素貝葉斯),但SVM更傾向于向垃圾郵件的判定。
到此這篇關于Python實現垃圾郵件的識別的文章就介紹到這了,更多相關Python識別垃圾郵件內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python實現自動化辦公郵件合并功能
- Python 發送SMTP郵件的簡單教程
- Python一行代碼實現自動發郵件功能
- Python基礎詳解之郵件處理
- Python 調用API發送郵件
- Python基于SMTP發送郵件的方法
- python基于SMTP發送QQ郵件
- python 自動監控最新郵件并讀取的操作
- python實現發送郵件
- python 實現網易郵箱郵件閱讀和刪除的輔助小腳本
- python如何發送帶有附件、正文為HTML的郵件
- python使用Windows的wmic命令監控文件運行狀況,如有異常發送郵件報警
- 用python監控服務器的cpu,磁盤空間,內存,超過郵件報警
- python郵件中附加文字、html、圖片、附件實現方法
- Python用20行代碼實現完整郵件功能
