目錄
- 一、總結
- 二、全面加速(pypy)
- 二、減少文件的打開即with的調用
- 三、if判斷靠前
一、總結
1、使用pypy
2、減少函數化調用
3、減少文件的打開即with的調用,將這一調用放在for循環前面,然后傳遞至后面需要用到的地方
4、if函數判斷條件多的盡量在前面
全面加速(pypy)
二、全面加速(pypy)
將python換為pypy,在純python代碼下,pypy的兼容性就不影響使用了,因為一些純python的代碼常常會用pypy進行一下加速
測試代碼,for循環10000000次
start = time.time()
for i in range(10000000):
print(i,end="\r")
end = time.time()
print(f"耗費時間{end-start}秒>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
pypy的耗時為:
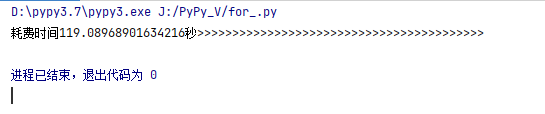
而python耗時為
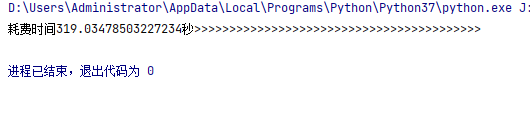
大致三倍,但是循環越多估計越快,據說有6倍左右
二、減少文件的打開即with的調用
原代碼的with在調用函數內,即每次調用函數都要打開并關閉文件,造成大量耗時
def BMES(word,tag):
with open(r"J:\PyCharm項目\學習進行中\NLP教程\NLP教程\數據集\詞性標注\nature2ner.txt","a+",encoding="utf-8")as f_:
if len(word) == 1:
"""單字"""
f_.write(word + " " + f"S-{tag.upper()}" + "\n")
else:
"""多字"""
for index, word_ in enumerate(word):
if index == 0:
f_.write(word_ + " " + f"B-{tag.upper()}" + "\n")
elif 0 index len(word) - 1:
f_.write(word_ + " " + f"M-{tag.upper()}" + "\n")
else:
f_.write(word_ + " " + f"E-{tag.upper()}" + "\n")
#后續在多個if-elif-else中調用
耗時為
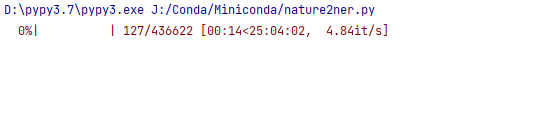
tqdm預估時間在15~25個小時左右跳動
將with放在循環前面
如
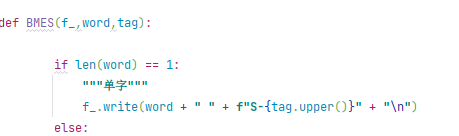
將with的內容作為f_傳遞進來

后的耗時為:
測試如下:
import os, warnings,time,tqdm
def txt(word):
with open("ceshi.txt","a+",encoding="utf-8")as f:
if len(str(word))=2:
word+=100
f.write(str(word)+"\n")
elif 2len(str(word))=4:
word+=200
f.write(str(word)+"\n")
else:
f.write(str(word) + "\n")
if __name__=="__main__":
start = time.time()
for i in tqdm.tqdm(range(100000)):
txt(i)
end = time.time()
print(f"耗費時間{end-start}秒>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
耗時結果為:

將文件的打開即with的調用放在外面
import os, warnings,time,tqdm
def txt(f,word):
if len(str(word))=2:
word+=100
f.write(str(word)+"\n")
elif 2len(str(word))=4:
word+=200
f.write(str(word)+"\n")
else:
f.write(str(word) + "\n")
if __name__=="__main__":
start = time.time()
with open("ceshi.txt", "a+", encoding="utf-8")as f:
for i in tqdm.tqdm(range(100000)):
txt(f,i)
end = time.time()
print(f"耗費時間{end-start}秒>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
耗時為

結論:快了119倍,而實際加速遠遠大于這個倍數
三、if判斷靠前
如:
if tag in ["nts", "nto", "ntc", "ntcb", "ntcf", "ntch", "nth", "ntu", "nt"]:
BMES(f_,i2, tag="ORG")
elif tag in ["nb", "nba", "nbc", "nbp", "nf", "nm", "nmc", "nhm", "nh"]:
BMES(f_,i2, tag="OBJ")
elif tag in ["nnd", "nnt", "nn"]:
BMES(f_,i2, tag="JOB")
elif tag in ["nr", "nrf"]:
BMES(f_,i2, tag="PER")
elif tag in ["t"]:
BMES(f_,i2, tag="TIME")
elif tag in ["ns", "nsf"]:
BMES(f_,i2, tag="LOC")
else:
for i3 in list(i2):
f_.write(i3 + " " + f"O" + "\n")
滿足條件的可以先跳出判斷
到此這篇關于python運行加速的幾種方式的文章就介紹到這了,更多相關python運行加速的幾種方式內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python入門課程第二講之怎么運行Python
- Python運行第一個PySide2的窗體程序
- Python命令行運行文件的實例方法
- python腳本打包后無法運行exe文件的解決方案
- 沒有安裝Python的電腦運行Python代碼教程
