目錄
- 一、HDFS的優缺點
- 二、HDFS的架構
- 三、HDFS數據存儲單元(block)
- 四、HDFS設計思想
- 五、NameNode(NN)、 SencondryNameNode (SNN)、DataNode(DN)
- 1.NameNode (NN) 的工作
- 2.SecondryNameNode(SNN) 的工作
- 3.DataNode (DN)
- 六、HDFS的寫流程和讀流程
- 七、HDFS文件權限
- 八、安全模式
HDFS是Hadoop Distribute File System 的簡稱,也就是Hadoop的一個分布式文件系統。
一、HDFS的優缺點
1.HDFS優點:
a.高容錯性
.數據保存多個副本
.數據丟的失后自動恢復
b.適合批處理
.移動計算而非移動數據
.數據位置暴露給計算框架
c.適合大數據處理
.GB、TB、甚至PB級的數據處理
.百萬規模以上的文件數據
.10000+的節點
d.可構建在廉價的機器上
.通過多副本存儲,提高可靠性
.提供了容錯和恢復機制
2.HDFS缺點
a.低延遲數據訪問處理較弱
.毫秒級別的訪問響應較慢
.低延遲和高吞吐率的請求處理較弱
b.大量小文件存取處理較弱
.會占用大量NameNode的內存
.尋道時間超過讀取時間
c.并發寫入、文件隨機修改
.一個文件僅有一個寫者
.僅支持Append寫入
二、HDFS的架構
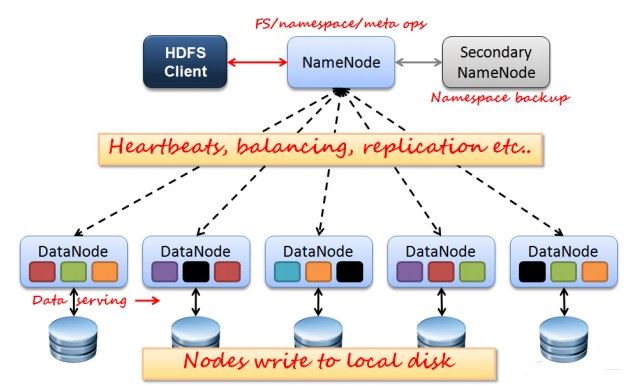
如上圖所示,HDFS也是按照Master和Slave的結構。分NameNode、SecondaryNameNode、DataNode這幾個角色。
NameNode:是Master節點,是大領導。管理數據塊映射;處理客戶端的讀寫請求;配置副本策略;管理HDFS的名稱空間;
SecondaryNameNode:是一個小弟,分擔大哥namenode的一部分工作量;是NameNode的冷備份;合并fsimage和fsedits然后再發給namenode。
DataNode:Slave節點,奴隸,干活的。負責存儲client發來的數據塊block;執行數據塊的讀寫操作。
熱備份:b是a的熱備份,如果a壞掉。那么b馬上運行代替a的工作。
冷備份:b是a的冷備份,如果a壞掉。那么b不能馬上代替a工作。但是b上存儲a的一些信息,減少a壞掉之后的損失。
fsimage:元數據鏡像文件(文件系統的目錄樹。)
edits:元數據的操作日志(針對文件系統做的修改操作記錄)
namenode內存中存儲的是=fsimage+edits。
SecondaryNameNode負責定時默認1小時,從namenode上,獲取fsimage和edits來進行合并,然后再發送給namenode。減少namenode的工作量。
三、HDFS數據存儲單元(block)
1.文件被切割成固大小的數據塊
a.默認數據塊大小是64MB,數據塊大小可配置
b.若數據塊大小不到64MB,則單獨成一個數據塊
2.一個文件存儲方式
a.按大小切割成若干個block,存儲在不同的節點上
b.每個block默認存三個副本
block大小和副本數由Client上傳文件的時候設置,文件上傳成功以后,副本數可以變更,但是Block 大小不可變。
四、HDFS設計思想

一個50G的文件上傳到HDFS上,首先該文件被切割成了若干個64MB的block,block1在node1,node2,node3上存儲了3(默認3個,可以設置)個副本,block2在node2,node3,node4上存儲了3個副 本block3....直到所有的block都存儲3個副本;
五、NameNode(NN)、 SencondryNameNode (SNN)、DataNode(DN)
1.NameNode (NN) 的工作
a.接受客戶端的讀寫服務
b.保存metadata的信息,包括:文件的owership和permissions、文件包含哪些block、block保存在哪些DataNode節點上(在啟動時由DataNode上報)
c.NameNode 的metadata信息會在啟動后加載到內存中
.metadata信息在磁盤上存儲的文件為“fsimage”
.Block的位置信息不保存在fsimage中(由DataNode上報)
.edits中保存對metadata的操作日志
2.SecondryNameNode(SNN) 的工作
a.它不是NN的備份(但可以做NN的部分備份的工作),它的主要工作是幫助NN合并edits log 減少NN的啟動時間
b.SNN合并時機
.根據配置文件設置的時間間隔fs.checkpoint.period 默認3600秒
.根據配置文件設置的edits log的大小 fs.checpoint.size 默認的edits log 大小為64MB
c.SNN合并流程
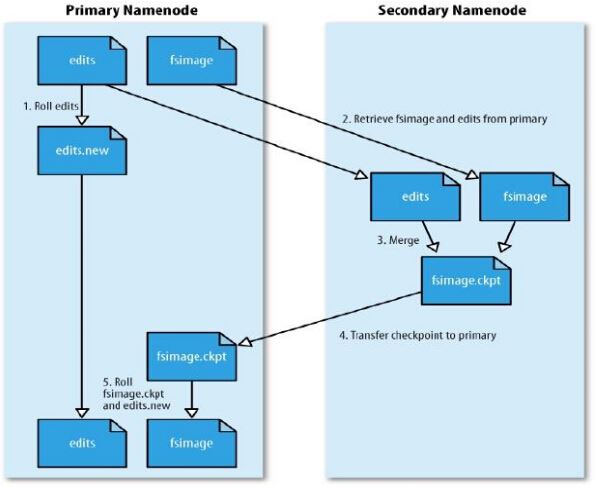
1>NN 創建一個新的edits log 來接替老的 edits 的工作
2>NN 將fsimage 和 舊的edits 拷備到 SNN上
3>SNN上進行合并操作,產生一個新的fsimage
4>將新的fsimage 復制一份到NN上
5>使用新的fsimage 和 新的edits log
3.DataNode (DN)
a.存儲數塊(block)
b.啟動DN線程時,DN會自動向NN匯報Block的信息
c.NN向DN發送心跳檢測,與其DN保持聯系(3秒一次) 如果NN 連續10分鐘沒有收到DN的心跳,則認為該DN已經lost,并從其他DN中備份一份該DN上的所有block
d.block的放置策略
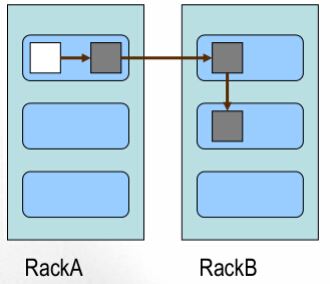
.第一個副本,放置在上傳文件的DN上,如果是集群外提交,則隨便選擇一臺磁盤、內存、CPU不太忙的節點存儲
.第二個副本,放置在與第一個副本不同機架上的節點上
.第三個副本,放置在與第二個副本相同機架上的相鄰的節點上
.更多副本隨機放置
六、HDFS的寫流程和讀流程
1.HDFS寫流程
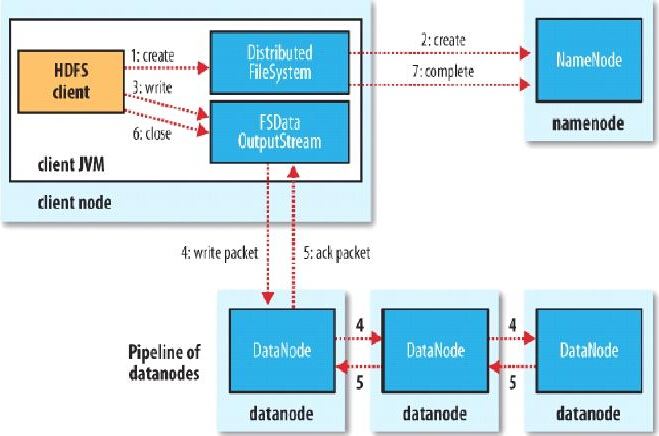
例:
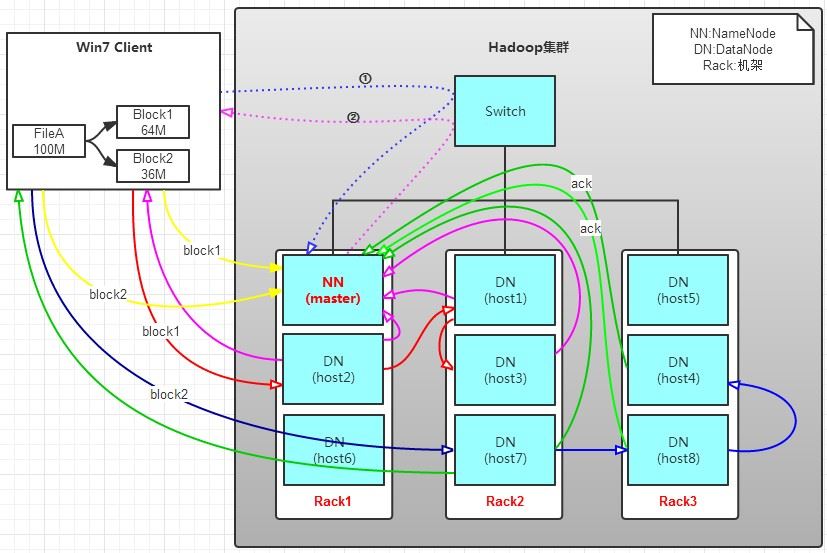
有一個文件FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按默認配置。
HDFS分布在三個機架上Rack1,Rack2,Rack3。
a.Client將FileA按64M分塊。分成兩塊,block1和Block2;
b.Client向nameNode發送寫數據請求,如圖藍色虛線①------>。
c.NameNode節點,記錄block信息。并返回可用的DataNode,如粉色虛線②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d.client向DataNode發送block1;發送過程是以流式寫入。
1>將64M的block1按64k的package劃分;
2>然后將第一個package發送給host2;
3>host2接收完后,將第一個package發送給host1,同時client想host2發送第二個package;
4>host1接收完第一個package后,發送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1發送完畢。
6>host2,host1,host3向NameNode,host2向Client發送通知,說“消息發送完了”。如圖粉紅顏色實線所示。
7>client收到host2發來的消息后,向namenode發送消息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8>發送完block1后,再向host7,host8,host4發送block2,如圖藍色實線所示。
9>發送完block2后,host7,host8,host4向NameNode,host7向Client發送通知,如圖淺綠色實線所示。
10>client向NameNode發送消息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以了解到:
①寫1T文件,我們需要3T的存儲,3T的網絡流量貸款。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行保存通信,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的數據,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關系,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關系;其他機架上,也有備份。
2.讀流程
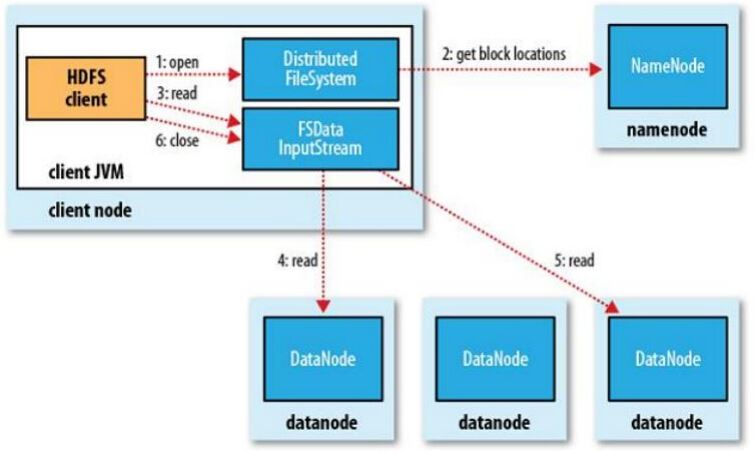
例:
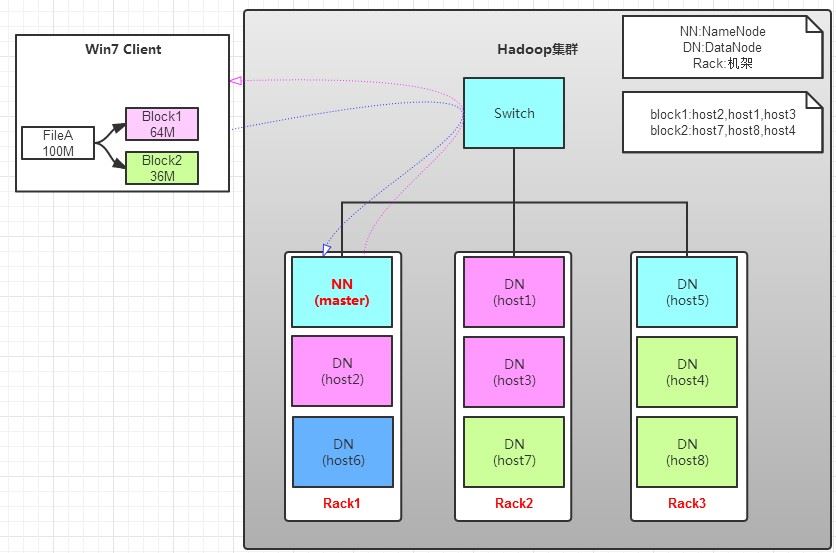
讀操作就簡單一些了,如圖所示,client要從datanode上,讀取FileA。而FileA由block1和block2組成。
那么,讀操作流程為:
a.client向namenode發送讀請求。
b.namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c.block的位置是有先后順序的,先讀block1,再讀block2。而且block1去host2上讀取;然后block2,去host7上讀取;
七、HDFS文件權限
1.與linux系統文件權限類似
r:read w:write x:execute 權限x對于文件忽略,對于文件夾表示是否允許訪問
2.如果linux系統用戶zhangsan使用hadoop命令創建一個文件 ,那么該文件在HDFS中的所有者就是zhangsan。
3.HDFS權限的目:阻止好人做錯事,而不是阻止壞人做壞事;例:只要是zhangsan上傳的文件,那HDFS就認為這個文件屬于張三,當下次過來操作的還是zhangsan那就可以操作,而不需要密碼驗證之類的操作。
八、安全模式
在NameNode啟動以后會一段時間是處于安全模式,在安全模式下只可查看不能修進行其他操作,因為在安全模式下NN和DN需要做很多工作;
1.NN 啟動的時候首先需要將fsimage 載入內存,并執行編輯日志中的各項操作。
2.一旦在文件系統中建立了一個新的元數據的映射,則創建一個新的fsimage 文件(與SNN配合)和一個空的edits文件
3.安全模式下的NameNode,對客戶端是只讀的(顯示文件目錄、內容等 ,其他的刪除、修改、重命名操作都會失敗)
4.在安全模式下,NameNode會收集來自DataNode匯報的block的信息,如果DN匯報的block的最副本數大于設置的最小副本數,則會認為是“安全”的。
如果有block的副本數沒有達到設置的最小副本數,則該block會被復制直到達到設置的最小副本數為止。
總結
以上所述是小編給大家介紹的Hadoop 分布式存儲系統 HDFS的實例詳解,希望對大家有所幫助,如果大家有任何疑問歡迎給我留言,小編會及時回復大家的!
您可能感興趣的文章:- Hadoop源碼分析三啟動及腳本剖析
- Hadoop源碼分析二安裝配置過程詳解
- Python API 操作Hadoop hdfs詳解
- Hadoop源碼分析五hdfs架構原理剖析
