首先需要注意的是,本文即將提到的 Druid,并非阿里巴巴的 Druid 數(shù)據庫連接池,而是另一個大數(shù)據場景下的解決方案:Apache Druid。
Apache Druid 是一個用于大數(shù)據實時查詢和分析的高容錯、高性能開源分布式時序數(shù)據庫系統(tǒng),旨在快速處理大規(guī)模的數(shù)據,并能夠實現(xiàn)快速查詢和分析。尤其是當發(fā)生代碼部署、機器故障以及其他產品系統(tǒng)遇到宕機等情況時,Druid 仍能夠保持 100% 正常運行。創(chuàng)建 Druid 的最初意圖主要是為了解決查詢延遲問題,當時試圖使用 Hadoop 來實現(xiàn)交互式查詢分析,但是很難滿足實時分析的需要。而 Druid 提供了以交互方式訪問數(shù)據的能力,并權衡了查詢的靈活性和性能而采取了特殊的存儲格式。
目前 Druid 廣泛應用在國內外各個公司,比如阿里,滴滴,知乎,360,eBay,Hulu 等。
本文 作者 Mohan Garadi 披露了 eBay 如何使用 Druid 進行監(jiān)控的技術細節(jié)。
在 eBay 中,我們將監(jiān)控技術棧從傳統(tǒng)的本地架構轉換為基于 Druid 的實時監(jiān)控系統(tǒng)。在本文中,我們將討論如何過渡到新技術棧,以及它為我們帶來了什么好處。
eBay 每天要支撐數(shù)百萬用戶進行電子商務交易。隨著支持不同產品的各種應用所產生的數(shù)據爆炸式增長,用戶數(shù)量也在大幅增長。日志是應用程序的核心,用于決定應用程序執(zhí)行哪些操作。隨著應用程序大小的增長,日志變得很難進行可視化。我們還有一個集中式日志存儲來處理所有日志,要直接從日志中獲取有用的信息非常困難,而且從日志中實時獲取有用信息的想法也不可行。在 eBay 中,監(jiān)控團隊以不同的方式對問題進行可視化。解決問題的更好方法是:從日志中提取有用事件并通過數(shù)據管理處理這些事件。
事件的數(shù)量直接與根據當前系統(tǒng)的流量生成的日志數(shù)量相關。一些應用程序可能會生成數(shù)百到數(shù)千個事件,而其他應用程序可能會生成數(shù)百萬個事件。我們的興趣是基于從日志中提取的事件來監(jiān)控各個應用程序的執(zhí)行情況,以及在系統(tǒng)中出現(xiàn)太多錯誤或異常行為時提醒用戶的能力。
應用程序事件包括錯誤狀態(tài)代碼、url 事務、命令執(zhí)行以及在不同主機上的應用程序項目的構建 ID 等。這些事件都有不同的目的。
應用程序開發(fā)人員和網站可靠性管理(Site reliability engineering,SRE)團隊都會對這些事件感興趣,因為他們可以實時監(jiān)控應用程序的性能。它們能夠將系統(tǒng)中發(fā)生的錯誤數(shù)量以可視化的形式呈現(xiàn),通過命令執(zhí)行對這些錯誤進行切片和切塊,并構建導致這些錯誤的程序,然后根據可能影響應用程序性能的錯誤閾值設置警報。
當應用程序開發(fā)團隊必須在生產中部署應用程序的新項目時,這些信息提供了關鍵的洞見。他們將能夠在一小部分主機上進行代碼的抽樣部署(sampled rollout),并可視化實時儀表盤,以確定新代碼在生成錯誤方面的行為,然后將實時數(shù)據與歷史數(shù)據進行比較,從而提供一定程度的可信度。
傳統(tǒng)架構
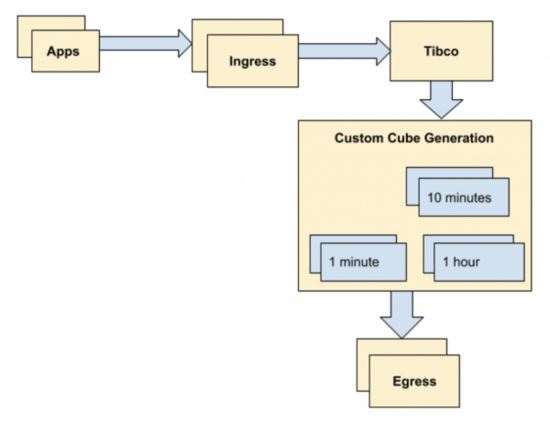
傳統(tǒng)架構是多年前設計的,當時整個站點每天生成的事件數(shù)量大約為 1000 萬次。這在當時是可擴展的,并且在未來幾年內也可以進行擴展。
隨著時間的推移,傳統(tǒng)架構暴露了一些缺點:
多維數(shù)據集生成是每個時間間隔的自定義編寫代碼。生成當前時間的數(shù)據通常需要幾分鐘,這對于實時監(jiān)控而言是不可接受的。而且這種延遲隨著數(shù)據量的增加而增加。
隨著數(shù)據量的增加,自定義多維數(shù)據生成的可擴展性隨時間的推移效果變得較差。
在維度基數(shù)非常高(幾十萬到幾百萬種組合)的情況下,生成速度緩慢或無法創(chuàng)建多維數(shù)據集。
新架構
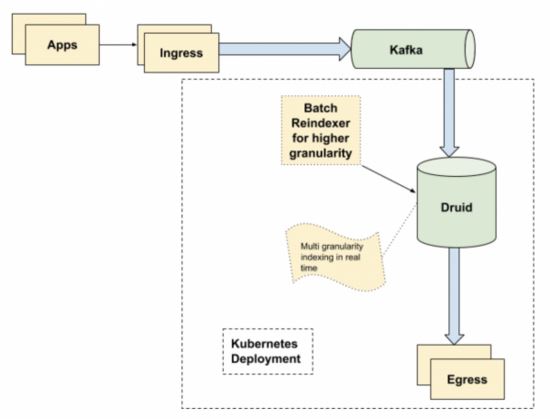
在新的架構中,已刪除 Tibco 依賴項,并將 Kafka 用做臨時保存信息以供使用的層。Tranquilty 用于使用來自 Kafka 的數(shù)據并輸入 Druid。
新架構的要點如下:
從時間生成到出口實現(xiàn)的最小端到端延遲(對于非常大的應用程序,最大不超過 10 秒)。
使用 Druid 處理多種粒度的數(shù)據,如 1 分鐘、1 刻鐘、1 小時等。重新索引 1 天間隔的數(shù)據。
Kubernetes 部署使我們在升級或維護時,能夠在幾分鐘之內刪除集群并重新創(chuàng)建集群。使用 100 個節(jié)點執(zhí)行滾動更新非常容易。
Druid 可有效地處理高基數(shù)數(shù)據,只要為索引任務提供足夠的可擴展性,即使是數(shù)以百萬計的緯度值,也可以使用 Druid 來處理,而不會產生任何額外的延遲,索引任務可在零停機時間內實現(xiàn)。
(Tibco 是一種用于數(shù)據傳輸?shù)钠髽I(yè)消息總線。Tranquilty 是 Druid-io 的一部分,它帶了一個將數(shù)據流發(fā)送到 Druid 的 API。)
事件處理
事件包括系統(tǒng)中發(fā)生的事情,這些事情從本質上來講是零星的。一些應用程序每天會生成一些事件,而其他應用程序在一分鐘內會生成數(shù)百萬個事件。不同類型的事件可根據它們的用途來生成。我們在此背景下討論監(jiān)控事件。
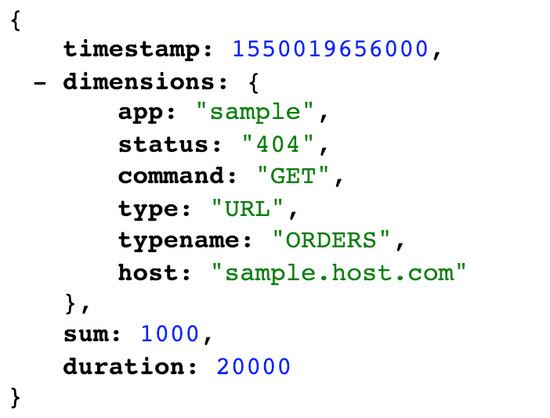
在我們的用例中,數(shù)據具有一個固定的維度鍵(11 維),一個時間戳和兩個要計算的度量:計數(shù)和延遲。計數(shù)是在特定時間戳收集數(shù)據時主機發(fā)生的事件數(shù)量。延遲表示所有事務的延遲總和。跨應用程序的數(shù)千個主機可能會生成數(shù)以百萬計的事件,每個事件可以包含不同的緯度值集。每個應用程序的每個維度的緯度值可以從十到幾千不等。
開發(fā)團隊和 SRE 團隊對上述事件很感興趣,以了解特定應用程序或多個應用程序在網站上發(fā)生錯誤的數(shù)量,這些錯誤可能會造成很大影響。將每分鐘幾百萬個事件實時收集到集中式存儲并對其進行處理,會帶來一系列事關準確性、速度、可靠性和彈性方面的挑戰(zhàn)。
擴展
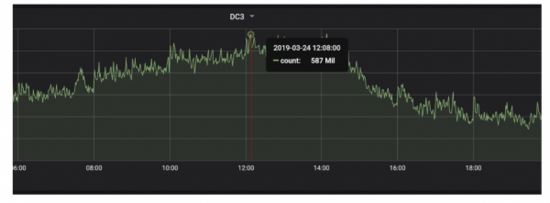
監(jiān)控事件在整個集群中,以每秒 800 萬個事件的速度生成,在高峰流量時平均為每秒 1000 萬個事件,這些來自 5000 多個應用程序。監(jiān)控事件需要跨多個維度進行切片和切塊,例如應用程序名稱、應用程序類型、操作名稱、錯誤狀態(tài)、運行應用程序的構建、主機等。所有數(shù)據都應以近實時服務級別協(xié)議進行匯總和提供。共有 11 個固定維度,所有維度的緯度值基數(shù)在 140 萬到 200 萬個唯一組合之間。
我們的 Druid 集群部署在多個可用區(qū)域,以實現(xiàn)高可用性,并保持每個數(shù)據中心的每個示例保留 2 個副本。這使得我們可以在 2 個數(shù)據中心共有 4 個副本可用。每個數(shù)據中心都有幾百個中間管理器、2 個統(tǒng)治 + 協(xié)調(Overlord+Coordinator)節(jié)點,15 個代理節(jié)點和 80 個歷史節(jié)點。
峰值數(shù)據流量如下圖所示。
出口設計
數(shù)據出口的設計目標是保持數(shù)據的高可用性。Druid 代理前面的一層被設計用于查詢 Druid 的數(shù)據,以確定每個數(shù)據中心的健康狀況。我們希望兩個數(shù)據中心的運行狀況始終保持在最佳狀態(tài),且高度可用。如果任何數(shù)據中心出現(xiàn)任何數(shù)據丟失的情況,出口會切換到數(shù)據質量更好的集群。
我們每分鐘從每個集群中獲取事件計數(shù),以確定兩個集群是否具有相似的數(shù)據(偏差小于集群之間的事件計數(shù)差異的 0.5%)。如果偏差過大,我們則選擇事件計數(shù)更好的集群。計算每分鐘進行一次,我們繼續(xù)更新集群的運行狀況,以確定能夠在一段時間內為數(shù)據提供服務的最佳集群。如果檢測到任何數(shù)據丟失,我們還會標記集群,這樣就不會有任何查詢進入有問題的集群的代理節(jié)點進行查詢。
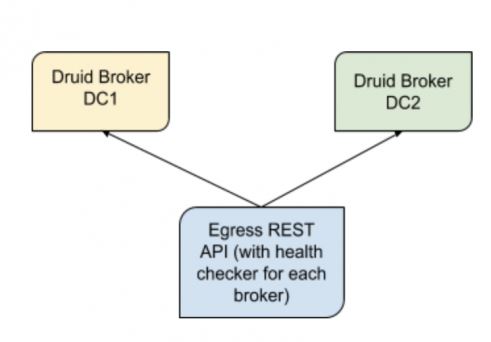
我們支持早期版本的 Druid 所支持的各種粒度(1 分鐘、1 刻鐘、1 小時、1 天),這取決于查詢數(shù)據的時間長度。這種粒度的選擇是自動進行的。在需要時,由于查詢的數(shù)據量很大,可以強制粒度以更長的時間段獲取更細粒度的數(shù)據,但要付出響應時間的代價。
結論
對于站點監(jiān)控和事件跟蹤而言,帶有需要實時或近實時聚合的高基數(shù)數(shù)據的用例,對于像 eBay 這樣的大型生態(tài)系統(tǒng)做出數(shù)據驅動的決策至關重要。像 Druid 這樣的分析存儲可以提供洞見的能力,從監(jiān)控的角度來說非常有價值,也很重要;很多團隊和開發(fā)人員都依賴維護 eBay 客戶系統(tǒng)的可用性和可靠性。
參考資料
本文中對 Druid 的所有引用都是指 Druid 開源版本,請參考以下鏈接:
http://druid.io/
https://github.com/apache/incubator-druid/
總結
以上所述是小編給大家介紹的eBay 打造基于 Apache Druid 的大數(shù)據實時監(jiān)控系統(tǒng),希望對大家有所幫助,如果大家有任何疑問歡迎給我留言小編會及時回復大家的!
您可能感興趣的文章:- Android實現(xiàn)與Apache Tomcat服務器數(shù)據交互(MySql數(shù)據庫)
- Linux+php+apache+oracle環(huán)境搭建之CentOS下安裝Oracle數(shù)據庫
- 建立Apache+PHP+MySQL數(shù)據庫驅動的動態(tài)網站
- 使用 Apache Superset 可視化 ClickHouse 數(shù)據的兩種方法
