背景補充:日本網民一直都有在電視節目播出的同時�����,在網絡平臺上吐槽或跟隨片中角色喊出臺詞的習慣�����,被稱作“實況”行為。宮崎駿監督的名作動畫《天空之城》于2013年8月2日晚在NTV電視臺迎來14次電視重播��。當劇情發展到男女主角巴魯和希達共同念出毀滅之咒“Blase”時�����,眾多網友也在推特上同時發出這條推特��,創造了每秒推特發送數量的新紀錄。
根據推特日本官方帳號�����,當地時間8月2日晚11時21分50秒��,因為“Blase祭”的影響�,推特發送峰值達到了143,199次/秒���。這一數字高于此前推特發送峰值的最高紀錄�����,2013年日本時區新年時的33,388次/秒。更高于拉登之死(5106次/秒)、東日本大地震(5530次/秒)、美國流行天后碧昂斯宣布懷孕(8868次/秒)����。
下圖是峰值發生的鄰近時間段的訪問頻率圖����,Twitter通常每天的推文數是 5 億條���,平均下來每秒大概產生5700條���。這個峰值大概是穩定狀態下訪問量的25倍�����!
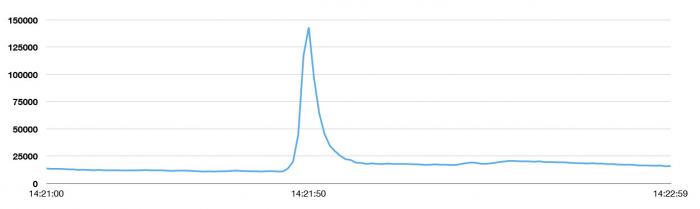
在這個峰值期間���,用戶并沒有感覺到暫時性的功能異常�����。無論世界上發生了什么,Twitter始終在你身邊,這是Twitter的目標之一。
“新的Tweets峰值誕生:143,199次Tweets每秒����。通常情況:5億次每天����;平均值5700Tweets每秒”
這個目標在3年前還是遙不可及的,2010年世界杯直接把Twitter變成了全球即時溝通的中心。每一次射門���、罰球�����、黃牌或者紅牌���,用戶都在發推文��,這反復地消耗著系統帶寬,從而使其在短時間內無法訪問。工程師們在這期間徹夜工作����,拼命想找到并實現一種方法可以把整個系統的負載提升一個量級�����。不幸的是,這些性能的提升很快被Twitter用戶的快速增長所淹沒,工程師們已經開始感到黔驢技窮了�。
經歷了那次慘痛的經歷�,Twitter決定要回首反思�。那時Twitter決定了要重新設計Twitter,讓它能搞定持續增長的訪問負載��,并保證平穩運行��。從那開始Twitter做了很大努力����,來保證面臨世界各地發生的熱點事件時���,Twitter仍能提供穩定的服務����。Twitter現在已經能扛住諸如播放“天空之城”,舉辦超級碗�����,慶祝新年夜等重大事件帶來的訪問壓力�����。重新設計/架構,不但使系統在突發訪問峰值期間的穩定性得到了保證�����,還提供了一個可伸縮的平臺��,從而使新特性更容易構建���,其中包括不同設備間同步消息�����,使Tweets包含更豐富內容的Twitter卡,包含用戶和故事的富搜索體驗等等特性�����。其他更多的特性也即將呈現�。
開始重新架構
2010年世界杯塵埃落定,Twitter總覽了整個項目��,并有如下的發現:
Twitter正運行著世界上最大的Ruby on Rails集群���,Twitter非??焖俚耐七M系統的演進–在那時,大概200個工程師為此工作����,無論是新用戶數還是絕對負載都在爆炸式的增長,這個系統沒有倒下�。它還是一個統一的整體��,Twitter的所有工作都在其上運行,從管理純粹的數據庫,memcache連接��,站點的渲染,暴露共有API這些都集中在一個代碼庫上��。這不但增加了程序員搞清整個系統的難度���,也使管理和同步各個項目組變得更加困難���。
Twitter的存儲系統已經達到閾值–Twitter依賴的MySQL存儲系統是臨時切分的��,它只有一個單主節點��。這個系統在消化/處理快速涌現的tweets時會陷入麻煩,Twitter在運營時不得不不斷的增加新的數據庫��。Twitter的所有數據庫都處于讀寫的熱點中��。
Twitter面臨問題時��,只是一味的靠扔進更多的機器來扛住,并沒有用工程的方式來解決它–根據機器的配置�����,前端Ruby機器的每秒事務處理數遠沒有達到Twitter預定的能力���。從以往的經驗�,Twitter知道它應該能處理更多的事務。
最后,從軟件的角度看,Twitter發現自己被推到了一個”優化的角落“,在那Twitter以代碼的可讀性和可擴展性為代價來換取性能和效率的提升����。
結論是Twitter應該開啟一個新工程來重新審視Twitter的系統����。Twitter設立了三個目標來激勵自己�����。
Twitter一直都需要一個高屋建瓴的建構來確保性能/效率/可靠性,Twitter想要保證在正常情況下有較好的平均系統響應時間,同時也要考慮到異常峰值的情況���,這樣才能保證在任何時間都能提供一致的服務和用戶體驗。Twitter要把機器的需求量降低10倍,還要提高容錯性,把失敗進行隔離以避免更大范圍的服務中斷–這在機器數量快速增長的背景下尤為重要,因為機器數的快速增長也意味著單體機器故障的可能性在增加。系統中出現失敗是不可避免的�����,Twitter要做的是使整個系統處于可控的狀態���。
Twitter要劃清相關邏輯間的界限����,整個公司工作在一個的代碼庫上的方式把Twitter搞的很慘,所以Twitter開始嘗試以基于服務的松耦合的模式進行劃分模塊��。Twitter曾經的目標是鼓勵封裝和模塊化的最佳實踐����,但這次Twitter把這個觀點深入到了系統層次,而不是類/模塊或者包層����。
最重要的是要更快的啟動新特性�����。以小并自主放權的團隊模式展開工作,他們可以內部決策并發布改變給用戶,這是獨立于其他團隊的��。
針對上面的要求�,Twitter構建了原型來證明重新架構的思路��。Twitter并沒有嘗試所有的方面����,并且即使Twitter嘗試的方面在最后也可能并像計劃中那樣管用�。但是,Twitter已經能夠設定一些準則/工具/架構����,這些使Twitter到達了一個憧憬中的更靠譜的狀態��。
The JVM VS the Ruby VM
首先���,Twitter在三個維度上評估了前端服務節點:CPU�����,內存和網絡?���;赗uby的機器在CPU和內存方面遭遇瓶頸–但是Twitter并未處理預計中那么多的負載�,并且網絡帶寬也沒有接近飽和�。Twitter的Rails服務器在那時還不得不設計成單線程并且一次處理一個請求。每一個Rails主機跑在一定數量的Unicorn處理器上來提供主機層的并發,但此處的復制被轉變成了資源的浪費(這里譯者沒太理清�����,請高手矯正�����,我的理解是Rails服務在一臺機器上只能單線程跑���,這浪費了機器上多核的資源)。歸結到最后����,Rails服務器就只能提供200~300次請求每秒的服務����。
Twitter的負載總是增長的很快��,做個數學計算就會發現搞定不斷增長的需求將需要大量的機器��。
在那時,Twitter有著部署大規模JVM服務的經驗�,Twitter的搜索引擎是用Java寫的��,Twitter的流式API的基礎架構還有Twitter的社交圖譜系統Flock都是用Scala實現的。Twitter著迷于JVM提供的性能����。在Ruby虛擬機上達到Twitter要求的性能/可靠性/效率的目標不是很容易�����,所以Twitter著手開始寫運行在JVM上的代碼。Twitter評估了這帶來的好處����,在同樣的硬件上��,重寫Twitter的代碼能給Twitter帶來10倍的性能改進–現今,Twitter單臺服務器達到了每秒10000-20000次請求的處理能力���。
Twitter對JVM存在相當程度的信任,這是因為很多人都來自那些運營/調配著大規模JVM集群的公司�����。Twitter有信心使Twitter在JVM的世界實現巨變?��,F在Twitter不得不解耦Twitter的架構從而找出這些不同的服務如何協作/通訊�。
編程模型
在Twitter的Ruby系統中����,并行是在進程的層面上管理的:一個單個請求被放進某一進程的隊列中等待處理。這個進程在請求的處理期間將完全被占用。這增加了復雜性,這樣做實際上使Twitter變成一個單個服務依賴于其他服務的回復的架構����?;赗uby的進程是單線程的�,Twitter的響應時間對后臺系統的響應非常敏感,二者緊密關聯。Ruby提供了一些并發的選項��,但是那并沒有一個標準的方法去協調所有的選項��。JVM則在概念和實現中都灌輸了并發的支持��,這使Twitter可以真正的構建一個并發的編程平臺���。
針對并發提供單個/統一的方式已經被證明是有必要的���,這個需求在處理網絡請求是尤為突出。Twitter都知道��,實現并發的代碼(包括并發的網絡處理代碼)是個艱巨的任務��,它可以有多種實現方式�。事實上����,Twitter已經開始碰到這些問題了。當Twitter開始把系統解耦成服務時���,每一個團隊都或多或少的采用了不盡相同的方式�。例如,客戶端到服務的失效并沒有很好的交互:這是由于Twitter沒有一致的后臺抗壓機制使服務器返回某值給客戶端���,這導致了Twitter經歷了野牛群狂奔式的瘋狂請求�����,客戶端猛戳延遲的服務�。這些失效的區域警醒Twitter–擁有一個統一完備的客戶/服務器間的庫來包含連接池/失效策略/負載均衡是非常重要的���。為了把這個理念深入人心����,Twitter引入了”Futures and Finagle”協議�����。
現在����,Twitter不僅有了一致的做事手段�,Twitter還把系統需要的所有東西都包含進核心的庫里��,這樣Twitter開新項目時就會進展飛速。同時����,Twitter現在不需要過多的擔心每個系統是如何運行�����,從而可以把更多的經歷放到應用和服務的接口上。
獨立的系統
Twitter實施了架構上的重大改變���,把集成化的Ruby應用變成一個基于服務的架構��。Twitter集中力量創建了Tweet時間線和針對用戶的服務–這是Twitter的核心所在。這個改變帶給組織更加清晰的邊界和團隊級別的責任制與獨立性���。在Twitter古老的整體/集成化的世界�����,Twitter要么需要一個了解整個工程的大牛�����,要么是對某一個模塊或類清楚的代碼所有者����。
悲劇的是,代碼膨脹的太快了�����,找到了解所有模塊的大牛越來越難,然而實踐中����,僅僅依靠幾個對某一模塊/類清楚的代碼作者又不能搞定問題。Twitter的代碼庫變得越來越難以維護��,各個團隊常常要像考古一樣把老代碼翻出來研究才能搞清楚某一功能�����。不然����,Twitter就組織類似“捕鯨征程”的活動,耗費大量的人力來搞出大規模服務失效的原因���。往往一天結束,Twitter花費了大量的時間在這上面,而沒有精力來開發/發布新特性����,這讓Twitter感覺很糟。
Twitter的理念曾經并一直都是–一個基于服務的架構可以讓Twitter并行的開發系統–Twitter就網絡RPC接口達成一致,然后各自獨立的開發系統的內部實現–但��,這也意味著系統的內部邏輯是自耦合的����。如果Twitter需要針對Tweets進行改變,Twitter可以在某一個服務例如Tweets服務進行更改,然后這個更改會在整個架構中得到體現����。然而在實踐中,Twitter發現不是所有的組都在以同樣的方式規劃變更:例如一個在Tweet服務的變更要使Tweet的展現改變,那么它可能需要其他的服務先進行更新以適應這個變化�����。權衡利弊��,這種理念還是為Twitter贏得了更多的時間。
這個系統架構也反映了Twitter一直想要的方式,并且使Twitter的工程組織有效的運轉�。工程團隊建立了高度自耦合的小組并能夠獨立/快速的展開工作。這意味著Twitter傾向于讓項目組啟動運行自己的服務并調用后臺系統來完成任務。這實際也暗含了大量運營的工作。
存儲
即使Twitter把Twitter板結成一坨的系統拆開成服務,存儲仍然是一個巨大的瓶頸。Twitter在那時還把tweets存儲在一個單主的MySQL數據庫中���。Twitter采用了臨時數據存儲的策略,數據庫中的每一行是一個tweet,Twitter把tweet有序的存儲在數據庫中��,當一個庫滿了Twitter就新開一個庫然后重配軟件開始往新庫中添加數據��。這個策略為Twitter節省了一定的時間����,但是面對突發的高訪問量��,Twitter仍然一籌莫展�����,因為大量的數據需要被串行化到一個單個的主數據庫中以至于Twitter幾臺局部的數據庫會發生高強度的讀請求��。Twitter得為Tweet存儲設計一個不同的分區策略�����。
Twitter引入了Gizzard并把它應用到了tweets����,它可以創建分片并容錯的分布式數據庫。Twitter創造了T-Bird(沒懂啥意思,意思是Twitter的速度快起來了?)��。這樣����,Gizzard充當了MySQL集群的前端,每當一個tweet抵達系統����,Gizzard對其進行哈希計算,然后選擇一個適當的數據庫進行存儲�。當然,這意味著Twitter失去了依靠MySQL產生唯一ID的功能��。Snowflake很好的解決了上述問題。Snowflake使Twitter能夠創建一個幾乎可以保證全局唯一的ID����。Twitter依靠它產生新的tweet ID,作為代價,Twitter將沒有“把某數加1產生新ID”的功能�����。一旦Twitter得到一個IDTwitter靠Gizzard來存儲它��。假設Twitter的哈希算法足夠好���,從而Twitter的tweets是接近于均勻的分布于各個儲存的�����,Twitter就能夠實現用同樣數量的數據庫承載更多的數據。Twitter的讀請求同樣也接近平均的分布于整個分布式集群中�����,這也增加了Twitter的吞度量。
可觀察性和可統計性
把那坨脆弱的板結到一起的系統變成一個更健壯的/良好封裝的/但也蠻復雜的/基于服務的應用�。Twitter不得不搞出一些工具來使管理這頭野獸變得可能?��;诖蠹叶荚诳焖俚臉嫿ǜ鞣N服務���,Twitter需要一種可靠并簡單的方式來得到這些服務的運行情況的數據。數據為王是默認準則,Twitter需要是使獲取上述的數據變得非常容易。
當Twitter將要在一個快速增長的巨大系統上啟動越來越多的服務����,Twitter必須使這種工作變得輕松�。運行時系統組開發為大家開發了兩個工具:Viz和Zipkin。二者都暴露并集成到了Finagle�����,所以所有基于Finagle的服務都可以自動的獲取到它們。
stats.timeFuture("request_latency_ms") {
// dispatch to do work
}
上面的代碼就是一個服務生成統計報告給Via所需做的唯一事情。從那里�����,任何Viz用戶都可以寫一個查詢來生成針對一些有趣的數據的時間/圖表�,例如第50%和第99%的request_latency_ms�。
運行時配置和測試
最后,當Twitter把所有的好東西放一起時���,兩個看似無關的問題擺在面前:第一���,整個系統的啟動需要協調多個系列的不同的服務,Twitter沒有一個地方可以把Twitter這個量級的應用所需要的服務弄到一起���。Twitter已經不能依靠通過部署來把新特性展現給客戶�����,應用中的各個服務需要協調���。第二,Twitter已經變得太龐大����,在一個完全封閉的環境下測試整個系統變得越來越困難。相對而言����,Twitter測試自己孤立的系統是沒有問題的–所以Twitter需要一個辦法來測試大規模的迭代。Twitter接納了運行時配置��。
Twitter通過一個稱作Decider的系統整合所有的服務�。當有一個變更要上線,它允許Twitter只需簡單開啟一個開關就可以讓架構上的多個子系統都和這個改變進行幾乎即時的交互���。這意味著軟件和多個系統可以在團隊認為成熟的情況下產品化����,但其中的某一個特性不需要已經被激活�����。Decider還允許Twitter進行二進制或百分比的切換����,例如讓一個特性只針對x%的用戶開放。Twitter還可以先把完全未激活并完全安全的特性部署上線���,然后梯度的開啟/關閉�,知道Twitter有足夠的自信保證特性可以正確的運行并且系統可以負擔這個新的負荷��。所有這些努力都可以減輕Twitter進行團隊之間溝通協調的活動�����,取而代之Twitter可以在系統運行時做Twitter想要的定制/配置��。
