最近剛入職新公司��,發現數據庫設計有點小問題�����,數據庫字段很多沒有NOT NULL��,對于強迫癥晚期患者來說��,簡直難以忍受,因此有了這篇文章���。
基于目前大部分的開發現狀來說,我們都會把字段全部設置成NOT NULL并且給默認值的形式��。
- 通常��,對于默認值一般這樣設置:
- 整形���,我們一般使用0作為默認值�����。
- 字符串,默認空字符串
時間����,可以默認1970-01-01 08:00:01����,或者默認0000-00-00 00:00:00��,但是連接參數要添加zeroDateTimeBehavior=convertToNull��,建議的話還是不要用這種默認的時間格式比較好
但是,考慮下原因���,為什么要設置成NOT NULL?
來自高性能Mysql中有這樣一段話:
盡量避免NULL
很多表都包含可為NULL(空值)的列�����,即使應用程序并不需要保存NULL也是如此�,這是因為可為NULL是列的默認屬性���。通常情況下最好指定列為NOT NULL���,除非真的需要存儲NULL值�。
如果查詢中包含可為NULL的列,對MySql來說更難優化�,因為可為NULL的列使得索引�、索引統計和值比較都更復雜�����?��?蔀镹ULL的列會使用更多的存儲空間�����,在MySql里也需要特殊處理。當可為NULL的列被索引時,每個索引記錄需要一個額外的字節��,在MyISAM里甚至還可能導致固定大小的索引(例如只有一個整數列的索引)變成可變大小的索引����。
通常把可為NULL的列改為NOT NULL帶來的性能提升比較小,所以(調優時)沒有必要首先在現有schema中查找并修改掉這種情況��,除非確定這會導致問題��。但是�����,如果計劃在列上建索引��,就應該盡量避免設計成可為NULL的列��。
當然也有例外,例如值得一提的是,InnoDB使用單獨的位(bit)存儲NULL值,所以對于稀疏數據有很好的空間效率����。但這一點不適用于MyISAM���。
書中的描述說了幾個主要問題����,我這里暫且拋開MyISAM的問題不談,這里我針對InnoDB作為考量條件。
- 如果不設置NOT NULL的話,NULL是列的默認值,如果不是本身需要的話�,盡量就不要使用NULL
- 使用NULL帶來更多的問題����,比如索引����、索引統計、值計算更加復雜,如果使用索引�����,就要避免列設置成NULL
- 如果是索引列�,會帶來的存儲空間的問題,需要額外的特殊處理�,還會導致更多的存儲空間占用
- 對于稀疏數據又更好的空間效率���,稀疏數據指的是很多值為NULL��,只有少數行的列有非NULL值的情況
默認值
對于MySql而言,如果不主動設置為NOT NULL的話,那么插入數據的時候默認值就是NULL����。
NULL和NOT NULL使用的空值代表的含義是不一樣,NULL可以認為這一列的值是未知的���,空值則可以認為我們知道這個值,只不過他是空的而已����。
舉個例子�����,一張表中的某一條name字段是NULL,我們可以認為不知道名字是什么����,反之如果是空字符串則可以認為我們知道沒有名字���,他就是一個空值�����。
而對于大多數程序的情況而言,沒有什么特殊需要非要字段要NULL的吧��,NULL值反而會對程序造成比如空指針的問題����。
對于現狀大部分使用MyBatis的情況來說,我建議使用默認生成的insertSelective方法或者純手動寫插入方法��,可以避免新增NOT NULL字段導致的默認值不生效或者插入報錯的問題�。
值計算
聚合函數不準確
對于NULL值的列,使用聚合函數的時候會忽略NULL值����。
現在我們有一張表,name字段默認是NULL�,此時對name進行count得出的結果是1�����,這個是錯誤的。
count(*)是對表中的行數進行統計����,count(name)則是對表中非NULL的列進行統計�����。

=失效
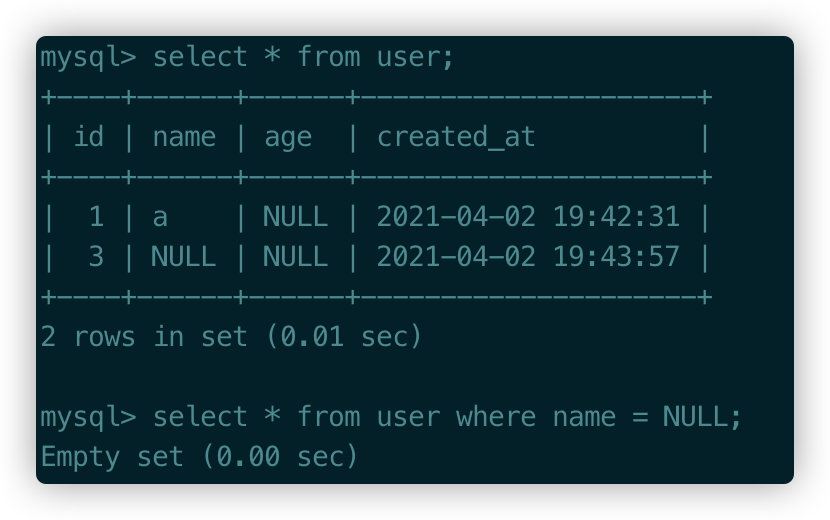
對于NULL值的列,是不能使用=表達式進行判斷的,下面對name的查詢是不成立的��,必須使用is NULL。
與其他值運算
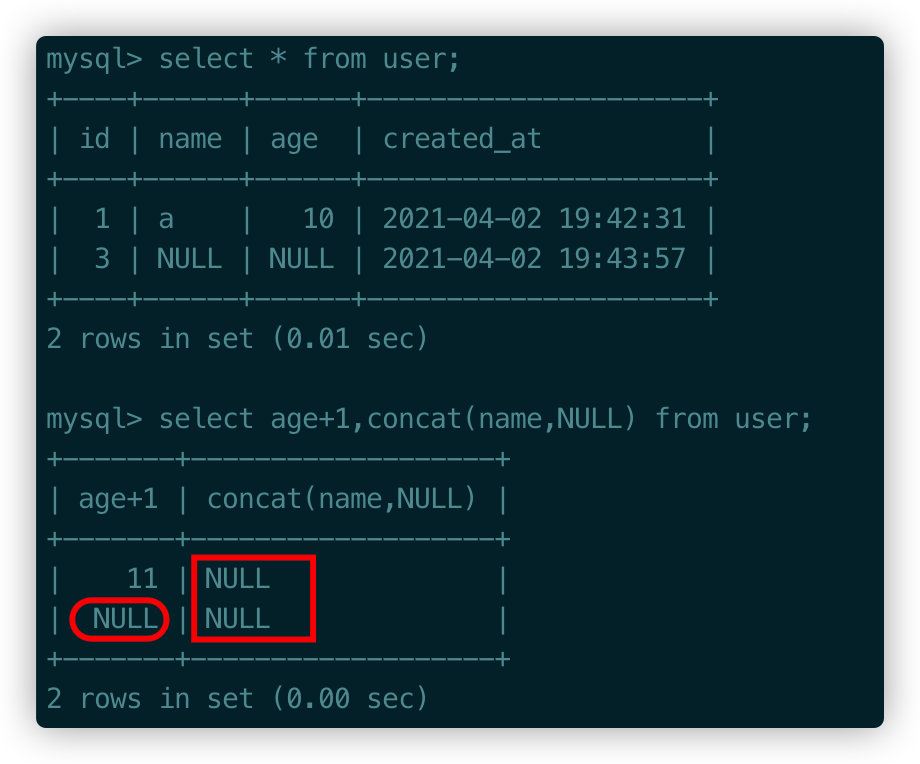
NULL和其他任何值進行運算都是NULL���,包括表達式的值也是NULL。
user表第二條記錄age是NULL���,所以+1之后還是NULL,name是NULL���,進行concat運算之后結果還是NULL。
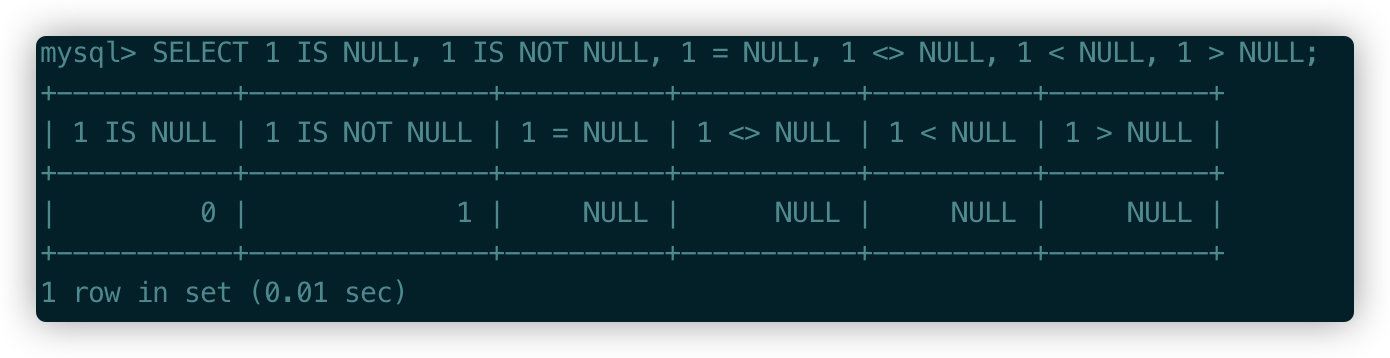
可以再看下下面的例子��,任何和NULL進行運算的話得出的結果都會是NULL����,想象下你設計的某個字段如果是NULL還不小心進行各種運算,最后得出的結果����。��。。
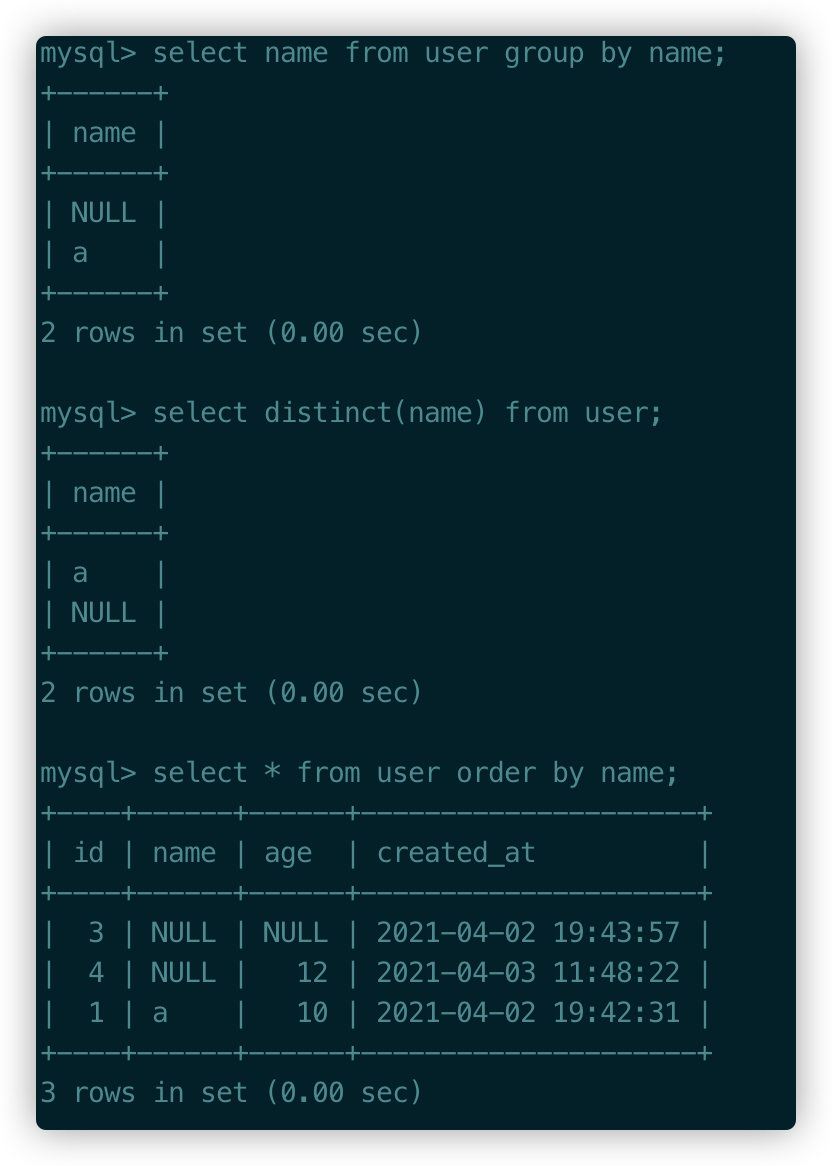
distinct��、group by����、order by
對于distinct和group by來說�����,所有的NULL值都會被視為相等��,對于order by來說升序NULL會排在最前
其他問題
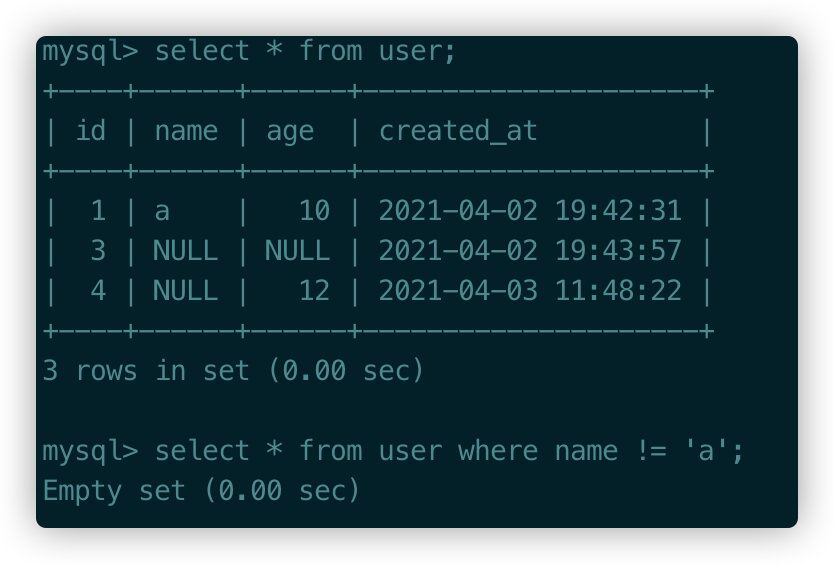
表中只有一條有名字的記錄,此時查詢名字!=a預期的結果應該是想查出來剩余的兩條記錄,會發現與預期結果不匹配����。
索引問題
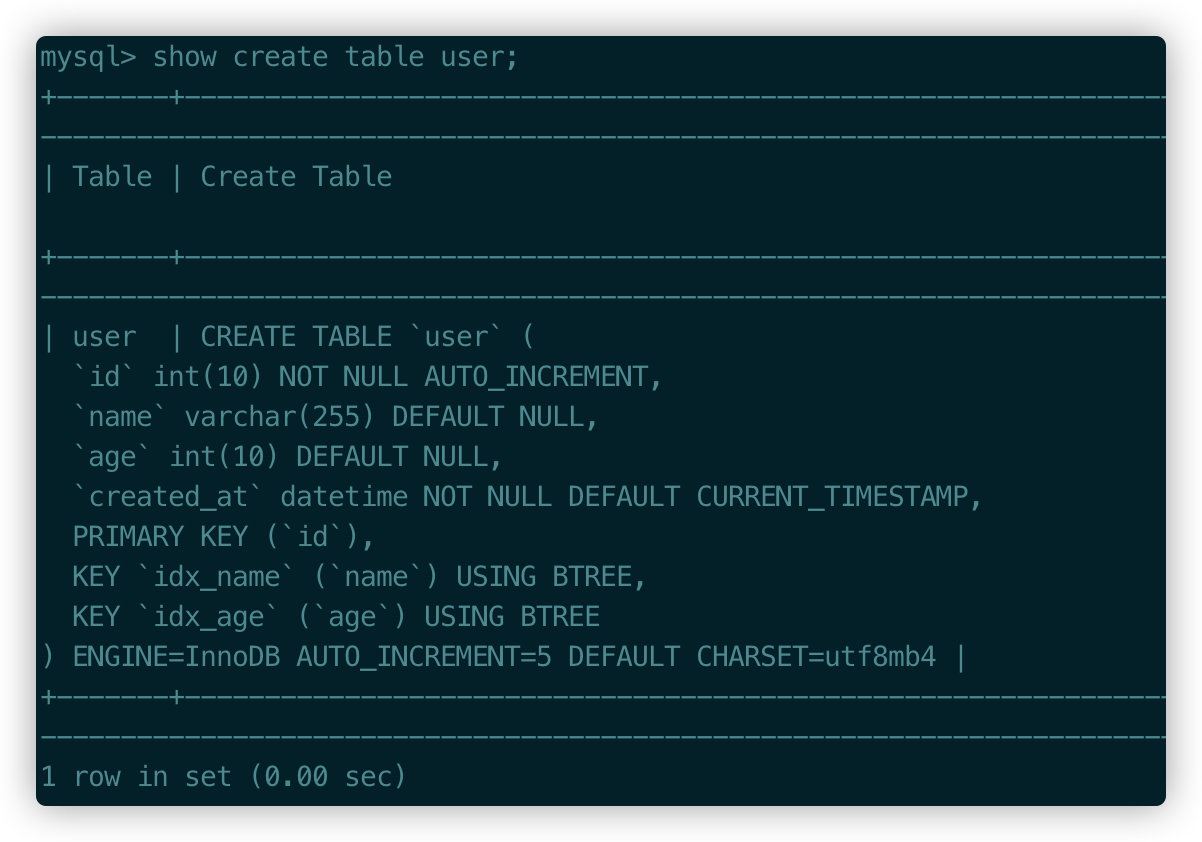
為了驗證NULL字段對索引的影響���,分別對name 和age添加索引�。
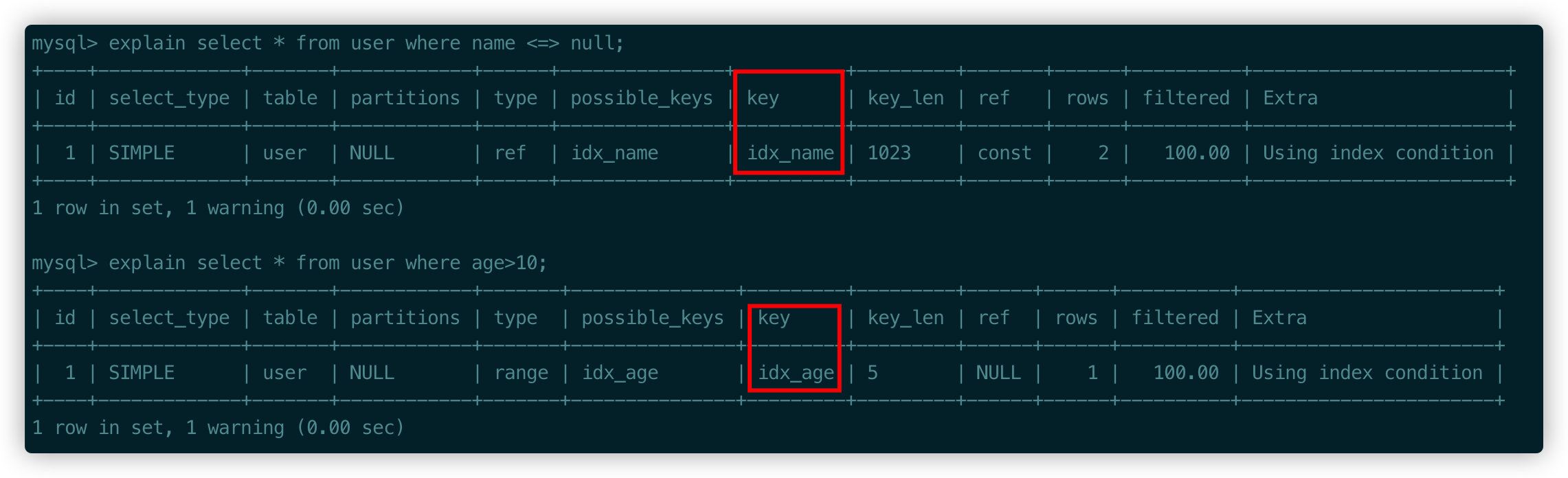
關于網上很多說如果NULL那么不能使用索引的說法���,這個描述其實并不準確����,根據引用官方文檔[3]里描述,使用is NULL和范圍查詢都是可以和正常一樣使用索引的��,實際驗證的結果好像也是這樣���,看以下例子�����。
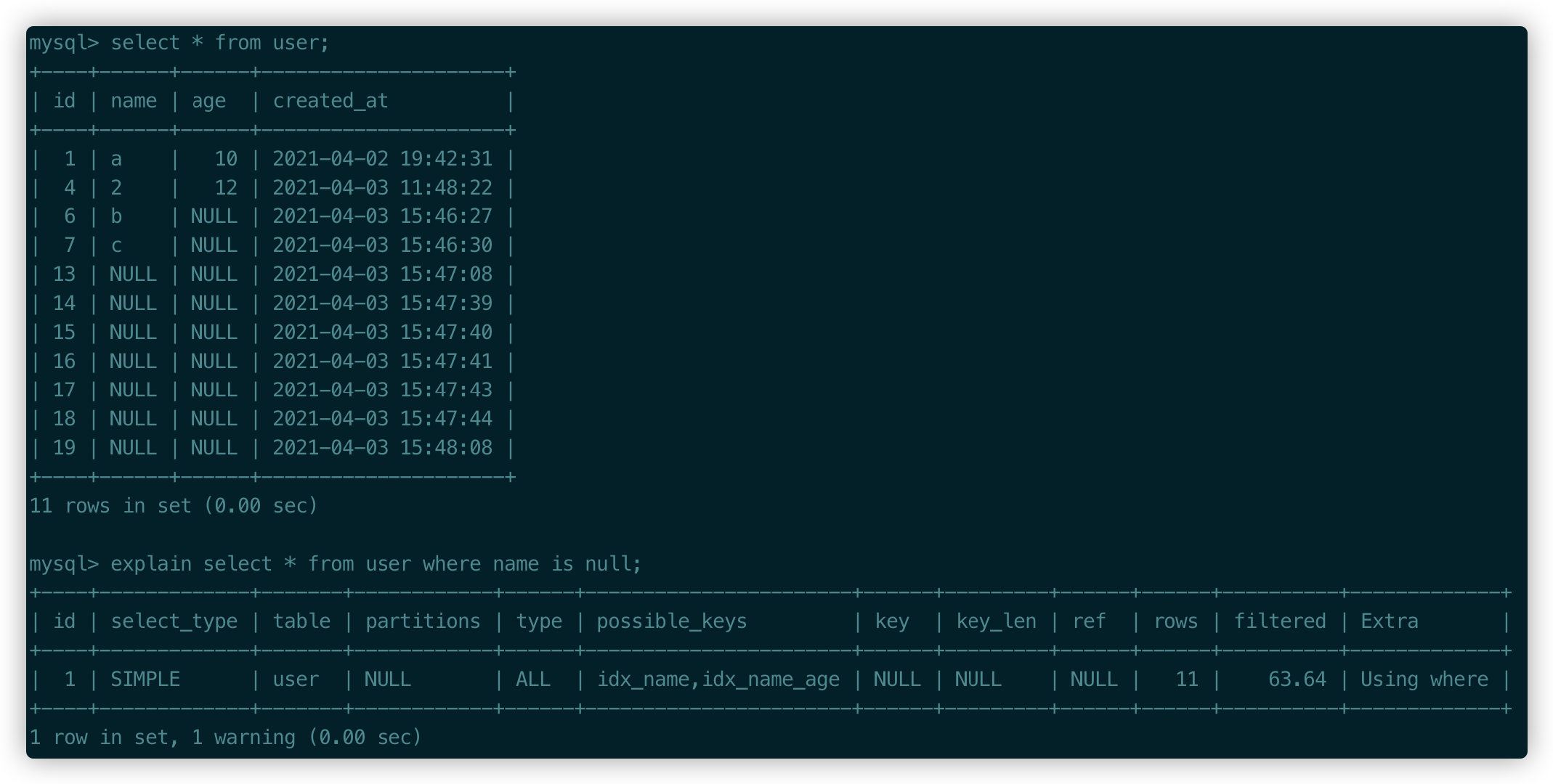
然后接著我們往數據庫中繼續插入一些數據進行測試���,當NULL列值變多之后發現索引失效了。
我們知道�,一個查詢SQL執行大概是這樣的流程:
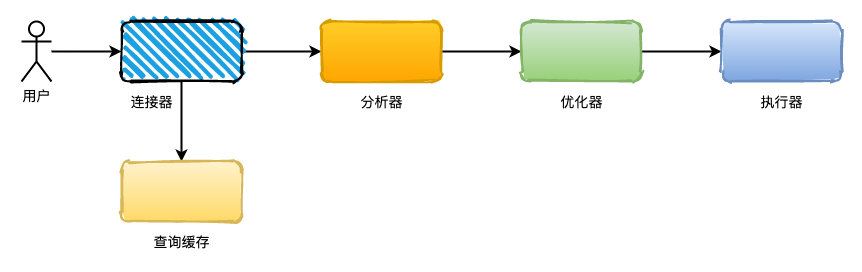
首先連接器負責連接到指定的數據庫上����,接著看看查詢緩存中是否有這條語句�����,如果有就直接返回結果�����。
如果緩存沒有命中的話,就需要分析器來對SQL語句進行語法和詞法分析,判斷SQL語句是否合法。
現在來到優化器�,就會選擇使用什么索引比較合理�����,SQL語句具體怎么執行的方案就確定下來了。
最后執行器負責執行語句��、有無權限進行查詢,返回執行結果。
從上面的簡單測試結果其實可以看到��,索引列存在NULL就會存在書中所說的導致優化器在做索引選擇的時候更復雜����,更加難以優化。
存儲空間
數據庫中的一行記錄在最終磁盤文件中也是以行的方式來存儲的,對于InnoDB來說�����,有4種行存儲格式:REDUNDANT����、 COMPACT�、 DYNAMIC 和 COMPRESSED。
InnoDB的默認行存儲格式是COMPACT���,存儲格式如下所示,虛線部分代表可能不一定會存在�����。

變長字段長度列表:有多個字段則以逆序存儲�����,我們只有一個字段所有不考慮那么多����,存儲格式是16進制����,如果沒有變長字段就不需要這一部分了。
NULL值列表:用來存儲我們記錄中值為NULL的情況���,如果存在多個NULL值那么也是逆序存儲,并且必須是8bit的整數倍�,如果不夠8bit����,則高位補0���。1代表是NULL����,0代表不是NULL。如果都是NOT NULL那么這個就存在了���。
ROW_ID:一行記錄的唯一標志����,沒有指定主鍵的時候自動生成的ROW_ID作為主鍵。
TRX_ID:事務ID。
ROLL_PRT:回滾指針。
最后就是每列的值��。
為了說明清楚這個存儲格式的問題��,我弄張表來測試,這張表只有c1字段是NOT NULL����,其他都是可以為NULL的�����。
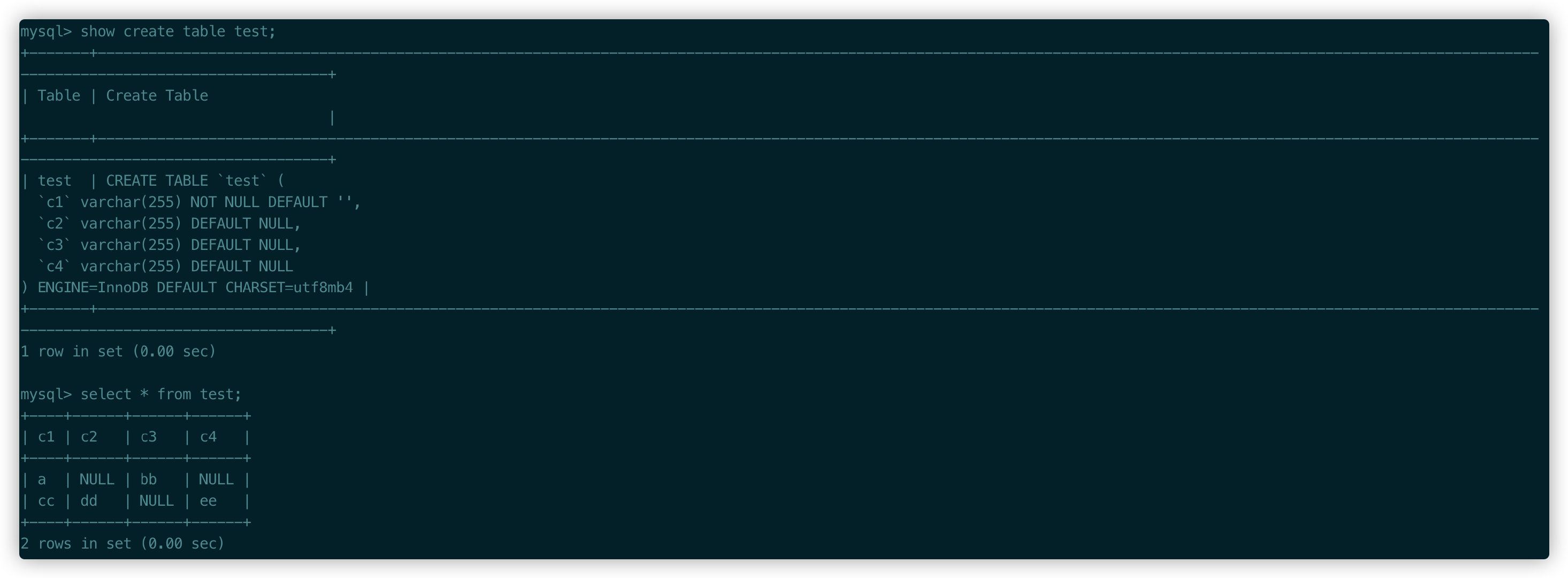
可變字段長度列表:c1和c3字段值長度分別為1和2�����,所以長度轉換為16進制是0x01 0x02,逆序之后就是0x02 0x01�����。
NULL值列表:因為存在允許為NULL的列,所以c2,c3,c4分別為010���,逆序之后還是一樣,同時高位補0滿8位����,結果是00000010����。
其他字段我們暫時不管他�,最后第一條記錄的結果就是,當然這里我們就不考慮編碼之后的結果了���。
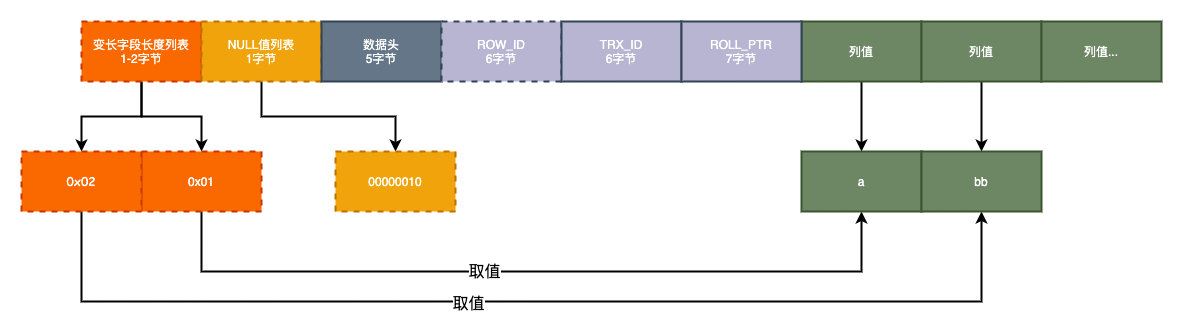
這樣就是一個完整的數據行數據的格式,反之����,如果我們把所有字段都設置為NOT NULL��,并且插入一條數據a,bb,ccc,dddd的話,存儲格式應該這樣:
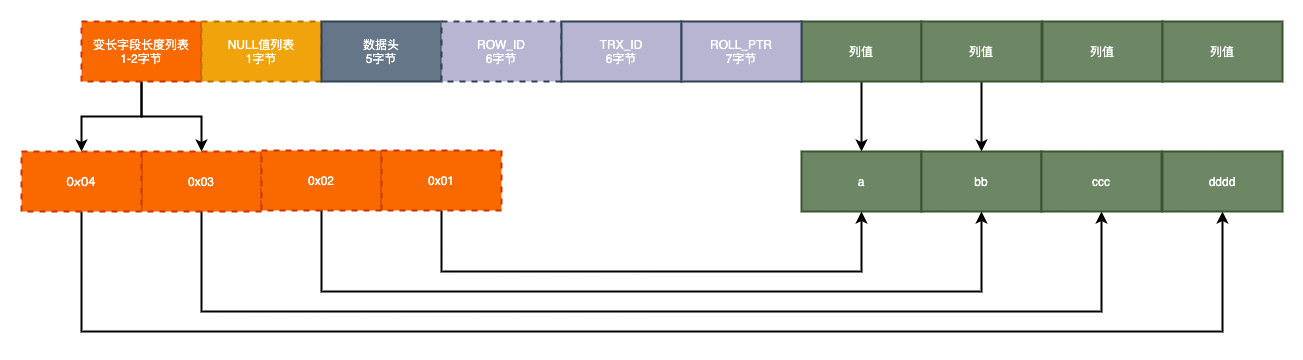
雖然我們發現NULL本身并不會占用存儲空間�����,但是如果存在NULL的話就會多占用一個字節的標志位的空間�。
文章參考文檔:
https://dev.mysql.com/doc/refman/8.0/en/problems-with-null.html
https://dev.mysql.com/doc/refman/8.0/en/working-with-null.html
https://dev.mysql.com/doc/refman/5.6/en/is-null-optimization.html
https://dev.mysql.com/doc/refman/5.6/en/innodb-row-format.html
https://www.cnblogs.com/zhoujinyi/articles/2726462.html
到此這篇關于為什么mysql字段要使用NOT NULL的文章就介紹到這了,更多相關mysql字段使用NOT NULL內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- 解決mysql使用not in 包含null值的問題
- 解決從集合運算到mysql的not like找不出NULL的問題
- MySQL null與not null和null與空值''''''''的區別詳解
- MySQL中建表時可空(NULL)和非空(NOT NULL)的用法詳解
- MySQL中NOT IN填坑之列為null的問題解決
- MySQL中可為空的字段設置為NULL還是NOT NULL
- MySQL查詢空字段或非空字段(is null和not null)
- mysql not in�����、left join�、IS NULL���、NOT EXISTS 效率問題記錄
- MySQL非空約束(not null)案例講解
