目錄
- 引言
- 索引原理
- 1�����、數據頁
- 2、頁目錄
- 3��、索引原理分析
- 總結
引言
索引是Mysql的一塊硬骨頭���,但是對于程序猿來說又是十分重要的基礎技能��。在平常的項目開發中�����,它是重要的SQL優化手段。在求職面試中���,它是面試官常常用來考察求職者數據庫性能優化方面的重要考量。因此透徹的掌握索引原理�����,并能夠將其運用到數據庫查詢實戰是每個程序猿必備的能力���。本文將從索引原理����、索引設計原則方面闡述Mysql索引��。相信閱讀完本文之后��,在Mysql索引查詢數據理解這塊完全可以征服阿里面試官�。準備好了嗎����?我們發車了。

索引原理
在進行索引設計以及優化之前���,我們先深入理解下索引的原理。因為所有的設計以及優化一定是建立在你對原理的透徹理解的基礎上�。
很多人都知道���,在進行SQL查詢時�����,同樣一張表、同樣的數據��。不加索引以及加索引進行數據查詢��。兩者差別很多����。那么到底是為什么有這種差距��。簡單來說,如果把業務數據比作為一本字典的話��,那么索引就是這本字典的目錄�����。如果我讓你查一個字�����,在你不使用目錄查的時候,那只能一頁一頁的翻,運氣不好的話可能要翻到最后一頁才能查到想要的字����,這就是傳說中的全表掃描����。但是如果我們通過目錄來查找����,那么可以很快定位字所在頁,進而查找到對應的字?���?吹搅税?��,索引的威力就在于提高數據查詢的效率�����。好了,現在我們對于索引有了感性的認識�。那么我們接下來就深入了解下�����。
我們都知道在Mysql中索引的數據結構是B+樹(這里不再說明B樹���、Hash索引等結構的優劣�,不是本文的重點),那么我們就一步一步來看看�,索引在磁盤中的B+樹是怎么長成的�����。
1、數據頁
在日常的項目開發中��,我們的業務數據大部分都存在關系型數據中����。那么數據庫中各個表中的數據最終也都是存儲在服務器的硬盤當中的�����。不知道大家有沒有想過這個數據到底是怎么存儲的呢?實際上Mysql數據庫中我們每天都在使用的數據庫表是對于人來理解的邏輯表�����。它實際在磁盤當中是通過一頁頁的數據頁進行存儲的�����。數據頁是磁盤與內存交互的基本單位�����,Mysql的Innodb存儲引擎�,實際通過buffer pool與磁盤中的數據頁進行交互,而不是直接操作磁盤中的數據頁���。數據頁的結構如下圖所示:
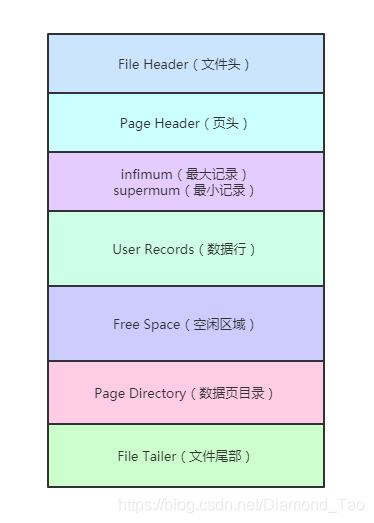
同時相鄰的數據頁之間通過雙向鏈表來維護數據頁之間的相互引用。如下圖所示�����,橙紅色部分即為數據頁�����,中間的小框框可以理解為一條條具體的數據�����。Mysql的InnoDB存儲引擎數據頁大小是16KB。Mysql的Innodb存儲引擎通過頁號來唯一定位一個數據頁��,因此每個數據頁都有自己的頁號�。通過上圖可知,每個數據頁都有都有對應的Page Header�����,在Page Header中保存了當前數據頁的頁號����,以及其下一頁的頁號和上一頁的頁號。
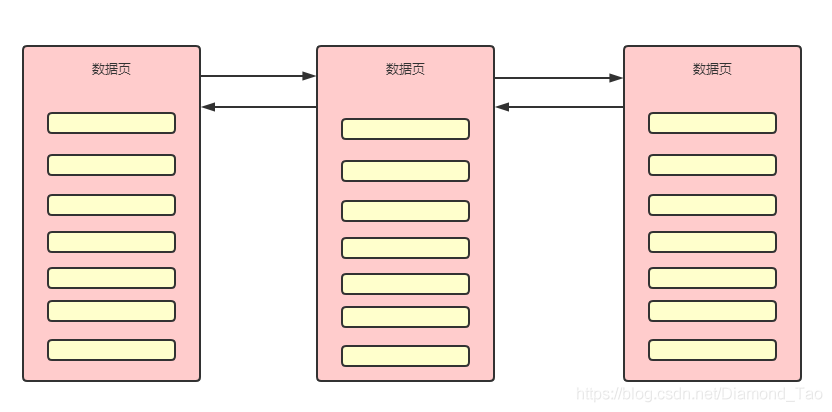
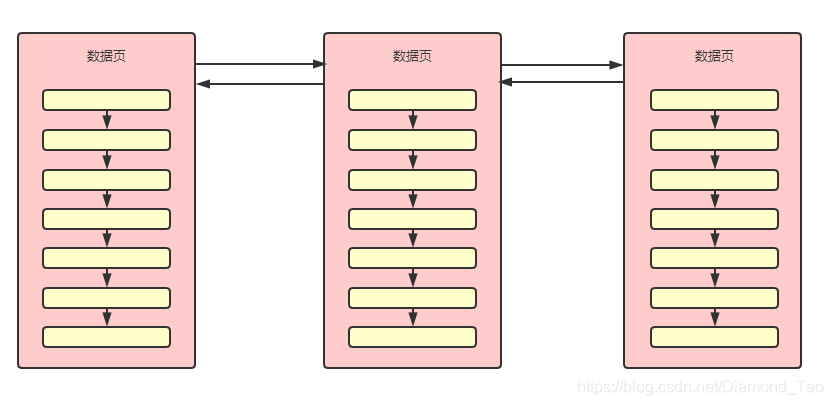
相鄰的數據之間通過指針進行互相引用�����,指針標注數據頁的頁號�����,每個數據頁中存儲了連續的一段數據,每個數據行中的記錄頭部存有下一行記錄真實數據的地址偏移量,簡單理解為擁有指針指向下一行數據的地址���。因此在數據頁的內部,實際是關于數據行的單向鏈表。這個單向鏈表是關于主鍵id的���,從小到大進行排列。
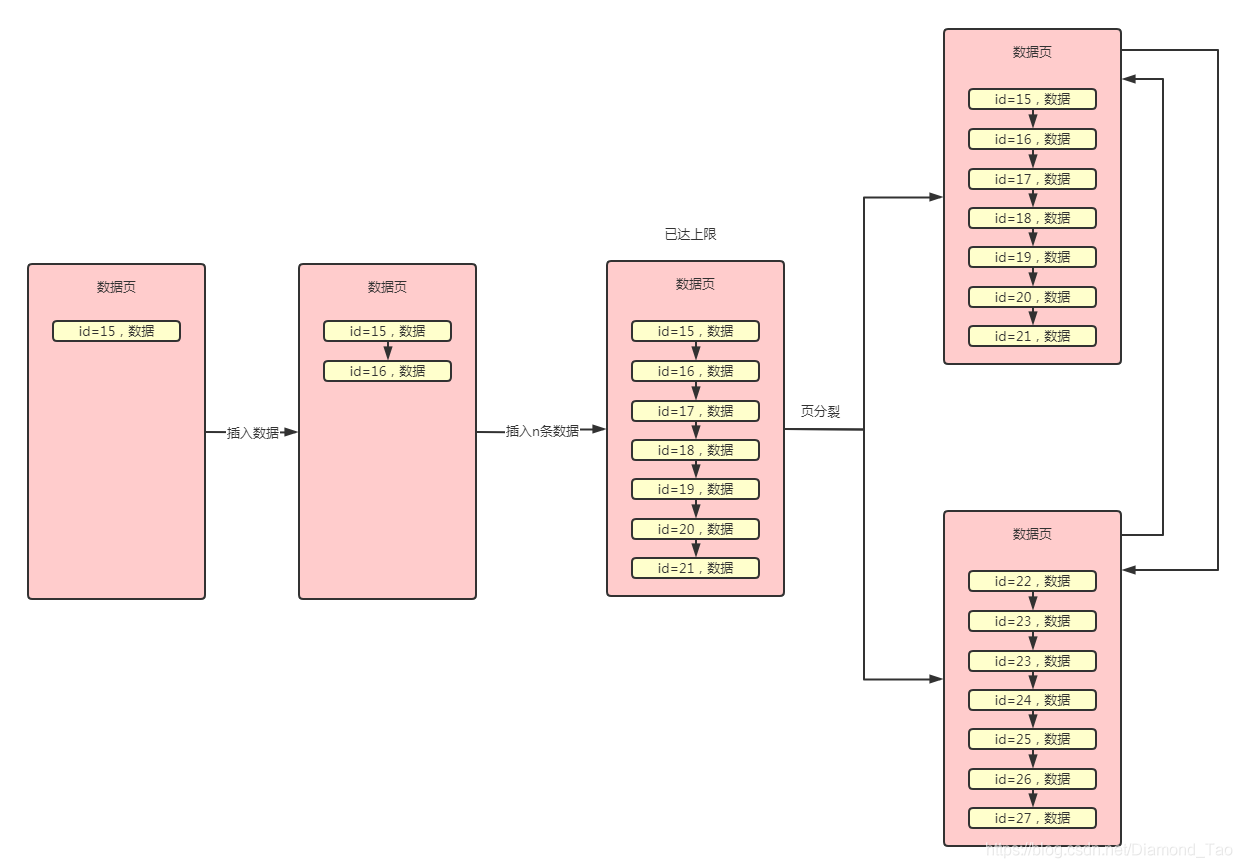
從上述的數據頁結構可知,每次進行數據插入時User Records區域就會變大,相應的的User Record區域就會減少��。當User Record區域消耗完之后���,就會發生頁分裂�,形成新的數據頁。這里需要注意的是,如果我們使用的是Mysql中的自增主鍵,那么可以保證按照id的增長順序進行數據行排列,但是如果主鍵是我們自己設置的并不是自增長的,那么有可能出現后面插入的數據的主鍵值小于前面數據的主鍵值����,那么在進行頁分裂的時候��,Mysql會按照主鍵大小重新進行排列。此處不知道大家有沒有疑問,為什么一定要按照主鍵大小進行排列呢?實際上和后續的數據查詢有關系���,數據頁中的數據按照主鍵順序進行排列是索引可以正常運行的基礎。大致的過程如下圖所示:
2����、頁目錄
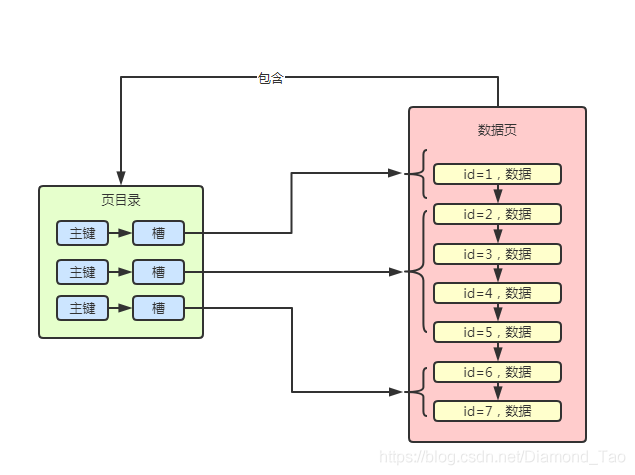
每個數據頁都有自己的頁目錄上面頁結構中的Page Directory��,這個頁目錄的作用實際上就是用來進行數據行定位的���。數據頁中的數據實際上是按組分配的����,頁目錄中的不同的槽位����,其實是對應了數據頁中的不同的分組����,查詢數據時,通過id找到對應的槽,再根據對應的槽來知道對應在數據頁中的數據行分組����,遍歷數據行分組中的數據直到找到對應的數據�。
3���、索引原理分析
(1)索引基礎
有了上面兩節的數據頁的基礎知識之后�,我們再來探討索引原理就更加容易理解了。在沒有索引時����,數據查詢都是進行全表掃描�����。遍歷查詢數據頁中的每個數據行,再遍歷所有的數據頁����,知道找到符合條件的數據項���。因此查詢效率十分的低下��。那么應該怎么才能提供數據查詢的效率呢?能不能像字典的目錄一樣,也搞個主鍵目錄來進行數據頁號的定位呢�?答案是肯定的����,Mysql實際也正是這么做的�。Mysql通過主鍵目錄實際就是傳說中的主鍵索引�,實現數據的查詢優化。在主鍵目錄中包含了兩個重要元素�,一個是數據頁中最小的主鍵����,另一個是當前數據頁的頁號�����。這樣可以通過這個主鍵目錄方面的進行數據查詢����。
舉個栗子���,如果此時想要查詢主鍵id=5的數據��,那么首先在主鍵目錄中進行查找���。此時發現主鍵id=5大于主鍵id=1����,但是又小于id=8�����,那么就可以確定實際上數據實際是在頁號為1的數據頁中的��。
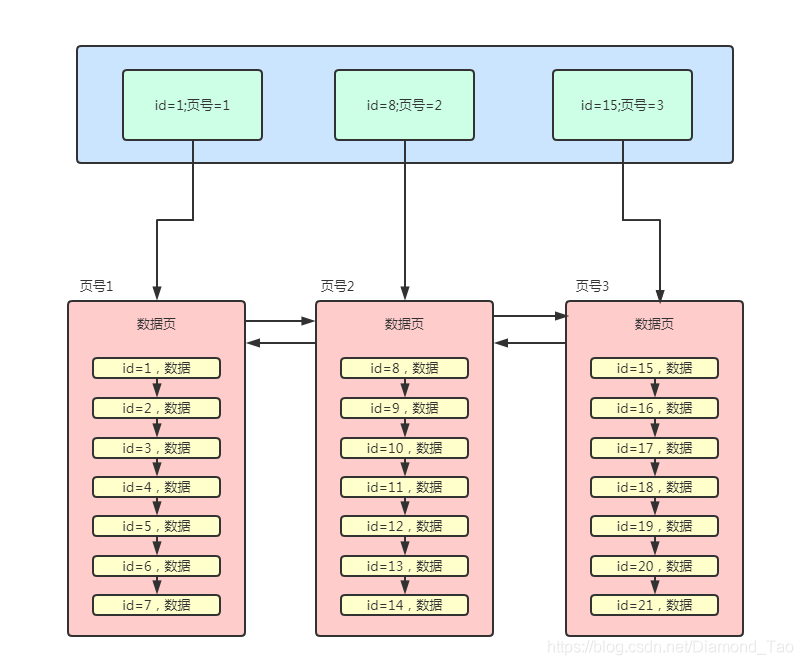
當然在實際在Mysql中會有很多的數據頁�����,因此對應的主鍵索引也會很多�,那么此時就需要通過二分查找的方式進行數據頁定位,再查找到對應的數據�����。
(2)索引頁
如今當下����,各個互聯網公司迅猛發展,對應的業務量也是十分巨大�����。因此數據庫中的數據量也是十分龐大的�。表中的數據幾百萬、上千萬可能很常見����,按照上述的主鍵目錄�,那么就需要存儲大量的主鍵與數據頁號���。即便是進行二分查找��,其數據查詢效率也是比較低的���。
Mysql實際是將索引說句存儲在索引頁中的��,當數據量比較大時候,對應的索引也會比較多�,因此通過專門的索引頁來存儲索引數據���。另外在這些索引頁的上層又通過主鍵與索引頁號來繼續進行索引頁的查詢定位�����,因此我們得到如下的結構����。其中的id號指的是對應最小的id號。
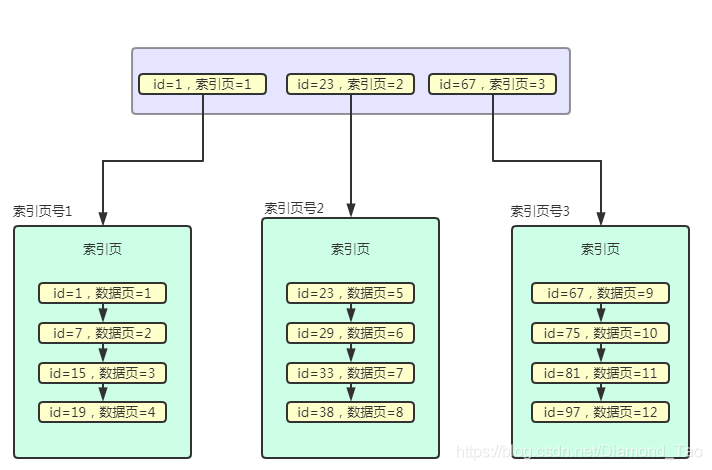
如果索引頁中的數據越來越多,索引頁同樣會進行頁分裂����。這樣索引頁也就形成了不同的層級�,索引頁層��、索引頁���、數據頁這三個頁數據就形成了我們說的B+樹�。下圖就是索引的B+樹結構��,通過它完成數據查詢效率遠高于全表掃描�����。B+的葉子節點才會存儲數據,下圖是一種主鍵索引,也叫聚簇索引��。其實我們可以看出來��,它的根本思想就是分而治之的思想����。數據量很大是吧����,那我就把數據分成很多的數據頁,數據頁很多是吧,那我就通過索引頁來組織數據頁��,索引頁很多是吧���,那就再通過索引頁來索引�。
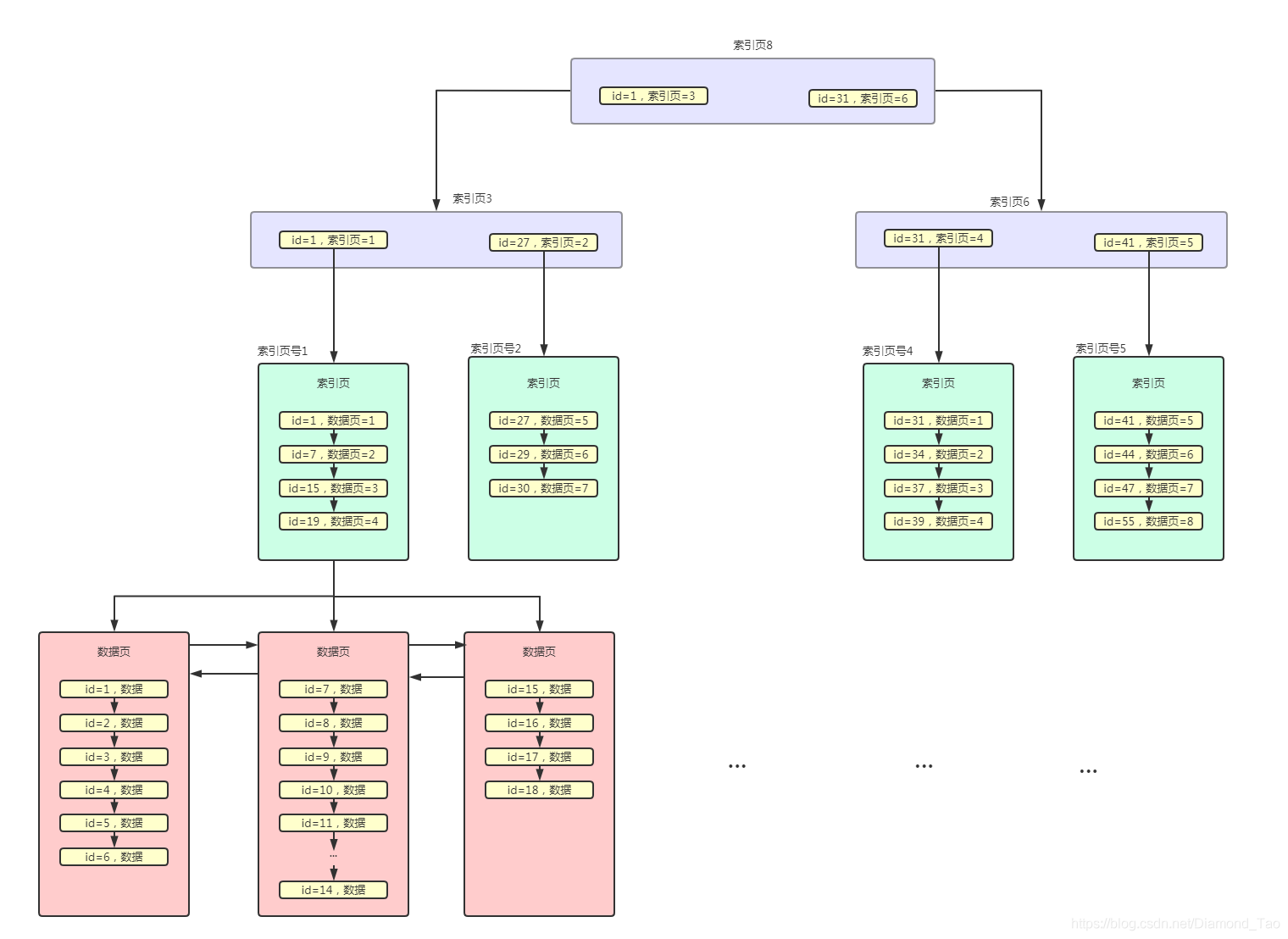
我們再來看下,數據查詢在B+樹中的查詢過程����。舉個栗子�,如當前需要查詢id為3的數據��,那么將在索引頁中判斷應該走索引頁為3的索引頁����。那么在索引頁為3中繼續判斷id=1應該走索引頁為1的索引頁�����,在索引頁中判斷應該頁號為1的數據頁����,在此數據頁中遍歷最終查詢到對應的數據�。
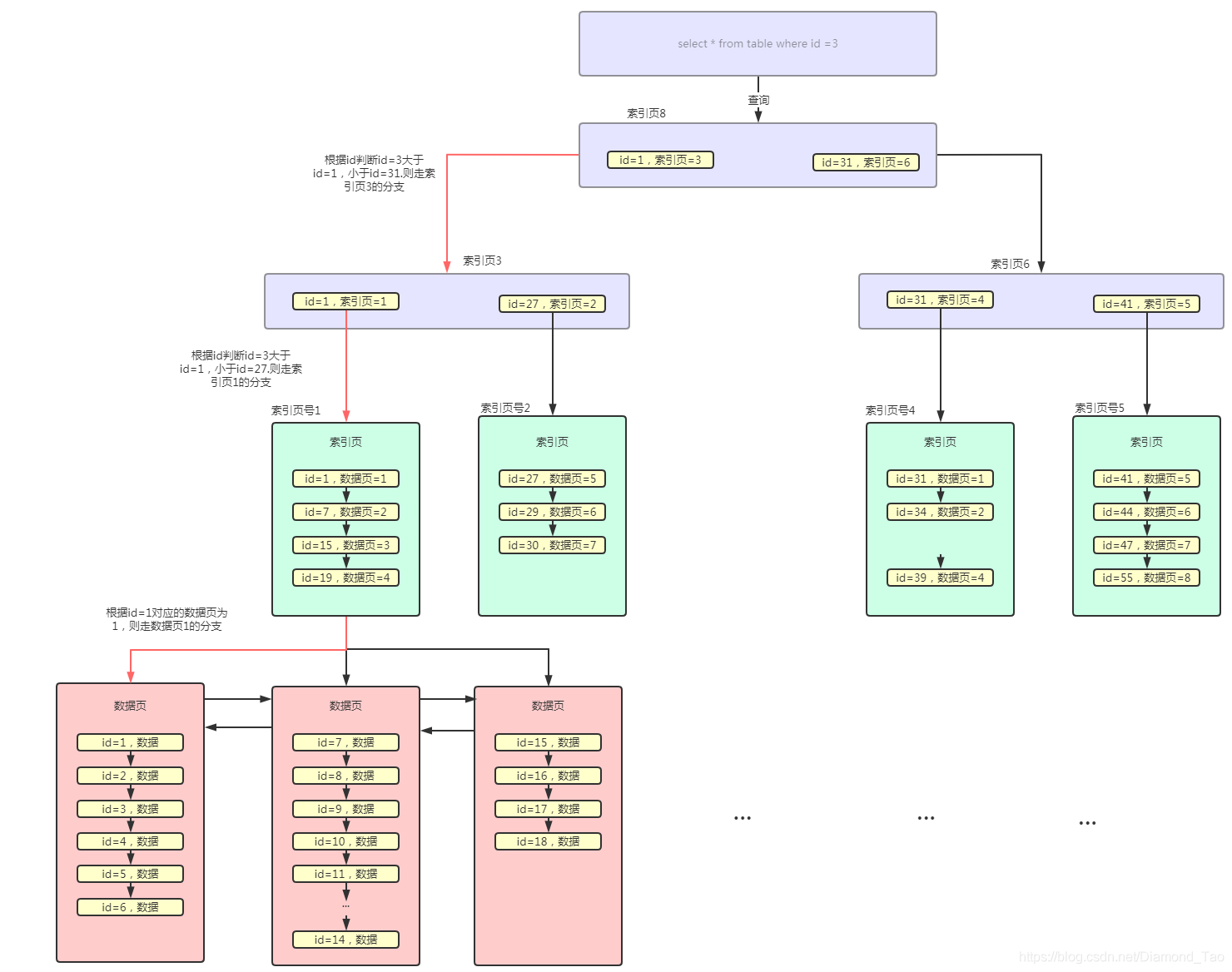
以上通過索引頁與數據頁組成的B+樹就是聚簇索引,當然我們也可以通過其他字段來建立普通索引。知識普通索引會的葉子節點存儲的是對應的主鍵id�,而不是具體的數據����,索引會存在回表的問題���,即查詢到對應的id之后�,還需要根據id繼續到聚簇索引中查詢具體的數據,通過這樣的操作才能查詢到select *的所有數據����。當然我們可以通過覆蓋索引的方式避免這樣的查詢浪費��。
總結
本文通過一步步圖解的方式,為大家拆解Mysql的InnoDB的索引原理���,同時構建出對應的B+樹索引結構����。闡述了數據查詢的具體過程。相信大家對于索引這塊有了更加深刻的理解����,后面會從實戰的角度出發��,分析下如何設計索引以及如何應對索引失效的問題。
您可能感興趣的文章:- MYSQL數據庫基礎之Join操作原理
- MySQL系列之開篇 MySQL關系型數據庫基礎概念
- Python基礎之操作MySQL數據庫
- MySql數據庫基礎知識點總結
- 一篇文章帶你了解MySQL數據庫基礎
