目錄
- 系列教程
- 一�、MySQL的架構
- 二、查詢緩存(Query Cache)
- 哪些查詢可能不會被緩存:
- 查詢緩存相關的服務器變量:
- 查詢緩存相關的狀態變量:
- 三、索引
- 1���、索引類型:
- 2�����、高性能索引策略:
- 3����、索引的優化建議
- 4���、索引的創建與刪除
- 四���、EXPLAIN命令
- 五���、SQL語句性能優化
系列教程
MySQL系列之開篇 MySQL關系型數據庫基礎概念
MySQL系列之一 MariaDB-server安裝
MySQL系列之二 多實例配置
MySQL系列之三 基礎篇
MySQL系列之四 SQL語法
MySQL系列之五 視圖���、存儲函數��、存儲過程���、觸發器
MySQL系列之六 用戶與授權
MySQL系列之七 MySQL存儲引擎
MySQL系列之八 MySQL服務器變量
MySQL系列之十 MySQL事務隔離實現并發控制
MySQL系列之十一 日志記錄
MySQL系列之十二 備份與恢復
MySQL系列之十三 MySQL的復制
MySQL系列之十四 MySQL的高可用實現
MySQL系列之十五 MySQL常用配置和性能壓力測試
一��、MySQL的架構
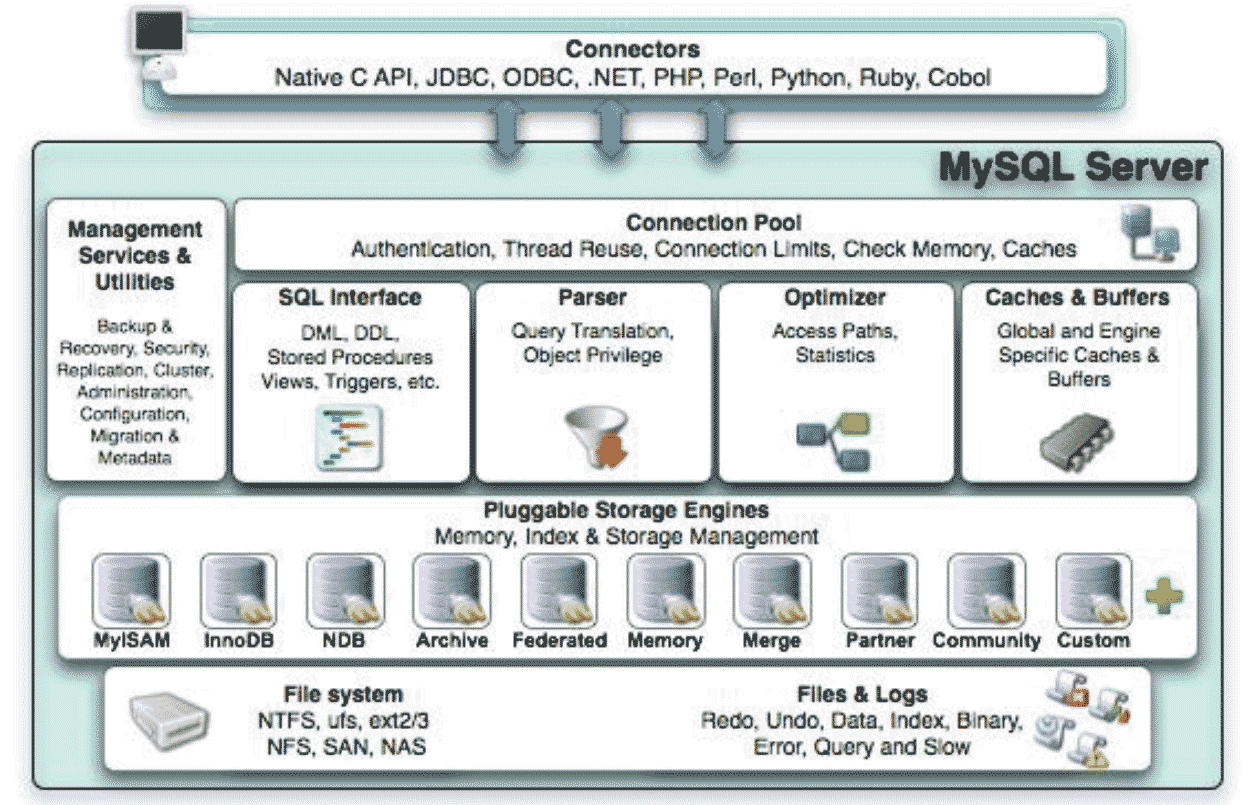
- 連接器
- 連接池,安全認證����、線程池�����、連接限制�、檢查內存、緩存
- SQL接口 DML����、DDL
- SQL解析器����,對SQL語句的權限檢查����、解析為二進制程序
- 優化器,優化訪問路徑
- 緩存cache,buffer
- 存儲引擎 innodb
- 文件系統
- 日志
二�����、查詢緩存(Query Cache)
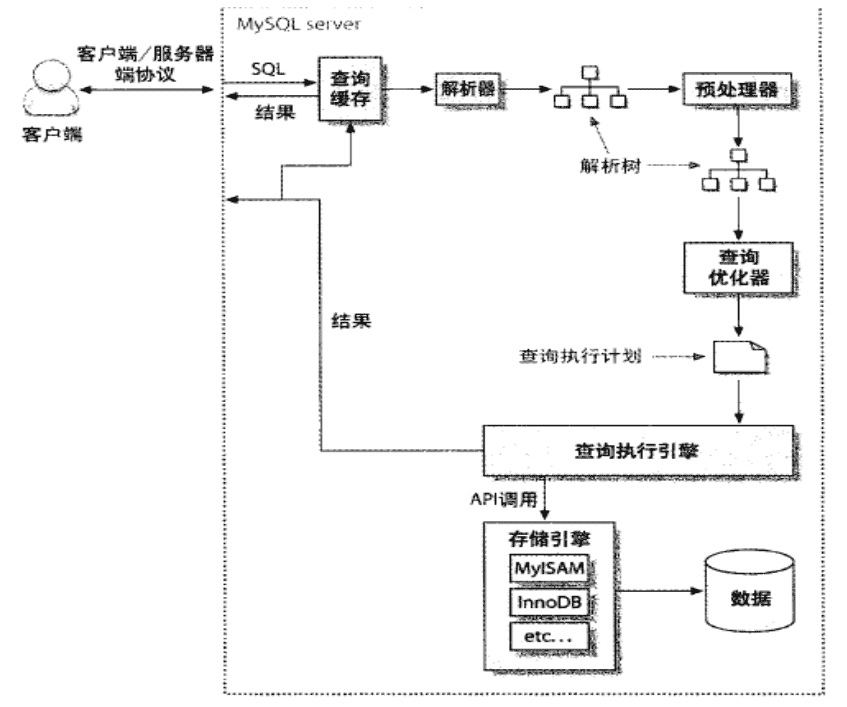
-
SQL語句
-
查詢緩存
-
解析器
-
解析樹
-
預處理
-
查找最好的查詢路徑
-
查詢優化SQL語句
-
執行計劃
-
API調用存儲引擎
-
調用數據�,返回結果
緩存SELECT操作或預處理查詢的結果集和SQL語句,當有新的SELECT語句或預處理查詢語句請求�����,先去查詢緩存���,判斷是否存在可用的記錄集���,判斷標準:與緩存的SQL語句�����,是否完全一樣���,區分大小寫��。
不需要對SQL語句做任何解析和執行�����,當然語法解析必須通過在先�����,直接從Query Cache中獲得查詢結果����,提高查詢性能
查詢緩存的判斷規則�����,不夠智能�����,也即提高了查詢緩存的使用門檻,降低其效率�;查詢緩存的使用����,會增加檢查和清理Query Cache中記錄集的開銷
哪些查詢可能不會被緩存:
- 查詢語句中加了SQL_NO_CACHE參數����;
- 查詢語句中含有獲得值的函數,包含自定義函數,如:NOW()、CURDATE()�����、GET_LOCK()����、RAND()��、CONVERT_TZ()等���;
- 對系統數據庫的查詢:mysql�、information_schema 查詢語句中使用SESSION級別變量或存儲過程中的局部變量���;
- 查詢語句中使用了LOCK IN SHARE MODE����、FOR UPDATE的語句,查詢語句中類似SELECT …INTO 導出數據的語句;
- 對臨時表的查詢操作;存在警告信息的查詢語句;不涉及任何表或視圖的查詢語句���;某用戶只有列級別權限的查詢語句;
- 事務隔離級別為Serializable時,所有查詢語句都不能緩存��。
查詢緩存相關的服務器變量:
- query_cache_min_res_unit: 查詢緩存中內存塊的最小分配單位���,默認4k�,較小值會減少浪費,但會導致更頻繁的內存分配操作���,較大值會帶來浪費,會導致碎片過多�����,內存不足����;
- query_cache_limit:單個查詢結果能緩存的最大值,默認為1M,對于查詢結果過大而無法緩存的語句�,建議使用SQL_NO_CACHE�;
- query_cache_size:查詢緩存總共可用的內存空間�����;單位字節,必須是1024的整數倍����,最小值40KB�,低于此值有警報����;
- query_cache_wlock_invalidate:如果某表被其它的會話鎖定����,是否仍然可以從查詢緩存中返回結果����,默認值為OFF,表示可以在表被其它會話鎖定的場景中繼續從緩存返回數據���;ON則表示不允許;
- query_cache_type: 是否開啟緩存功能�����,取值為ON, OFF, DEMAND�����,默認值為ON
- 值為OFF或0時�����,查詢緩存功能關閉�����;
- 值為ON或1時�����,查詢緩存功能打開,SELECT的結果符合緩存條件即會緩存�,否則���,不予緩存����,顯式指定SQL_NO_CACHE�,不予緩存;
- 值為DEMAND或2時�����,查詢緩存功能按需進行�����,顯式指定SQL_CACHE的SELECT語句才會緩存���;其它均不予緩存����。
MariaDB [(none)]> SHOW VARIABLES LIKE 'query_cache%';
+------------------------------+----------+
| Variable_name | Value |
+------------------------------+----------+
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 33554432 |
| query_cache_strip_comments | OFF |
| query_cache_type | ON |
| query_cache_wlock_invalidate | OFF |
+------------------------------+----------+
優化查詢緩存:
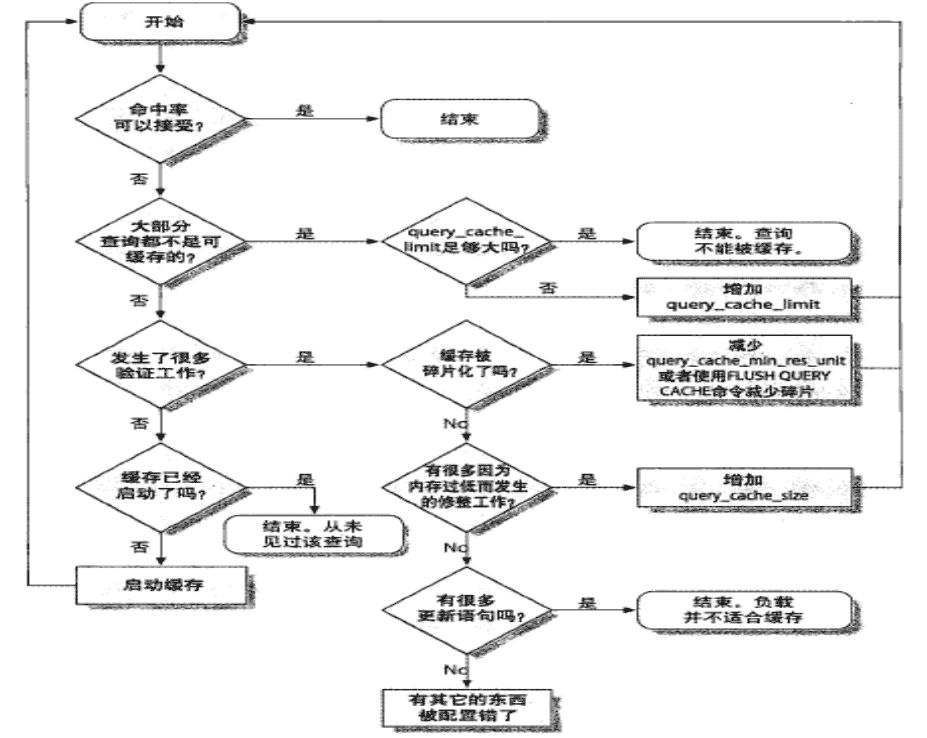
查詢緩存相關的狀態變量:
- Qcache_free_blocks:處于空閑狀態 Query Cache中內存 Block 數��;
- Qcache_free_memory:處于空閑狀態的 Query Cache 內存總量;
- Qcache_hits:Query Cache 命中次數;
- Qcache_inserts:向 Query Cache 中插入新的 Query Cache 的次數����,即沒有命中的次數���;
- Qcache_lowmem_prunes:當 Query Cache 內存容量不夠���,需要刪除老的Query Cache 以給新的 Cache 對象使用的次數����;
- Qcache_not_cached:沒有被 Cache 的 SQL 數���,包括無法被 Cache 的 SQL 以及由于 query_cache_type 設置的不會被 Cache 的 SQL語句����;
- Qcache_queries_in_cache:在 Query Cache 中的 SQL 數量����;
- Qcache_total_blocks:Query Cache 中總的 Block���。
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE 'Qcache%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 33536824 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 4 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+-------------------------+----------+
命中率和內存使用率估算:
- 查詢緩存中內存塊的最小分配單位query_cache_min_res_unit :(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
- 查詢緩存命中率 :Qcache_hits / ( Qcache_hits + Qcache_inserts ) * 100%
- 查詢緩存內存使用率:(query_cache_size – qcache_free_memory) / query_cache_size * 100%
三��、索引
索引是特殊數據結構:定義在查找時作為查找條件的字段����,索引實現在存儲引擎�。
索引可以降低服務需要掃描的數據量,減少了IO次數
索引可以幫助服務器避免排序和使用臨時表
索引可以幫助將隨機I/O轉為順序I/O
但是占用額外空間�,影響插入速度
1��、索引類型:
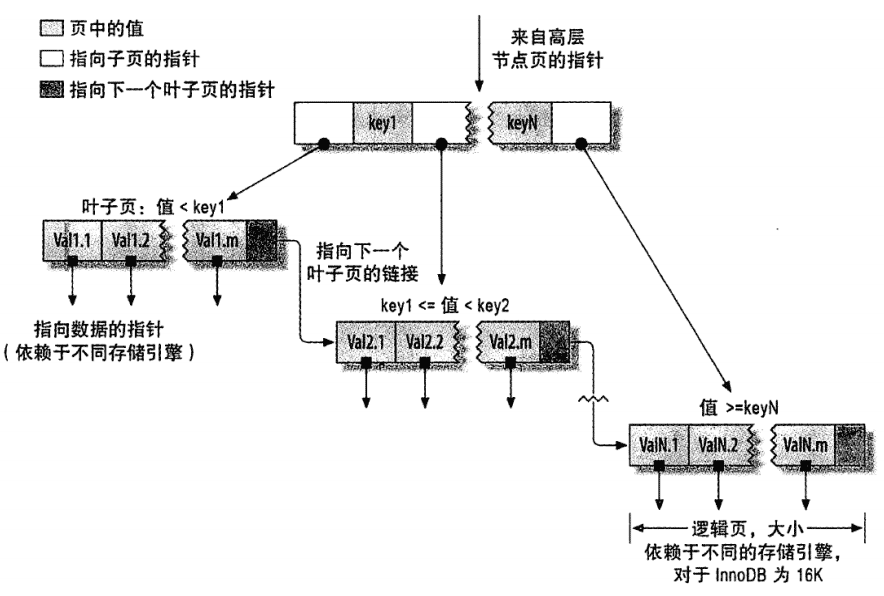
2����、高性能索引策略:
- 獨立使用列���,盡量避免其參與運算
- 使用左前綴索引:索引構建于字段的左側的多少字符要通過索引選擇性來評估�;索引選擇性:不重復的索引值和數據表的記錄總數的比值
- 多列索引:AND操作時更適合使用多列索引,而非為每個列創建單獨的索引
- 選擇合適的索引列次序:無排序和分組時,將選擇性最高放左側
3�、索引的優化建議
- 只要列中含有NULL值�,就最好不要在此例設置索引�����,復合索引如果有NULL值��,此列在使用時也不會使用索引
- 盡量使用短索引,如果可以,應該制定一個前綴長度
- 對于經常在where子句使用的列,最好設置索引
- 對于有多個列where或者order by子句,應該建立復合索引
- 對于like語句�,以%或者‘-'開頭的不會使用索引���,以%結尾會使用索引
- 盡量不要在列上進行運算(函數操作和表達式操作)
- 盡量不要使用not in和>操作
- 多表連接時���,盡量小表驅動大表,即小表 join 大表
- 在千萬級分頁時使用limit
- 對于經常使用的查詢����,可以開啟緩存
- 大部分情況連接效率遠大于子查詢
4����、索引的創建與刪除
創建索引
CREATE INDEX index_name ON tbl_name (index_col_name,...);
MariaDB [hellodb]> CREATE INDEX index_name ON students(name); #創建簡單索引
MariaDB [hellodb]> CREATE INDEX index_name_age ON students(name,age); #創建復合索引
查看索引
SHOW INDEXES FROM [db_name.]tbl_name;
MariaDB [hellodb]> SHOW INDEX FROM students\G
刪除索引
DROP INDEX index_name ON tbl_name;
MariaDB [hellodb]> DROP INDEX index_name ON students;
優化表空間
MariaDB [hellodb]> OPTIMIZE TABLE students;
查看索引使用的情況
啟用記錄索引使用情況:SET GLOBAL userstat=1;
查看索引使用情況:SHOW INDEX_STATISTICS;
我們可以統計不經常使用的索引從而進行優化
四��、EXPLAIN命令
通過EXPLAIN來分析索引的有效性:EXPLAIN SELECT clause��,獲取查詢執行計劃信息,用來查看查詢優化器如何執行查詢
MariaDB [hellodb]> EXPLAIN SELECT name FROM students WHERE name = 'Lin Daiyu'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: students
type: ref
possible_keys: index_name_age
key: index_name_age
key_len: 152
ref: const
rows: 1
Extra: Using where; Using index
- id:當前查詢語句中�,每個SELECT語句的編號����;復雜類型的查詢有三種:簡單子查詢���、用于FROM子句中的子查詢�、聯合查詢(UNION,注意:UNION查詢的分析結果會出現一個額外匿名臨時表)
- select_type:
- SIMPLE :簡單查詢
- SUBQUERY: 簡單子查詢
- PRIMARY:最外面的SELECT
- DERIVED: 用于FROM中的子查詢
- UNION:UNION語句的第一個之后的SELECT語句
- UNION RESULT: 匿名臨時表
- table:SELECT語句關聯到的表
- type:關聯類型或訪問類型�����,即MySQL決定的如何去查詢表中的行的方式,以下順序�����,性能從低到高
- ALL: 全表掃描
- index:根據索引的次序進行全表掃描����;如果在Extra列出現“Using index”表示了使用覆蓋索引,而非全表掃描
- range:有范圍限制的根據索引實現范圍掃描��;掃描位置始于索引中的某一點�����,結束于另一點
- ref: 根據索引返回表中匹配某單個值的所有行
- eq_ref:僅返回一個行,但與需要額外與某個參考值做比較
- const, system: 直接返回單個行
- possible_keys:查詢可能會用到的索引
- key: 查詢中使用到的索引
- key_len: 在索引使用的字節數
- ref: 在利用key字段所表示的索引完成查詢時所用的列或某常量值
- rows:MySQL估計為找所有的目標行而需要讀取的行數
- Extra:額外信息
- Using index:MySQL將會使用覆蓋索引�,以避免訪問表
- Using where:MySQL服務器將在存儲引擎檢索后�����,再進行一次過濾
- Using temporary:MySQL對結果排序時會使用臨時表
- Using filesort:對結果使用一個外部索引排序
五、SQL語句性能優化
- 查詢時��,能不要*就不用*�����,盡量寫全字段名
- 大部分情況連接效率遠大于子查詢
- 多表連接時�,盡量小表驅動大表�,即小表 join 大表
- 在千萬級分頁時使用limit
- 對于經常使用的查詢,可以開啟緩存
- 多使用explain和profile分析查詢語句
- 查看慢查詢日志����,找出執行時間長的sql語句優化
到此這篇關于MySQL系列之九 mysql查詢緩存及索引的文章就介紹到這了,更多相關mysql查詢緩存及索引內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家���!
您可能感興趣的文章:- MySql 緩存查詢原理與緩存監控和索引監控介紹
- 淺談mysql增加索引不生效的幾種情況
- mysql聯合索引的使用規則
- MySQL 使用索引掃描進行排序
- MySQL索引是啥?不懂就問
