語法格式:row_number() over(partition by 分組列 order by 排序列 desc)
row_number() over()分組排序功能:
在使用 row_number() over()函數時候,over()里頭的分組以及排序的執行晚于 where 、group by、 order by 的執行。
例一:
表數據:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
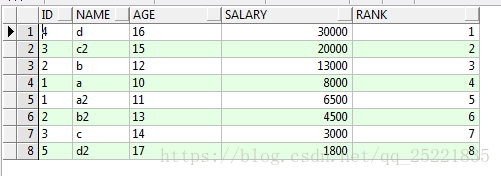
一次排序:對查詢結果進行排序(無分組)
select id,name,age,salary,row_number()over(order by salary desc) rn
from TEST_ROW_NUMBER_OVER t
結果:
進一步排序:根據id分組排序
select id,name,age,salary,row_number()over(partition by id order by salary desc) rank
from TEST_ROW_NUMBER_OVER t
結果:

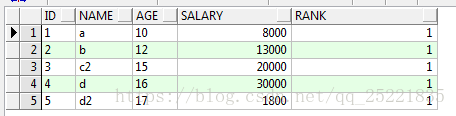
再一次排序:找出每一組中序號為一的數據
select * from(select id,name,age,salary,row_number()over(partition by id order by salary desc) rank
from TEST_ROW_NUMBER_OVER t)
where rank 2
結果:
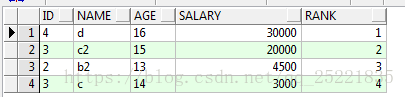
排序找出年齡在13歲到16歲數據,按salary排序
select id,name,age,salary,row_number()over(order by salary desc) rank
from TEST_ROW_NUMBER_OVER t where age between '13' and '16'
結果:結果中 rank 的序號,其實就表明了 over(order by salary desc) 是在where age between and 后執行的
例二:
1.使用row_number()函數進行編號,如
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理:先按psd進行排序,排序完后,給每條數據進行編號。
2.在訂單中按價格的升序進行排序,并給每條記錄進行排序代碼如下:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3.統計出每一個各戶的所有訂單并按每一個客戶下的訂單的金額 升序排序,同時給每一個客戶的訂單進行編號。這樣就知道每個客戶下幾單了:
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
4.統計每一個客戶最近下的訂單是第幾次下的訂單:
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
)
select MAX(rows) as '下單次數',customerID from tabs
group by customerID
5.統計每一個客戶所有的訂單中購買的金額最小,而且并統計改訂單中,客戶是第幾次購買的:
思路:利用臨時表來執行這一操作。
1.先按客戶進行分組,然后按客戶的下單的時間進行排序,并進行編號。
2.然后利用子查詢查找出每一個客戶購買時的最小價格。
3.根據查找出每一個客戶的最小價格來查找相應的記錄。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT)
as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)
6.篩選出客戶第一次下的訂單。
思路。利用rows=1來查詢客戶第一次下的訂單記錄。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order
7.注意:在使用over等開窗函數時,over里頭的分組及排序的執行晚于“where,group by,order by”的執行。
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>'2011-07-22'
到此這篇關于MYSQL row_number()與over()函數用法詳解的文章就介紹到這了,更多相關MYSQL row_number()與over()函數內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- PostgreSQL ROW_NUMBER() OVER()的用法說明
- postgreSQL中的row_number() 與distinct用法說明
- postgresql rank() over, dense_rank(), row_number()用法區別
- MySQL中row_number的實現過程
- SQL Server中row_number函數的常見用法示例詳解
- sql四大排名函數之ROW_NUMBER、RANK、DENSE_RANK、NTILE使用介紹
- sql ROW_NUMBER()與OVER()方法案例詳解
