0514-86177077
9:00-17:00(工作日)
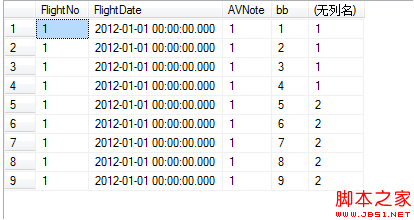
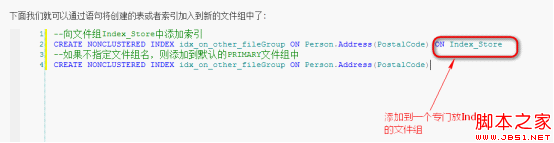
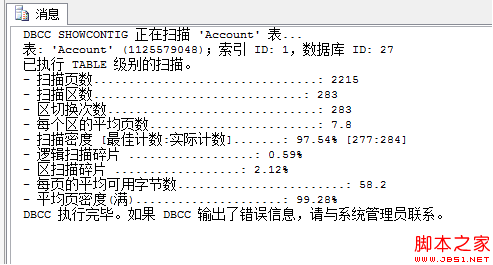
這樣就可以清楚的看到表數據是如何分區的了2.3.5創建索引分區
標簽:濟寧 金昌 宜春 貸款群呼 中衛 河源 黃山 新余
上一篇:數據庫性能優化二:數據庫表優化提升性能
下一篇:sqlserver中遍歷字符串的sql語句
Copyright ? 1999-2012 誠信 合法 規范的巨人網絡通訊始建于2005年
蘇ICP備15040257號-8
<dd id="ss4oq"></dd>