一封最簡單的郵件
echo -e "To: handy1989@qq.com\nCC: handy1989@qq.com\nFrom: handyhandy@test.com>\nSubject: test\n\nhello world" | sendmail -t
看上去有點復雜,其實就是sendmail程序從標準輸入讀取郵件源碼,-t參數(shù)表示從郵件源碼提取收件人信息,然后發(fā)送到收件人的郵件服務器,我們稍做整理,將郵件源碼保存在email.txt中如下
To: handy1989@qq.com
CC: handy1989@qq.com
From: handyhandy@test.com>
Subject: test
hello world
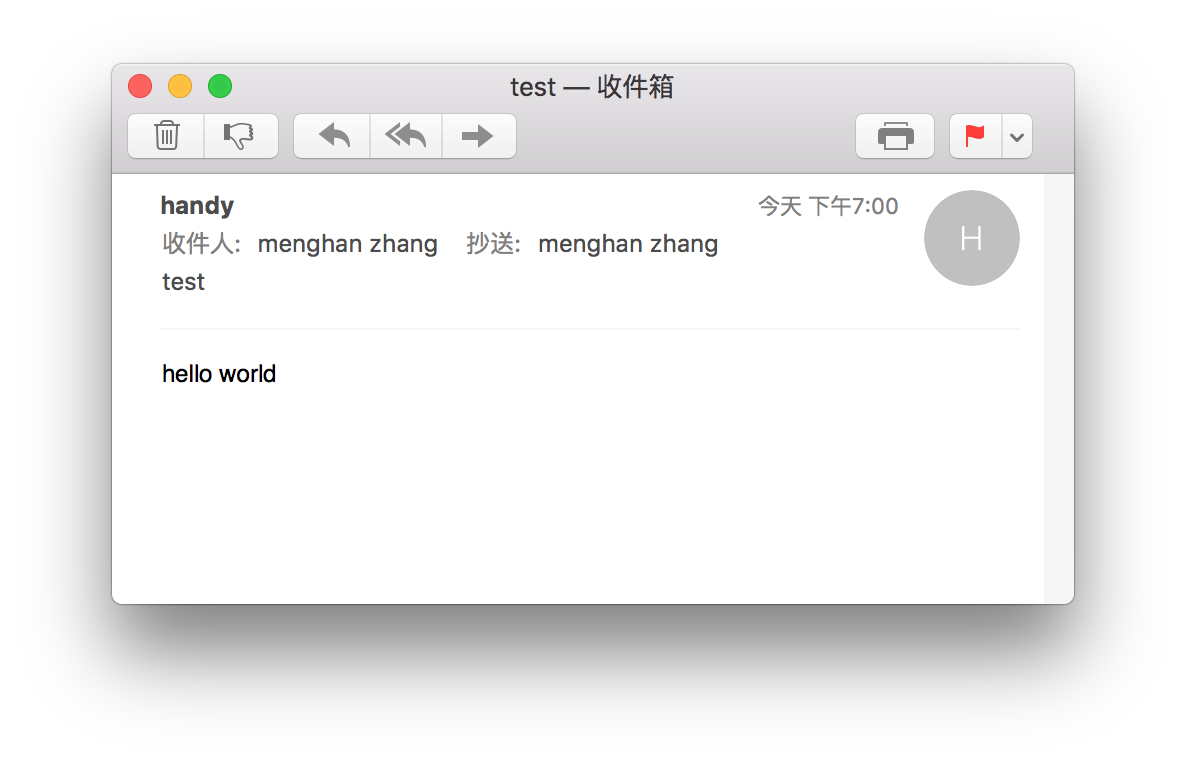
將以上命令改為cat email.txt | sendmail -t,這樣就一目了然了。收到的郵件信息如下
郵件的格式
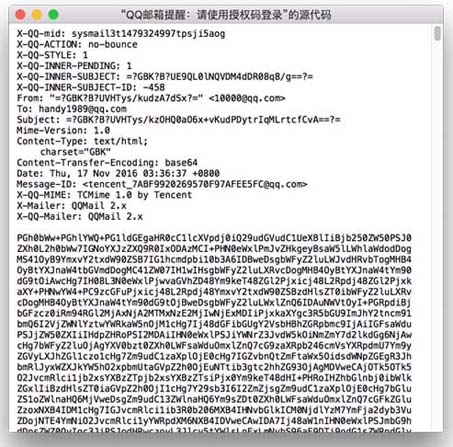
從前面的郵件源碼可以看到,郵件是和http類似的文本協(xié)議,由郵件頭和郵件內容兩部分組成,中間以空行分隔,郵件頭每行對應一個字段,和http頭類似,比如這里的To,CC,F(xiàn)rom,Subject,分別代表收件人,抄送人,發(fā)件人,標題,如果有多個收件人或抄送人,用逗號分隔,郵件內容才是我們在郵件客戶端真正看到的東西
郵件客戶端都可以查看郵件源碼,比如下面就是我收到的一封郵件的源碼
郵件標題使用中文
如果郵件標題直接使用中文字符會導致收到的郵件亂碼,為了避免這種情況,應該對中文進行base64編碼,而這也是郵件最常用的編碼方式,當然,在進行base64編碼之前先得對中文字符進行編碼(UTF-8或GBK等等),這和html的編碼是一樣的概念,采用UTF-8和base64編碼的格式如下
其中xxxxxx為編碼后的數(shù)據(jù),用python可以快速對中文進行編碼,比如對中文'測試'先進行utf-8編碼再進行base64編碼結果為
>>> import base64
>>> base64.standard_b64encode(u'測試'.encode('utf-8'))
'5rWL6K+V'
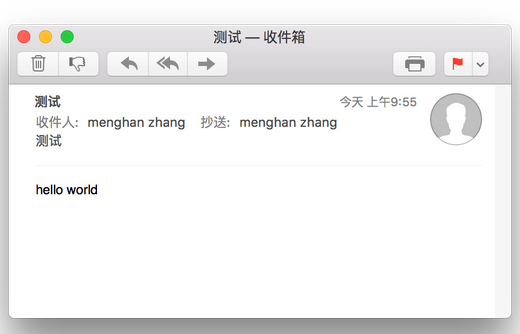
在From和Subject中使用中文,郵件源碼如下
To: handy1989@qq.com
CC: handy1989@qq.com
From: =?UTF-8?B?5rWL6K+V?=handy@test.com>
Subject: =?UTF-8?B?5rWL6K+V?=
hello world
這里將發(fā)件人的名字和郵件標題都改為了'測試',收到的郵件效果為
郵件內容使用html
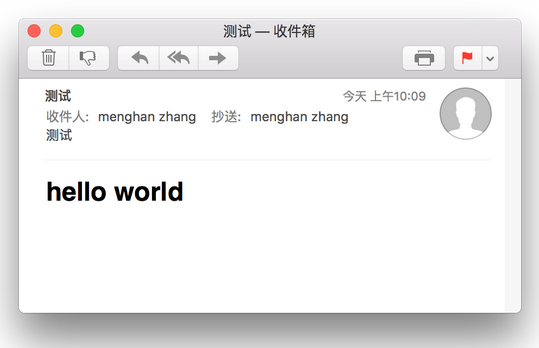
如果郵件內容是html代碼,則需要在郵件頭添加Content-type字段來標記文本類型,同時還需要標記郵件內容的字符編碼,以下郵件源碼發(fā)送的正是html內容
To: handy1989@qq.com
CC: handy1989@qq.com
From: =?UTF-8?B?5rWL6K+V?=handy@test.com>
Subject: =?UTF-8?B?5rWL6K+V?=
Content-type: text/html;charset=utf-8
h1>hello world/h1>
收到的郵件效果為
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如有疑問大家可以留言交流。
您可能感興趣的文章:- Linux shell 之 提取文件名和目錄名的一些方法總結
- Linux下使用shell腳本自動執(zhí)行腳本文件
- Linux Shell函數(shù)返回值
- linux shell內置判斷語句
