目錄
- urllib的介紹
- 發送請求
- 發送請求-Request請求
- IP代理
- 使用cookie
- 異常處理
學習了之前的基礎和爬蟲基礎之后,我們要開始學習網絡請求了。
先來看看urllib
urllib的介紹
urllib是Python自帶的標準庫中用于網絡請求的庫,無需安裝,直接引用即可。
主要用來做爬蟲開發,API數據獲取和測試中使用。
urllib庫的四大模塊:
- urllib.request: 用于打開和讀取url
- urllib.error : 包含提出的例外,urllib.request
- urllib.parse:用于解析url
- urllib.robotparser:用于解析robots.txt
案例
# 作者:互聯網老辛
# 開發時間:2021/4/5/0005 8:23
import urllib.parse
kw={'wd':"互聯網老辛"}
result=urllib.parse.urlencode(kw)
print(result)
#解碼
res=urllib.parse.unquote(result)
print(res)

瀏覽器中會把互聯網老辛,改成非中文的形式
我在瀏覽器中搜互聯網老辛,然后把瀏覽中的復制下來:

https://www.baidu.com/s?ie=utf-8f=8rsv_bp=1rsv_idx=1tn=baiduwd=%E4%BA%92%E8%81%94%E7%BD%91%E8%80%81%E8%BE%9Bfenlei=256oq=%25E7%25BE%258E%25E5%259B%25A2rsv_pq=aa5b8079001eec3ersv_t=9ed1VMqcHzdaH7l2O1E8kMBcAS8OfSAGWHaXNgUYsfoVtGNbNVzHRatL1TUrqlang=cnrsv_enter=1rsv_dl=tbrsv_btype=tinputT=3542rsv_sug2=0rsv_sug4=3542
仔細看下,加粗的部分是不是就是我們在代碼中輸出的wd的結果
發送請求
模擬瀏覽器發起一個http請求,并獲取請求的響應結果
- urllib.request.urlopen 的語法格式:
urlopen(url,data=None,[timeout]*,cafile=None,capath=None,cadefault=False,context=None
參數說明:
url: str類型的地址,也就是要訪問的URL,例如https://www/baidu.com
data: 默認值為None
urlopen: 函數返回的是一個http.client.HTTPResponse對象
代碼案例
get請求
# 作者:互聯網老辛
# 開發時間:2021/4/5/0005 8:23
import urllib.request
url="http://www.geekyunwei.com/"
resp=urllib.request.urlopen(url)
html=resp.read().decode('utf-8') #將bytes轉成utf-8類型
print(html)
為什么要改成utf-8而不是gbk, 這里要看網頁的檢查網頁源代碼里是什么:

發送請求-Request請求
我們去爬取豆瓣
# 作者:互聯網老辛
# 開發時間:2021/4/5/0005 8:23
import urllib.request
url="https://movie.douban.com/"
resp=urllib.request.urlopen(url)
print(resp)
豆瓣有反爬蟲策略,會直接報418錯誤
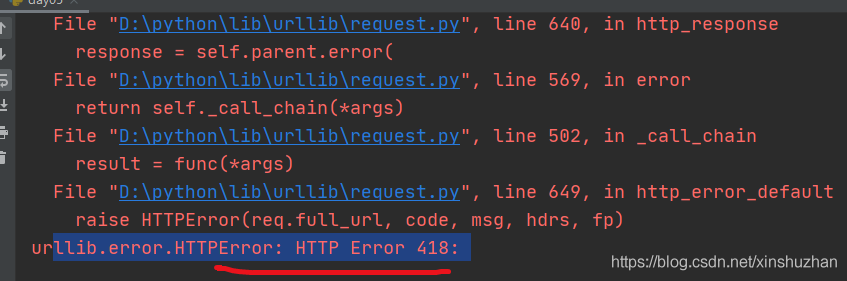
對于這種我們需要偽裝請求頭:
我們找到網頁中的user-Agent:
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400
# 作者:互聯網老辛
# 開發時間:2021/4/5/0005 8:23
import urllib.request
url="https://movie.douban.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
#構建請求對象
req=urllib.request.Request(url,headers=headers)
#使用urlopen打開請求
resp=urllib.request.urlopen(req)
#從響應結果中讀取數據
html=resp.read().decode('utf-8')
print(html)
這樣我們就用Python成功的偽裝成瀏覽器獲取到了數據
IP代理
opener的使用,構建自己的opener發送請求
# 作者:互聯網老辛
# 開發時間:2021/4/5/0005 8:23
import urllib.request
url="https://www.baidu.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
#構建請求對象
req=urllib.request.Request(url,headers=headers)
opener=urllib.request.build_opener()
resp=opener.open(req)
print(resp.read().decode())
如果你不停的發送請求,他有可能給你禁止IP, 所以我們每隔一段時間就換一個IP代理。
IP代理分類:
- 透明代理: 目標網站知道你使用了代理并且知道你的源IP地址,這種代理肯定不符合我們的初衷
- 匿名代理: 網站知道你使用了代理,但不知道你的源ip
- 高匿代理: 這是最保險的方式,目錄網站不知道你使用了代理
ip代理的方式:
免費的: https://www.xicidaili.com/nn/
收費的: 大象代理,快代理,芝麻代理
# 作者:互聯網老辛
# 開發時間:2021/4/5/0005 8:23
from urllib.request import build_opener
from urllib.request import ProxyHandler
proxy=ProxyHandler({'https':'222.184.90.241:4278'})
opener=build_opener(proxy)
url='https://www.baidu.com/'
resp=opener.open(url)
print(resp.read().decode('utf-8'))
百度其實能夠做到反爬,即使是高匿代理也做不到百分百的繞過。
使用cookie
為什么使用cookie?
使用cookie主要是為了解決http的無狀態性。
使用步驟:
- 實例化MozillaCookiejar(保存cookie)
- 創建handler對象(cookie的處理器)
- 創建opener對象
- 打開網頁(發送請求獲取響應)
- 保存cookie文件
案例: 獲取百度貼的cookie存儲下來
import urllib.request
from http import cookiejar
filename='cookie.txt'
def get_cookie():
cookie=cookiejar.MozillaCookieJar(filename)
#創建handler對象
handler=urllib.request.HTTPCookieProcessor(cookie)
opener=urllib.request.build_opener((handler))
#請求網址
url='https://tieba.baidu.com/f?kw=python3fr=index'
resp=opener.open(url)
# 保存cookie
cookie.save()
#讀取數據
def use_cookie():
#實例化MozillaCookieJar
cookie=cookiejar.MozillaCookieJar()
#加載cookie文件
cookie.load(filename)
print(cookie)
if __name__=='__main--':
use_cookie()
#get_cookie()
異常處理
我們爬取一個訪問不了的網站來捕獲異常
# 作者:互聯網老辛
# 開發時間:2021/4/6/0006 7:38
import urllib.request
import urllib.error
url='https://www.google.com'
try:
resp=urllib.request.urlopen(url)
except urllib.error.URLError as e:
print(e.reason)
可以看到捕獲到了異常
網絡請求我們已經學完了,后面我們將學習幾個常用的庫,之后就可以進行數據的爬取了。
到此這篇關于python爬蟲系列網絡請求案例詳解的文章就介紹到這了,更多相關python爬蟲網絡請求內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python爬蟲請求庫httpx和parsel解析庫的使用測評
- 詳解python requests中的post請求的參數問題
- 快速一鍵生成Python爬蟲請求頭
- Python3+Django get/post請求實現教程詳解
- python 實現Requests發送帶cookies的請求
- python實現三種隨機請求頭方式
- Python urllib request模塊發送請求實現過程解析
- python 爬蟲請求模塊requests詳解
- Python Http請求json解析庫用法解析
- python 發送get請求接口詳解
- python+excel接口自動化獲取token并作為請求參數進行傳參操作
- Python使用grequests并發發送請求的示例
- Python爬蟲基礎講解之請求
