我們使用的是IMDB數據集,它包含來自互聯網電影數據庫(IMDB)的50000條嚴重兩極分化的評論。為了避免模型過擬合只記住訓練數據,我們將數據集分為用于訓練的25000條評論與用于測試的25000條評論,訓練集和測試集都包含50%的正面評論和50%的負面評論。
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
1
填充列表,使其具有相同的長度,然后將列表轉化為(samples, word_index)的2D形狀的整數張量。對列表進行one-hot編碼,將其轉化為0和1組成的向量。
這里的Dense層實現了如下的張量計算,傳入Dense層的參數16表示隱藏單元的個數,同時也表示這個層輸出的數據的維度數量。隱藏單元越多,網絡越能夠學習到更加復雜的表示,但是網絡計算的代價就越高。
將訓練數據分出一小部分作為校驗數據,同時將512個樣本作為一批量處理,并進行20輪的訓練,同時出入validation_data來監控校驗樣本上的損失和計算精度。
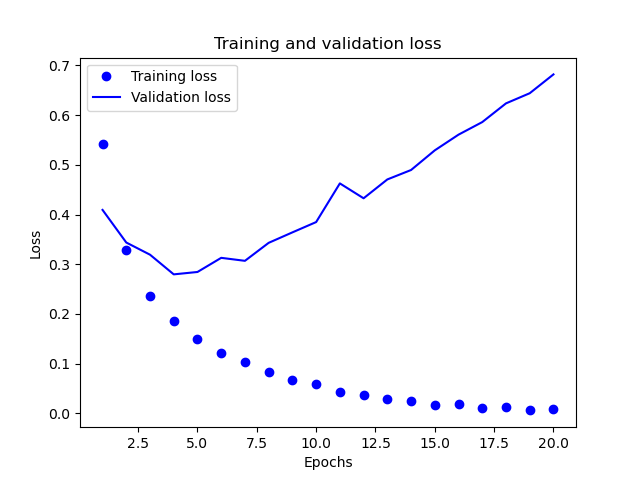
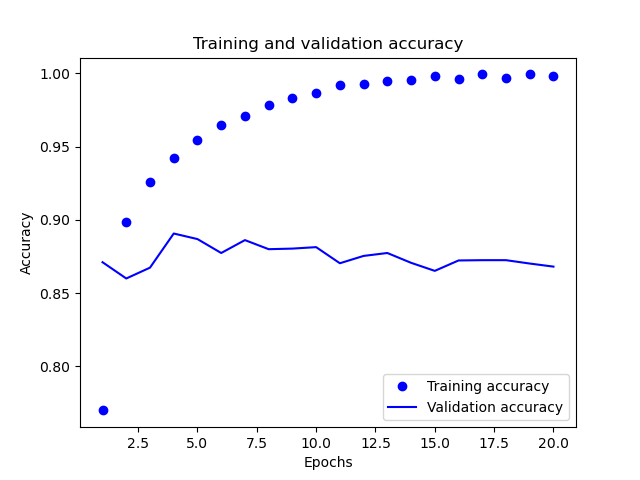
字典中包含4個條目,對應訓練過程和校驗過程的指標,其中loss是訓練過程中損失指標,accuracy是訓練過程的準確性指標,而val_loss是校驗過程的損失指標,val_accuracy是校驗過程的準確性指標。
通過對訓練和校驗指標的分析,可以看到訓練的損失每輪都在降低,訓練的精度每輪都在提升。但是校驗損失和校驗精度基本上在第4輪左右達到最佳值。為了防止這種過擬合的情況,我們可以在第四輪完成之后直接停止訓練。
到此這篇關于機器深度學習之電影的二分類情感問題的文章就介紹到這了,更多相關深度學習內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!