目錄
- 1���、打開文件
- 2����、寫入
- 3、追加
- 4�、讀文件
- 5���、文件拷貝
- 6��、tell()
- 7、truncate(size)
- 8��、seek()
1�、打開文件
open()函數簡介 :
打開文件使用open函數,可以打開一個已經存在的文件���,如果沒有這個文件的話,會創建一個新文件
完整的語法格式為:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
參數說明:(一般只會用到前三個)
file: 必需���,文件路徑(相對或者絕對路徑)。
mode: 可選����,文件打開模式
encoding: 一般使用utf8
buffering: 設置緩沖
errors: 報錯級別
newline: 區分換行符
closefd: 傳入的file參數類型
opener: 設置自定義開啟器�,開啟器的返回值必須是一個打開的文件描述符����。
'''
文件打開模式
r 以只讀方式打開文件,文件的指針將會放在文件的開頭��,這是默認模式����。
w 打開一個文件只用于寫入���。如果該文件已經存在則將其覆蓋��,如果不存在��,創建新文件。
r+ 打開一個文件用于讀寫,文件指針將會被放在文件的開頭����。
w+ 打開一個文件用于讀寫�����。如果該文件已經存在則將其覆蓋,如果不存在���,創建新文件。
rb+ 以二進制格式打開一個文件用于讀寫���。文件指針將會放在文件的開頭。
wb+ 以二進制格式打開一個文件用于讀寫��。如果該文件已經存在則將其覆蓋�����,如果不存在���,創建新文件����。
a 打開一個文件用于追加,如果文件已經存在�,文件指針將會放在文件的結尾����,也就是說�����,新的內容將會被寫到已有內容之后。
如果文件不存在,創建新的文件進行寫入��。
'''
encoding一般默認是gbk����,為中文編碼,但通常都是以utf-8寫入和讀取最好在打開文件時指定編碼類型
打開文件���,沒有的話自動創建一個文件
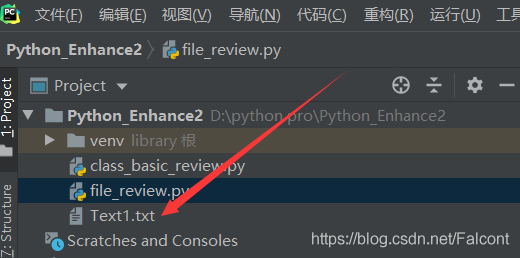
File1_Object = open('Text1.txt', 'w', encoding='utf-8') # 返會一個文件對象賦值給File1_Object
此時左邊工程欄會出現一個文件
2、寫入
默認形式寫入
File1_Object = open('Text1.txt', 'w', encoding='utf-8')
File1_Object.write('始知相憶深\n') # 往該對象里寫入內容
File1_Object.write('直道相思了無益��,未妨惆悵是清狂\n')
File1_Object.close() # 保存并關閉
此時打開文件�,會有以下內容

以二進制的形式打開并寫入
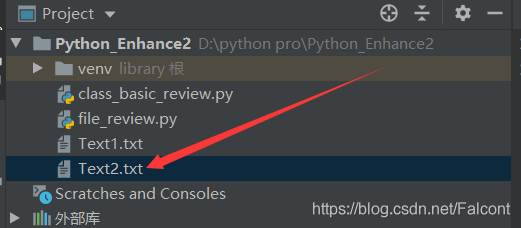
File2_Object = open('Text2.txt', 'wb')
File2_Object.write('我喜歡的人要心若明鏡,眼若星辰����,便是看盡人間丑惡���,也依然心懷善良���,優雅從容��!\n'.encode('utf-8'))
# .encode('utf-8') str->bytes
# 不加的話會報錯 TypeError: a bytes-like object is required, not 'str'
File2_Object.close()

注意,以二進制形式操作文件,不管是寫入和讀取都不加encoding����,否則會報錯
如果加encoding='utf-8'的話����,會有以下錯誤顯示:

不加encoding的情況
# 后面不加encoding='utf-8',默認為gbk
File5_Object = open('Text3.txt', 'w')
File5_Object.write('將頭發梳成大人摸樣\n')
File5_Object.write('換上一身帥氣西裝\n')
File5_Object.write('等回來見你一定比想象美\n')
File5_Object.close()
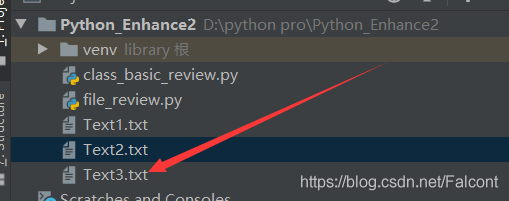
此時打開Text3會有以下顯示:

點擊箭頭指向位置��,將會顯示出內容:

3、追加
一般追加形式
File3_Object = open('Text1.txt', 'a', encoding='utf-8')
File3_Object.write('我喜歡的人要心若明鏡����,眼若星辰���,便是看盡人間丑惡���,也依然心懷善良����,優雅從容��!\n')
File3_Object.close()
此時Text1里面的內容為:

對Text2進行追加:
File2_Object = open('Text2.txt', mode='ab')
File2_Object.write('處處相思苦���!'.encode('utf-8'))
File2_Object.close()

對Text3進行追加
如果此時加了encoding=‘uft-8'
File5_Object = open('Text3.txt', 'a', encoding='utf-8')
File5_Object.write('紗窗醉夢中')
File5_Object.close()
打開文件Text3

仍會顯示異常��,此時需點擊箭頭指向位置,會顯示:
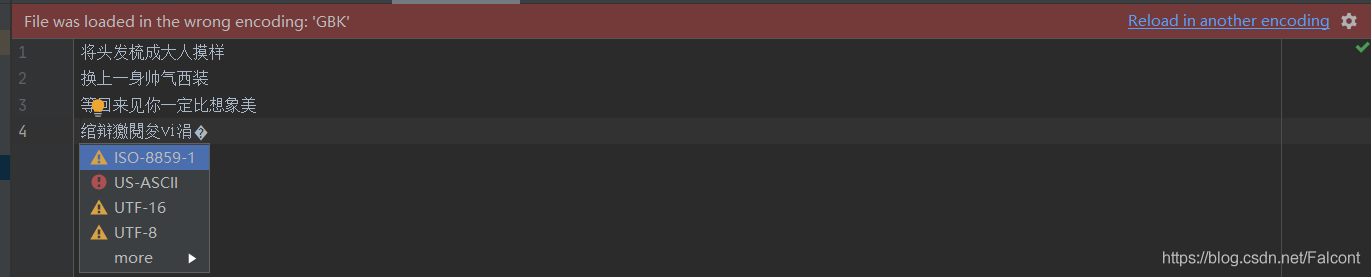
點擊utf-8的話會顯示:
所以當文件第一次打開寫入時沒有加encoding時��,后續進行操作也不要加�����,不然會有亂碼���,加了encoding的話���,編碼格式后續也不要改變�。
此時刪掉encoding=‘utf-8'�,文件內容為正常
File5_Object = open('Text3.txt', 'a')
File5_Object.write('紗窗醉夢中')
File5_Object.close()

4、讀文件
read()��,將文件的內容全部讀取出來�����。
File4_Object = open('Text1.txt', 'r', encoding='utf-8')
print(File4_Object.read())
File4_Object.close()

read(num)��,傳入一個參數,表示讀取指定字符個數
File4_Object = open('Text1.txt', 'r', encoding='utf-8')
print(File4_Object.read(4)) # 只讀取前四個字符
print(File4_Object.read()) # 第二次讀取將從上一次讀取的位置繼續讀取
File4_Object.close()
print()

readline() 一次性讀一行
File4_Object = open('Text3.txt', 'r')
print(File4_Object.readline())
print(File4_Object.readline()) # 第二次讀取將從第二行開始
print(File4_Object.readline())
File4_Object.close()

readlines() 按行讀取���,一次性讀取所有內容,返回一個列表���,每一行內容作為一個元素
File5_Object = open('Text3.txt', mode='r')
print(File5_Object.readlines())
File5_Object.close()

以二進制形式讀文件
File5_Object = open('Text2.txt', 'rb')
content = File5_Object.read()
print(content.decode('utf-8')) # decode解碼
# 由于原來Text2文件時以二進制形式打開并寫入的,此時解碼就直接用utf-8����,不能用gbk
File5_Object.close()
File5_Object = open('Text3.txt', 'rb')
content = File5_Object.readline() # 只讀取一行
print(content.decode('gbk'))
# 而Text3第一次創建并寫入時是以默認gbk的形式寫入的��,此時只能用gbk解碼
File5_Object.close()

with上下文管理對象,可以自動釋放打開的對象����,防止忘記close()操作
with open('Text2.txt', 'r', encoding='utf-8')as File5_Object:
print(File5_Object.read())

5����、文件拷貝
小文件
def Copy_File():
# 接收用戶輸入的文件名
Original_File = input('請輸入要備份的文件名:')
New_File_Name = Original_File.split('.') #分割接收到的文件名
New_File = New_File_Name[0] + '_copy.' + New_File_Name[1]
Original_File_Object = open(Original_File, mode='r', encoding='utf-8') # 以只讀的模式打開之前的文件
New_File_Object = open(New_File, mode='w', encoding='utf-8') # 以寫入的方式打開新備份的文件
New_File_Object.write(Original_File_Object.read())
Original_File_Object.close()
New_File_Object.close()
pass
Copy_File()
New_File = open('Text_copy.txt', mode='r', encoding='utf-8')
print(New_File.readlines())
New_File.close()
大文件
def Copy_Big_File():
# 接收用戶輸入的文件名
Original_File = input('請輸入要備份的文件名:')
New_File_Name = Original_File.split('.') #分割接收到的文件名
New_File = New_File_Name[0] + '_copy.' + New_File_Name[1]
try:
with open(Original_File, mode='r', encoding='utf-8')as Original_File_Object, open(New_File, mode='r', encoding='utf-8')as New_File_Object:
while True:
connect = Original_File_Object.read(1024)
New_File_Object.read(connect)
if len(connect) 1024:
break
pass
pass
pass
pass
except Exception as msg:
print(msg)
pass
pass
Copy_Big_File()
6����、tell()
文件定位,指的是當前文件指針讀取到的位置��,光標位置�����。在讀寫文件的過程中�,如果想知道當前的位置�,可以使用tell()來獲取
File_Object = open('Text1.txt', mode='r', encoding='utf-8')
print(File_Object.read(2))
print(File_Object.tell())
print(File_Object.read(5))
print(File_Object.tell())
File_Object.close()
# utf-8編碼格式中每個漢字占3個字節
print()

注解:先讀取兩個漢字�,print輸出 “始知”,此時光標位置為6說明utf-8編碼格式中每個漢字占3個字節�����,之后再讀取5個����,而只顯示了相憶深并換行打印了直,是因為還有一個換行符�,此時光標定位到20�����,又能說明轉義符在utf-8編碼格式中占2個字節。
7、truncate(size)
可以對源文件進行截取操作,截取size字節大小數據,截取之后源文件將被修改����,里面只剩下截取的數據
File_Object = open('Text1.txt', mode='r', encoding='utf-8')
print('截取之前文件里的內容:')
print(File_Object.read())
File_Object.close()
File_Object = open('Text1.txt', mode='r+', encoding='utf-8')
# r+ 打開一個文件用于讀寫�����。文件指針將會放在文件的開頭。
print()
File_Object.truncate(12) # 執行完此行代碼后源文件會被修改
print(File_Object.tell())
print('截取之后文件里的內容:')
print(File_Object.read())
print(File_Object.tell())
File_Object.close()
print()
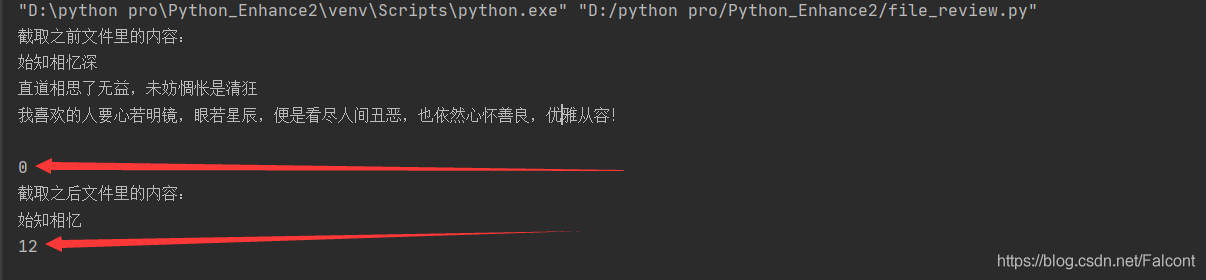
光標第一次位置指向開頭(r+),截取之后(12個字節)����,指向文件末尾12


8���、seek()
在操作文件的過程��,可定位到其他位置進行操作 seek(offset,from)有2個參數,offset指偏移字節量�����,負數是往前偏移�����,正數是往后偏移。from位置����,0表示文件開頭�,1表示當前位置,2表示文件末尾
File_Object = open('Text1.txt', mode='rb')
print(File_Object.read(15).decode('utf-8'))
print(File_Object.tell()) File_Object.seek(-6, 1)
print(File_Object.tell())
print(File_Object.read(6).decode('utf-8')) File_Object.close()
''' 使用seek()函數時,有時候會報錯為 “io.UnsupportedOperation: can't do
nonzero cur-relative seeks”
照理說�����,按照seek()方法的格式file.seek(offset,whence)����,后面的1代表從當前位置開始算起進行偏移,那又為什么報錯呢?
這是因為��,在文本文件中��,沒有使用b模式選項打開的文件�,只允許從文件頭開始計算相對位置�����,從文件尾計算時就會引發異常�����。 將
f=open("aaa.txt","r+") 改成 f = open("aaa.txt","rb") 就可以了 '''
對于文件操作更系統實戰的操作,讀者可參考
https://www.jb51.net/article/149035.htm
讀者可根據里面的流程分析對基礎進行鞏固。
到此這篇關于python基礎之文件操作的文章就介紹到這了,更多相關python文件操作內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家�!
您可能感興趣的文章:- Python通過m3u8文件下載合并ts視頻的操作
- Python文件的操作示例的詳細講解
- python中操作文件的模塊的方法總結
- 在 Python 中使用 7zip 備份文件的操作
- Python: glob匹配文件的操作
- 利用python進行文件操作
- 詳解Python利用configparser對配置文件進行讀寫操作
- Python文件操作及內置函數flush原理解析
