目錄
- 一.定義
- 二.命名方法
- 2.1小駝峰命名法
- 2.2大駝峰命名法
- 2.3下劃線命名法
- 三.命名規則
- 四.使用方法
- 5.變量進階
- 6. a = a + 1 和 a += 1 的區別
一.定義
在python中,變量名只有在第一次出現的時候,才是定義變量。當再次出現時,不是定義變量,而是直接調用之前定義的變量。
二.命名方法
2.1小駝峰命名法
第一個單詞以小寫字母開始,后續單詞的首字母大寫
firstName , lastName
2.2大駝峰命名法
每一個單詞的首字母都采用大寫字母
FirstName , LastName
2.3下劃線命名法
每個單詞之間用下劃線連接起來
first_name , last_name
三.命名規則
3.1標識符
開發人員自定義的一些符號和名稱
如:變量名、函數名、類名
標識符命名規則
1.只能由數字、字母、下劃線組成,且不能以數字開頭
2.不能和python中的關鍵字重名
3.盡量做到見名知義
4.不能使用單字符(i,o)作為變量名,因為太像0和1了
5.函數首字母小寫,類的首字母大寫
3.2關鍵字
1.關鍵字就是在python內部已經使用的標識符
2.關鍵字具有特殊的功能和含義
3.開發者不允許定義和關鍵字相同的名字的標識符
注意:
1.命名規則可以被視為一種慣例,無絕對與強制,目的是為了增加代碼的識別和可讀性
2.python中的標識符是區分大小寫的
3.在定義變量時,為了保證代碼格式,遵循PEP8規范,等號(=)的左右兩邊該各保留一個空格
四.使用方法
4.1單變量賦值:
變量名 = 值
例:a = 1
在python中賦值語句總是建立對象的引用值,而不是復制對象。因此,python中的變量存儲的是引用數據的內存地址,而不是數據存儲區域。

當涉及多個變量時:
a = 1
b = a
c = b
print(a) # 1
print(id(a)) # 140710098927888
print(b) # 1
print(id(b)) # 140710098927888
print(c) # 1
print(id(c)) # 140710098927888
a、b、c三個變量的值都等于1,即使在最初定義變量的時候b和c不是直接等于1的,但是他們仍然存儲著指向“1”的內存地址。
4.2底層邏輯:
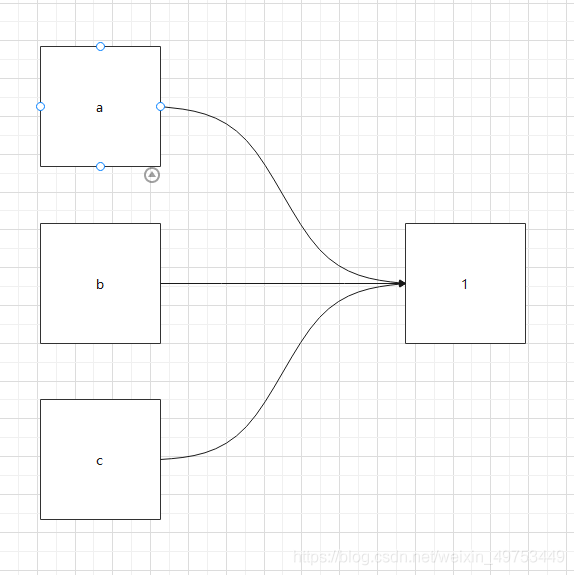
4.3總結:
可以說Python中沒有賦值,只有引用。Python 沒有“變量”,我們平時所說的變量其實只是“標簽”,是引用。
當創建了無數個變量=1時,在內存中,只會開辟無數個空間存儲變量,再開辟一個空間存儲“1”,而這些變量中存儲的內存地址都相同,全都指向“1”的內存地址。
在代碼層面,看起來像是給變量賦值,但是在底層卻是變量指向值,也就是變量引用了值。
相信大家還有疑問,那么請繼續閱讀
5.變量進階
先提出一個問題:
a = [0, 1, 2]
a[1] = a
print(a)
猜想結果是:
但是真正的結果是:
為什么結果會賦值了無限次??
結合剛才得出的結論:Python中沒有賦值,只有引用。
真相是:
這樣相當于創建了一個引用自身的結構,所以導致了無限循環。
通過遞歸函數可能更好理解:
a = [0,1,2]
a[1] = a
def fun1(n1):
for i in n1:
if type(i) == list:
return fun1(n1)
else:
print(i)
print(fun1(a[1]))
結果:
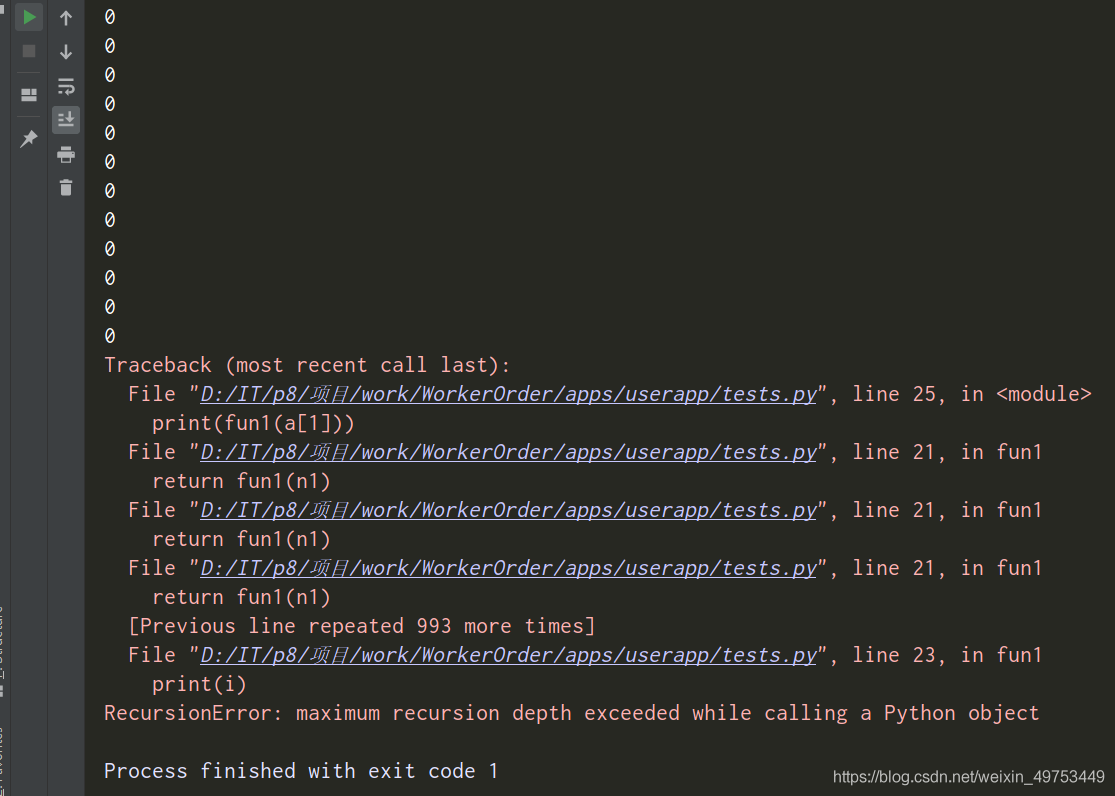
果然是:調用Python對象時超出最大遞歸深度。
底層邏輯:a[1] = a 造成了遞歸引用
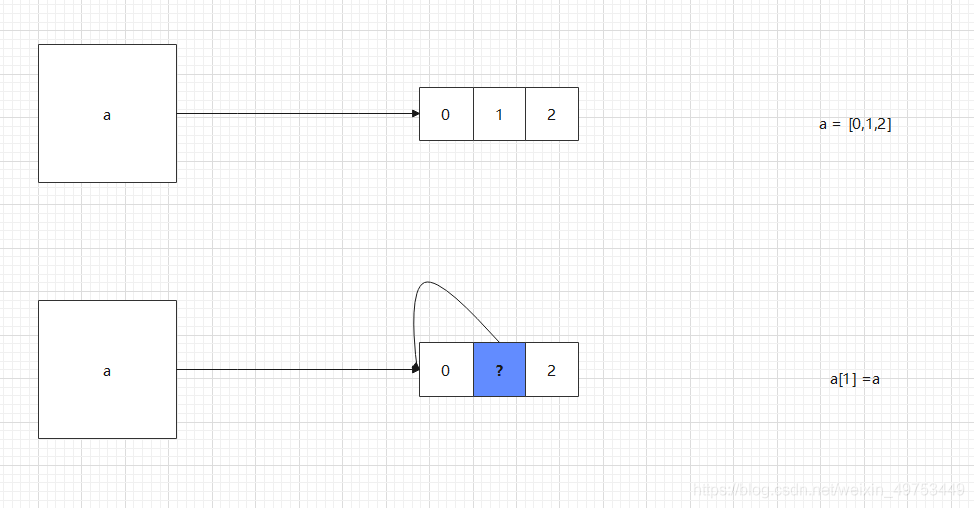
當調用變量a時,就是調用[0,1,2],此時 [0,1,2] 的結構變成了 [0,?,2] ,而 ? 又指向 [0,?,2] 本身,以此類推,造成了遞歸調用的情況。
所以在遍歷a并輸出的時候會引起超出最大遞歸深度的錯誤。
想得到 [0, [0, 1, 2], 2] 的結果并不難:
a = [0,1,2]
a[1] = a[:]
print(a) # [0, [0, 1, 2], 2]
a[:] = a[0:尾部索引值:1]
生成對象的淺拷貝或者是復制序列,不再是引用和共享變量,但此法只能頂層復制
6. a = a + 1 和 a += 1 的區別
既然談到了賦值和引用的區別,那就捎帶談一下a = a + 1 和 a += 1 的區別:
直接上代碼:
a = [1, 2]
b = a
print(id(a)) # 1878561149448
print(id(b)) # 1878561149448
a = a + [1, 2]
print(a, b) # [1, 2, 1, 2] [1, 2]
print(id(a)) # 1878593529288
print(id(b)) # 1878561149448
print ("-------------------")
a = [1, 2]
b = a
print(id(a)) # 1878561149960
print(id(b)) # 1878561149960
a += [1, 2]
print(a, b) # [1, 2, 1, 2] [1, 2, 1, 2]
print(id(a)) # 1878561149960
print(id(b)) # 1878561149960
通過對比發現問題:變量a通過“=” 和 “+=”運算,得到的變量b竟然是不同的,運算后變量a的id竟然也是不同的。
執行a = a + [1, 2] 后:
變量b指向的值并未發生改變,而變量a的id發生了變化,值也發生了變化
執行a += [1, 2] 后:
變量a和b的值都發生了改變,而二者的id卻沒有改變
具體原因,看圖說話:
執行a = a + [1, 2] 后,會生成一個新對象,并在cpu上開辟一塊空間存儲 a + [1, 2] ,然后由a指向它。所以變量a的id發生了變化,值也發生了變化。此時變量b指向的值并未發生改變。
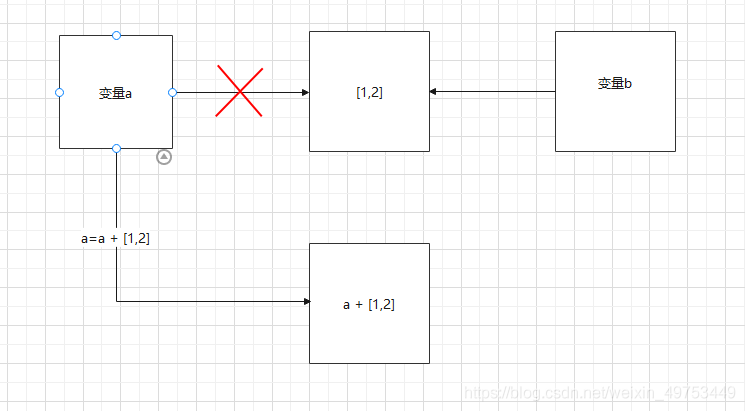
執行a += [1, 2] 后:并不會生成新對象,只是把a原本指向內存地址的對象的值改變成了 a + [1, 2],所以變量a和b的值都發生了改變,而二者的id卻沒有改變。
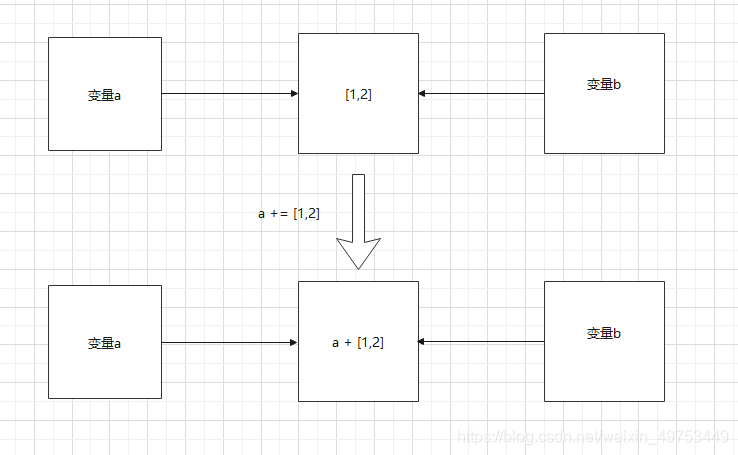
對于可變對象類型和不可變對象類型有不同的結果:
可變對象類型:+=改變了原本地址上對象的值,不改變原本的指向地址;=則改變了原本的指向地址,創建了新的對象,并指向新的地址
不可改變對象類型:都是改變原本的指向地址,指向新創建的對象地址
a = 'abc'
b = a
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
a = a + 'd'
print(a, b) # abcd abc
print(id(a)) # 1629835853168
print(id(b)) # 1629835782384
print ("-------------------")
a = 'abc'
b = a
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
a += 'd'
print(a, b) # abcd abc
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
到此這篇關于Python基礎知識之變量的詳解的文章就介紹到這了,更多相關python變量詳解內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python基礎知識(一)變量與簡單數據類型詳解
- python基礎教程之基本數據類型和變量聲明介紹
- 詳細解析Python中的變量的數據類型
- Python基礎之高級變量類型實例詳解
- Python入門變量的定義及類型理解
