目錄
- 一、實現數據解析
- 二、安裝庫
- 三、bs4 的用法
- 四、爬取圖片
- 五、爬取三國演義
一、實現數據解析
因為正則表達式本身有難度,所以在這里為大家介紹一下 bs4 實現數據解析。除此之外還有 xpath 解析。因為 xpath 不僅可以在 python 中使用,所以 bs4 和 正則解析一樣,僅僅是簡單地寫兩個案例(爬取可翻頁的圖片,以及爬取三國演義)。以后的重點會在 xpath 上。
二、安裝庫
閑話少說,我們先來安裝 bs4 相關的外來庫。比較簡單。
1.首先打開 cmd 命令面板,依次安裝bs4 和 lxml。
2. 命令分別是 pip install bs4 和 pip install lxml 。
3. 安裝完成后我們可以試著調用他們,看看會不會報錯。
因為本人水平有限,所以如果出現報錯,兄弟們還是百度一下好啦。(總不至于 cmd 命令打錯了吧 ~~)
三、bs4 的用法
閑話少說,先簡單介紹一下 bs4 的用法。
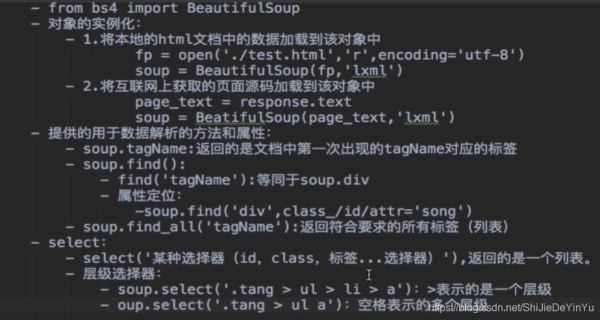
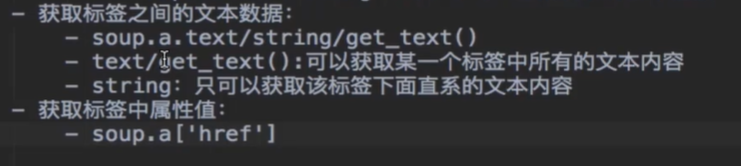
四、爬取圖片
import requests
from bs4 import BeautifulSoup
import os
if __name__ == "__main__":
# 創建文件夾
if not os.path.exists("./糗圖(bs4)"):
os.mkdir("./糗圖(bs4)")
# UA偽裝
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
# 指定 url
for i in range(1, 3): # 翻兩頁
url = "https://www.qiushibaike.com/imgrank/page/%s/" % str(i)
# 獲取源碼數據
page = requests.get(url = url, headers = header).text
# 數據解析
soup = BeautifulSoup(page, "lxml")
data_list = soup.select(".thumb > a")
for data in data_list:
url = data.img["src"]
title = url.split("/")[-1]
new_url = "https:" + url
photo = requests.get(url = new_url, headers = header).content
# 存儲
with open("./糗圖(bs4)/" + title, "wb") as fp:
fp.write(photo)
print(title, "下載完成!!!")
print("over!!!")
五、爬取三國演義
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
# UA 偽裝
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
# URL
url = "http://sanguo.5000yan.com/"
# 請求命令
page_text = requests.get(url = url, headers = header)
page_text.encoding = "utf-8"
page_text = page_text.text
soup = BeautifulSoup(page_text, "lxml")
# bs4 解析
li_list = soup.select(".sidamingzhu-list-mulu > ul > li")
for li in li_list:
print(li)
new_url = li.a["href"]
title = li.a.text
# 新的請求命令
response = requests.get(url = new_url, headers = header)
response.encoding = "utf-8"
new_page_text = response.text
new_soup = BeautifulSoup(new_page_text, "lxml")
page = new_soup.find("div", class_ = "grap").text
with open("./三國演義.txt", "a", encoding = "utf-8") as fp:
fp.write("\n" + title + ":" + "\n" + "\n" + page)
print(title + "下載完成!!!")
到此這篇關于python爬蟲之bs4數據解析的文章就介紹到這了,更多相關python bs4數據解析內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python爬蟲請求庫httpx和parsel解析庫的使用測評
- Python爬蟲之爬取最新更新的小說網站
- 用Python爬蟲破解滑動驗證碼的案例解析
- Python爬蟲爬取愛奇藝電影片庫首頁的實例代碼
- Python爬蟲之爬取嗶哩嗶哩熱門視頻排行榜
- 上手簡單,功能強大的Python爬蟲框架——feapder
- python爬蟲之爬取百度翻譯
- python爬蟲基礎之簡易網頁搜集器
- python爬蟲之利用selenium模塊自動登錄CSDN
- python爬蟲之爬取筆趣閣小說
- python爬蟲之利用Selenium+Requests爬取拉勾網
- python基礎之爬蟲入門
