import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
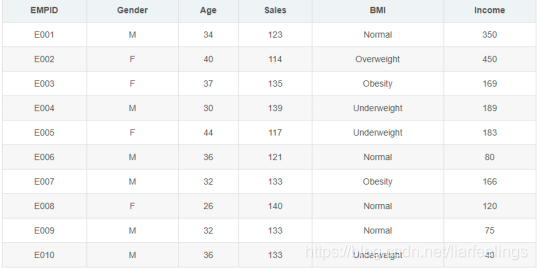
info = [{"name": "E001", "gender": "man", "age": "34", "sales": "123", "income": 350},
{"name": "E002", "gender": "feman", "age": "40", "sales": "114", "income": 450},
{"name": "E003", "gender": "feman", "age": "37", "sales": "135", "income": 169},
{"name": "E004", "gender": "man", "age": "30", "sales": "139", "income": 189},
{"name": "E005", "gender": "feman", "age": "44", "sales": "117", "income": 183},
{"name": "E006", "gender": "man", "age": "36", "sales": "121", "income": 80},
{"name": "E007", "gender": "man", "age": "32", "sales": "133", "income": 166},
{"name": "E008", "gender": "feman", "age": "26", "sales": "140", "income": 120},
{"name": "E009", "gender": "man", "age": "32", "sales": "133", "income": 75},
{"name": "E010", "gender": "man", "age": "36", "sales": "133", "income": 40}
]
# 讀取數據
def get_data():
df = pd.DataFrame(info)#DataFrame是一個以命名列方式組織的分布式數據集
df[["age"]] = df[["age"]].astype(int) # 數據類型轉為int
df[["sales"]] = df[["sales"]].astype(int) # 數據類型轉為int
return df
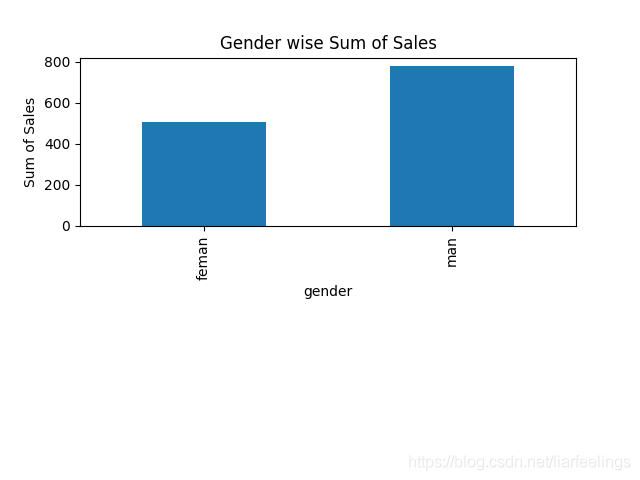
def group_by_gender(df):
var = df.groupby('gender').sales.sum()#groupby將元素通過函數生成相應的Key,數據就轉化為Key-Value格式,之后將Key相同的元素分為一組
fig = plt.figure()
ax1 = fig.add_subplot(211)#2*1個網格,1個子圖
ax1.set_xlabel('Gender') # x軸標簽
ax1.set_ylabel('Sum of Sales') # y軸標簽
ax1.set_title('Gender wise Sum of Sales') # 設置圖標標題
var.plot(kind='bar')
plt.show() # 顯示
def group_by_age(df):
age_list = [20, 30, 40, 50]
res = pd.cut(df['age'], age_list, right=False)
count_res = pd.value_counts(res)
df_count_res = pd.DataFrame(count_res)
print(df_count_res)
plt.hist(df['age'], bins=age_list, alpha=0.7) # age_list 根據年齡段統計
# 顯示橫軸標簽
plt.xlabel("nums")
# 顯示縱軸標簽
plt.ylabel("ages")
# 顯示圖標題
plt.title("pic")
plt.show()
def gender_count(df):
res = df['gender'].value_counts()
df_res = pd.DataFrame(res)
label_list = df_res.index
plt.axis('equal')
plt.pie(df_res['gender'], labels=label_list,
autopct='%1.1f%%',
shadow=True, # 設置陰影
explode=[0, 0.1]) # 0 :扇形不分離,0.1:分離0.1單位
plt.title('gender ratio')
plt.show()
print(df_res)
print(label_list)
if __name__ == '__main__':
data = get_data()
group_by_gender(data)
gender_count(data)
group_by_age(data)
到此這篇關于python數據分析之員工個人信息可視化的文章就介紹到這了,更多相關python員工信息可視化內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!