Scrapy
- Scrapy是純python實現的一個為了爬取網站數據、提取結構性數據而編寫的應用框架。
- Scrapy使用了Twisted異步網絡框架來處理網絡通訊,可以加快我們的下載速度,并且包含了各種中間件接口,可以靈活的完成各種需求
1、安裝
2、認識scrapy框架
2.1 scrapy架構圖
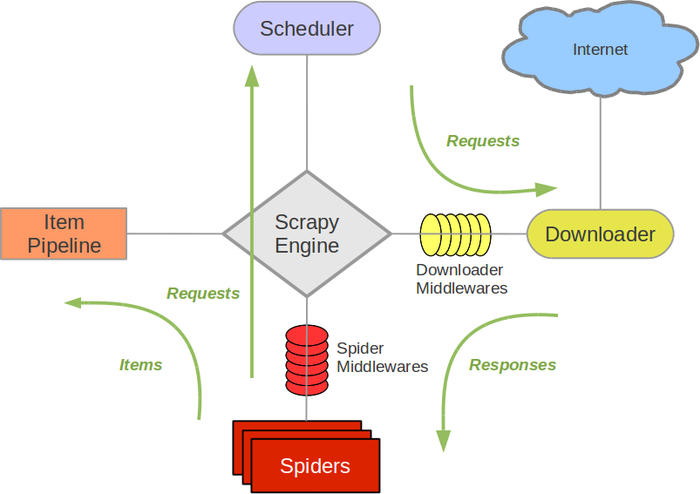
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。Scheduler(調度器): 它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊列,當引擎需要時,交還給引擎。Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item字段需要的數據,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器)
Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存儲等)的地方.Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件Spider Middlewares(Spider中間件):可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses和從Spider出去的Requests)
2.2 Scrapy運行的大體流程:
1.引擎從spider拿到第一個需要處理的URL,并將request請求交給調度器。
2.調度器拿到request請求后,按照一定的方式進行整理排列,入隊列,并將處理好的request請求返回給引擎。
3.引擎通知下載器,按照下載中間件的設置去下載這個request請求。
4.下載器下載request請求,并將獲取到的response按照下載中間件進行處理,然后后交還給引擎,由引擎交給spider來處理。對于下載失敗的request,引擎會通知調度器進行記錄,待會重新下載。
5.spider拿到response,并調用回調函數(默認調用parse函數)去進行處理,并將提取到的Item數據和需要跟進的URL交給引擎。
6.引擎將item數據交給管道進行處理,將需要跟進的URL交給調度器,然后開始循環,直到調度器中不存在任何request,整個程序才會終止。
2.3 制作scrapy爬蟲步驟:
1.創建項目:通過(scrapy startproject 項目名)來創建一個項目
2.明確目標:編寫items.py文件,定義提取的Item
3.制作爬蟲:編寫spiders/xx.py文件,爬取網站并提取Item
4.存儲內容:編寫pipelines.py文件,設計管道來存儲提取到的Item(即數據)
3、入門教程
3.1 創建項目在開始爬蟲之前,第一步需要創建一個項目。先進入打算存儲代碼的目錄,運行以下命令:
scrapy startproject myProject
其中myProject為項目名,運行上述命令后,在當前目錄下會創建一個myProject目錄,該目錄包含以下內容:
.
├── myProject
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
scrapy.cfg:項目的配置文件
myProject/items.py:項目中的目標文件
myProject/middlewares.py:項目中的中間件文件
myProject/pipelines.py:項目中的管道文件
myProject/settings.py:項目中的設置文件
myProject/spiders:放置spider代碼的目錄
3.2 明確目標(定義Item)
我們打算抓取網站http://www.itcast.cn/channel/teacher.shtml里所有老師的姓名、職稱、入職時間和個人簡介:
- 首先打開myProject/items.py文件
- Item是保存爬取到的數據的容器,其使用方法和python字典類似
- 創建一個scrapy.Item 類, 并且定義類型為 scrapy.Field的類屬性來定義一個Item(類似于ORM的映射關系)
- 創建一個MyprojectItem 類,和構建item模型(model)
import scrapy
class MyprojectItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
hiredate = scrapy.Field()
profile = scrapy.Field()
3.3 制作爬蟲在項目根目錄下輸入以下命令,可以在myProject/spiders目錄下創建一個名為itcast的爬蟲(itcast.py),并且指定爬蟲作用域的范圍itcast.cn:
scrapy genspider itcast itcast.cn
打開itcast.py,默認添上了以下內容:
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://itcast.cn/']
def parse(self, response):
pass
要建立一個Spider, 你必須用scrapy.Spider類創建一個子類,并確定了3個強制的屬性和1個方法。
name:這個爬蟲的識別名稱,必須是唯一的allow_domains:爬蟲的約束區域,規定爬蟲只爬取這個域名下的網頁,不存在的URL會被忽略。start_urls:爬取的URL列表。因此,第一個被獲取到的頁面將是其中之一。 后續的URL則從初始URL返回的數據中提取。parse(self, response):Request對象默認的回調解析方法。每個初始URL完成下載后將被調用,調用的時候傳入從每一個URL傳回的Response對象來作為唯一參數,該方法負責解析返回的數據(response.body),提取數據(生成item)以及生成需要進一步處理的URL的Request對象
修改start_urls為第一個需要爬取的URL:
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
修改parse方法提取Item:
def parse(self, response):
for teacher in response.xpath("http://ul[@class='clears']/li/div[@class='main_mask']"):
#將提取到到的數據封裝到一個MyprojectItem對象中
item = MyprojectItem()
#利用xpath返回該表達式所對應的所有節點的selector list列表
#調用extract方法序列化每個節點為Unicode字符串并返回list
name = teacher.xpath('h2/text()').extract()[0]
title = teacher.xpath('h2/span/text()').extract()[0]
hiredate = teacher.xpath('h3/text()').extract()[0].split(':')[-1]
profile = teacher.xpath('p/text()').extract()[0]
item['name'] = name
item['title'] = title
item['hiredate'] = hiredate
item['profile'] = profile
# 使用yield將獲取的數據交給pipelines,如果使用return,則數據不會經過pipelines
yield item
3.4 存儲內容
Feed輸出
如果僅僅想要保存item,可以不需要實現任何的pipeline,而是使用自帶的Feed輸出(Feed export)。主要有以下4種方式,通過-o指定輸出文件格式:
# json格式,默認為Unicode編碼
scrapy crawl itcast -o itcast.json
# json lines格式,默認為Unicode編碼
scrapy crawl itcast -o itcast.jsonl
#csv 逗號表達式,可用Excel打開
scrapy crawl itcast -o itcast.csv
# xml格式
scrapy crawl itcast -o itcast.xml
執行這些命令后,將會對爬取的數據進行序列化,并生成文件。
編寫Item Pipeline(通用):
- 每個Item Pipeline都是實現了簡單方法的Python類,他們接收到Item并通過它執行一些行為,同時也決定此Item是丟棄還是被后續pipeline繼續處理。
- 每個item pipeline組件必須實現process_item(self,item,spider)方法:
這個方法必須返回一個Item (或任何繼承類)對象, 或是拋出 DropItem異常。
參數是被爬取的item和爬取該item的spider
spider程序每yield一個item,該方法就會被調用一次
open_spider(self,spider):開啟spider的時候調用,只執行1次
close_spider(self,spider):關閉spider的時候調用,只執行1次
item寫入json文件:
import json
from itemadapter import ItemAdapter
class MyprojectPipeline:
def open_spider(self,spider):
'''可選實現,開啟spider時調用該方法'''
self.f = open('itcast.json','w')
def process_item(self, item, spider):
'''必須實現,被拋棄的item將不會被后續的pipeline組件所處理'''
self.f.write(json.dumps(dict(item),ensure_ascii=False)+'\n')
return item
def close_spider(self,spider):
'''可選實現,關閉spider時調用該方法'''
self.f.close()
啟用Item Pipeline組件
ITEM_PIPELINES = {
'myProject.pipelines.MyprojectPipeline': 300,
}
在settings.py文件里添加以上配置(可以取消原有的注釋),后面的數字確定了item通過pipeline的順序,通常定義在0-1000范圍內,數值越低,組件的優先級越高
啟動爬蟲
查看當前目錄下是否生成了itcast.json文件
4、Scrapy Shell
Scrapy終端是一個交互終端,我們可以在未啟動spider的情況下嘗試及調試代碼,也可以用來測試XPath或CSS表達式,查看他們的工作方式,方便我們爬取的網頁中提取的數據。
啟動scrapy shell
命令行啟動,url是要爬取的網頁的地址
常見可用對象
- response.status:狀態碼
- response.url:當前頁面url
- response.body:響應體(bytes類型)
- response.text:響應文本(str類型)
- response.json():如果響應體的是json,則直接轉換成python的dict類型
- response.headers:響應頭
- response.selector:返回Selector對象,之后就可以調用xpath和css等方法,也可以簡寫成response.xpath()和response.css()
selector選擇器
Selector有四個基本的方法,最常用的還是xpath:
Selector有四個基本的方法,最常用的還是xpath:
- xpath(): 傳入xpath表達式,返回該表達式所對應的所有節點的selector list列表
- extract(): 序列化該節點為Unicode字符串并返回list
- css(): 傳入CSS表達式,返回該表達式所對應的所有節點的selector list列表,語法同 BeautifulSoup4
- re(): 根據傳入的正則表達式對數據進行提取,返回Unicode字符串list列表
5、Spider
Spider類定義了如何爬取某個(或某些)網站。包括了爬取的動作(例如:是否跟進鏈接)以及如何從網頁的內容中提取結構化數據(爬取item)。
scrapy.Spider是最基本的類,所有編寫的爬蟲必須繼承這個類。
import scrapy
class XxSpider(scrapy.Spider):
pass
主要用到的函數及調用順序為:
- __init__():初始化爬蟲名字和start_urls列表
- start__requests(self):調用make_requests_from_url()生成Requests對象交給Scrapy下載并返回response
- parse(self,response):解析response,并返回Item或Requests(需指定回調函數)。Item傳給Item pipline持久化 , 而Requests交由Scrapy下載,并由指定的回調函數處理(默認parse()),一直進行循環,直到處理完所有的數據為止。
其他方法
log(self, message, level=log.DEBUG)
message:字符串類型,寫入的log信息
level:log等級,有CRITICAL、 ERROR、WARNING、INFO、DEBUG這5種,默認等級為DEBUG
6、CrwalSpider
快速創建CrawlSpider模板:
scrapy genspider -t crawl 爬蟲名 爬蟲域
scrapy.spiders.CrwalSpider是編寫的爬蟲所必須繼承的類
from scrapy.spiders import CrawlSpider
class XxSpider(CrawlSpider):
pass
CrawlSpider類繼承于Spider類,它定義了一些規則(rule)來提供跟進link的方便的機制,從爬取的網頁中獲取link并繼續爬取的工作更適合。
LinkExtractor
class scrapy.spiders.LinkExtractor
- 每個LinkExtractor對象有唯一的公共方法是 extract_links(),它接收一個Response對象,并返回一個 scrapy.link.Link 對象。根據不同的response調用多次來提取鏈接
- 主要參數:
allow:滿足括號中“正則表達式”的值會被提取,如果為空,則全部匹配。
deny:與這個正則表達式(或正則表達式列表)匹配的URL一定不提取。
allow_domains:會被提取的鏈接的domains。
deny_domains:一定不會被提取鏈接的domains。
restrict_xpaths:使用xpath表達式,和allow共同作用過濾鏈接。
rules
class scrapy.spiders.Rule
在rules中包含一個或多個Rule對象,每個Rule對爬取網站的動作定義了特定操作。如果多個rule匹配了相同的鏈接,第一個會被使用。
Rule對象主要參數:
- link_extractor:是一個Link Extractor對象,用于定義需要提取的鏈接
- callback:從link_extractor中每獲取到鏈接時,該回調函數接受一個response作為其第一個參數。注意:字符串類型,避免使用'parse'
- follow:布爾類型,指定了根據該規則從response提取的鏈接是否需要跟進。 如果callback為None,follow 默認設置為True ,否則默認為False。
- process_links:指定函數,從link_extractor中獲取到鏈接列表時將會調用該函數,主要用來過濾。
- process_requests:指定函數, 該規則提取到每個request時都會調用該函數,用來過濾request。
CrawSpider爬蟲示例
以陽光熱線問政平臺http://wz.sun0769.com/political/index/politicsNewest?id=1為例,爬取投訴帖子的編號、帖子的標題,帖子的處理狀態和帖子里的內容。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from myProject.items import MyprojectItem
class SunSpider(CrawlSpider):
name = 'sun'
allowed_domains = ['wz.sun0769.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1page=1']
rules = (
Rule(LinkExtractor(allow=r'id=\d+page=\d+')),#每一頁的匹配規則,callback為None,默認跟進
Rule(LinkExtractor(allow=r'politics/index\&;id=\d+'), callback='parse_item'),#每個帖子的匹配規則,設置了callback,默認不跟進
)
def parse_item(self, response):
item = MyprojectItem()
title = response.xpath('//div[@class="mr-three"]/p[@class="focus-details"]/text()').extract()[0] #帖子標題
status = response.xpath('//div[@class="focus-date clear focus-date-list"]/span[3]/text()').extract()[0].split()[1] #處理狀態
number = response.xpath('//div[@class="focus-date clear focus-date-list"]/span[4]/text()').extract()[0].split(':')[-1] #帖子編號
content = response.xpath('//div[@class="details-box"]/pre/text()').extract()[0] #帖子內容
item['title'] = title
item['status'] = status
item['number'] = number
item['content'] = content
yield item
7、logging功能
Scrapy提供了log功能,通過在setting.py中進行設置,可以被用來配置logging
設置
- LOG_ENABLED:默認: True,啟用logging
- LOG_ENCODING:默認: 'utf-8',logging使用的編碼
- LOG_FILE:默認::None,在當前目錄里創建logging輸出文件的文件名
- LOG_LEVEL:默認:'DEBUG',有'CRITICAL'(嚴重錯誤)、'ERROR'(一般錯誤)、'WARNING'(警告信息)、'INFO'(一般信息)、'DEBUG'(調試信息)這5種等級
- LOG_STDOUT:默認: False 如果為 True,進程所有的標準輸出(及錯誤)將會被重定向到log中。
示例:
#在settings.py中任意位置添上以下兩句,終端上會清爽很多
LOG_FILE = "xxx.log"
LOG_LEVEL = "INFO"
8、Request對象
GET請求
- 可以使用yield scrapy.Request(url,callback)方法來發送請求
- Request對象初始化方法傳入參數如下:
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None):
pass
主要參數:
- url:需要請求并進行下一步處理的url
- callback:指定該請求返回的Response,由哪個函數來處理
- method:默認'GET',一般不需要指定,可以是‘POST','PUT'等
- headrs:請求時包含的頭文件,一般不需要
- meta:比較常用,在不同的request之間傳遞數據用的,dict類型
- encoding:使用默認的‘utf-8'就行
- dont_filter:表明該請求不由調度器過濾,可以發送重復請求,默認為False
- errback:指定錯誤處理函數
POST請求
- 可以使用scrapy.FormRequest(url, formdata, callback)方法進行發送
- 如果希望程序執行一開始就發送POST請求,可以重寫Spider類的start_requests(self)方法,并且不再調用start_urls里的url。
- 如果想要預填充或重寫像用戶名、用戶密碼這些表單字段, 可以使用 scrapy.FormRequest.from_response(response, formdata, callback) 方法實現。
9、Downloader Middlewares(下載中間件)
下載中間件是處于引擎(crawler.engine)和下載器(crawler.engine.download())之間的一層組件,可以有多個下載中間件被加載運行。
當引擎傳遞請求給下載器的過程中,下載中間件可以對請求進行處理 (例如增加http header信息,增加proxy信息等);
在下載器完成http請求,傳遞響應給引擎的過程中, 下載中間件可以對響應進行處理(例如進行gzip的解壓等)
要激活下載器中間件組件,將其加入到settings.py中的DOWNLOADER_MIDDLEWARES 設置中。 該設置是一個字典(dict),鍵為中間件類的路徑,值為其中間件的順序(order)。例如:
DOWNLOADER_MIDDLEWARES = {
'myProject.middlewares.MyprojectDownloaderMiddleware': 543,
}
中間件組件是一個定義了以下一個或多個方法的Python類:
- process_request(self, request, spider):當每個request通過下載中間件時,該方法被調用。
- process_response(self, request, response, spider):當下載器完成http請求,傳遞響應給引擎的時候調用
示例:(使用隨機User-Agent和代理IP)
middlewares.py文件
import random
import json
import redis
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from myProject.settings import USER_AGENTS
class MyprojectDownloaderMiddleware:
def __init__(self):
self.r = redis.StrictRedis(host='localhost') #創建redis連接客戶端,用于取里面存儲的動態獲取的代理ip
def process_request(self, request, spider):
user_agent = random.choice(USER_AGENTS) #取隨機user-Agent
proxy_list = json.loads(self.r.get('proxy_list').decode())
proxy = random.choice(proxy_list) #取隨機ip
request.headers.setdefault("User-Agent",user_agent) #設置user-agent
request.meta['proxy'] ='http://'+proxy['ip']+':'+str(proxy['port']) #使用代理ip
修改settings.py文件配置
#禁用cookies
COOKIES_ENABLED = False
#設置下載延遲
DOWNLOAD_DELAY = 3
#添加自己寫的下載中間件類
DOWNLOADER_MIDDLEWARES = {
'myProject.middlewares.MyprojectDownloaderMiddleware': 543,
}
#添加USER-AGENTS
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
到此這篇關于Python爬蟲框架-scrapy的使用的文章就介紹到這了,更多相關Python爬蟲框架scrapy使用內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 上手簡單,功能強大的Python爬蟲框架——feapder
- python爬蟲框架feapder的使用簡介
- Python爬蟲框架之Scrapy中Spider的用法
- 一文讀懂python Scrapy爬蟲框架
- python Scrapy爬蟲框架的使用
- 詳解Python的爬蟲框架 Scrapy
- python3 Scrapy爬蟲框架ip代理配置的方法
- Python使用Scrapy爬蟲框架全站爬取圖片并保存本地的實現代碼
- Python爬蟲框架Scrapy實例代碼
- Python之Scrapy爬蟲框架安裝及簡單使用詳解
- 爬蟲框架 Feapder 和 Scrapy 的對比分析
