前言
觀前提醒:因為是代碼控制統計,所以操作每一個步驟都很重要,否則就會報錯。
操作步驟
1.將在線編輯文檔導入本地。
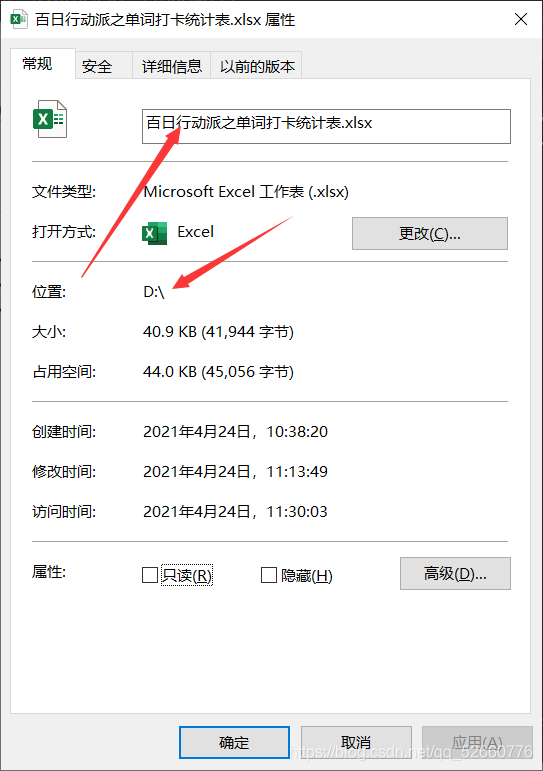
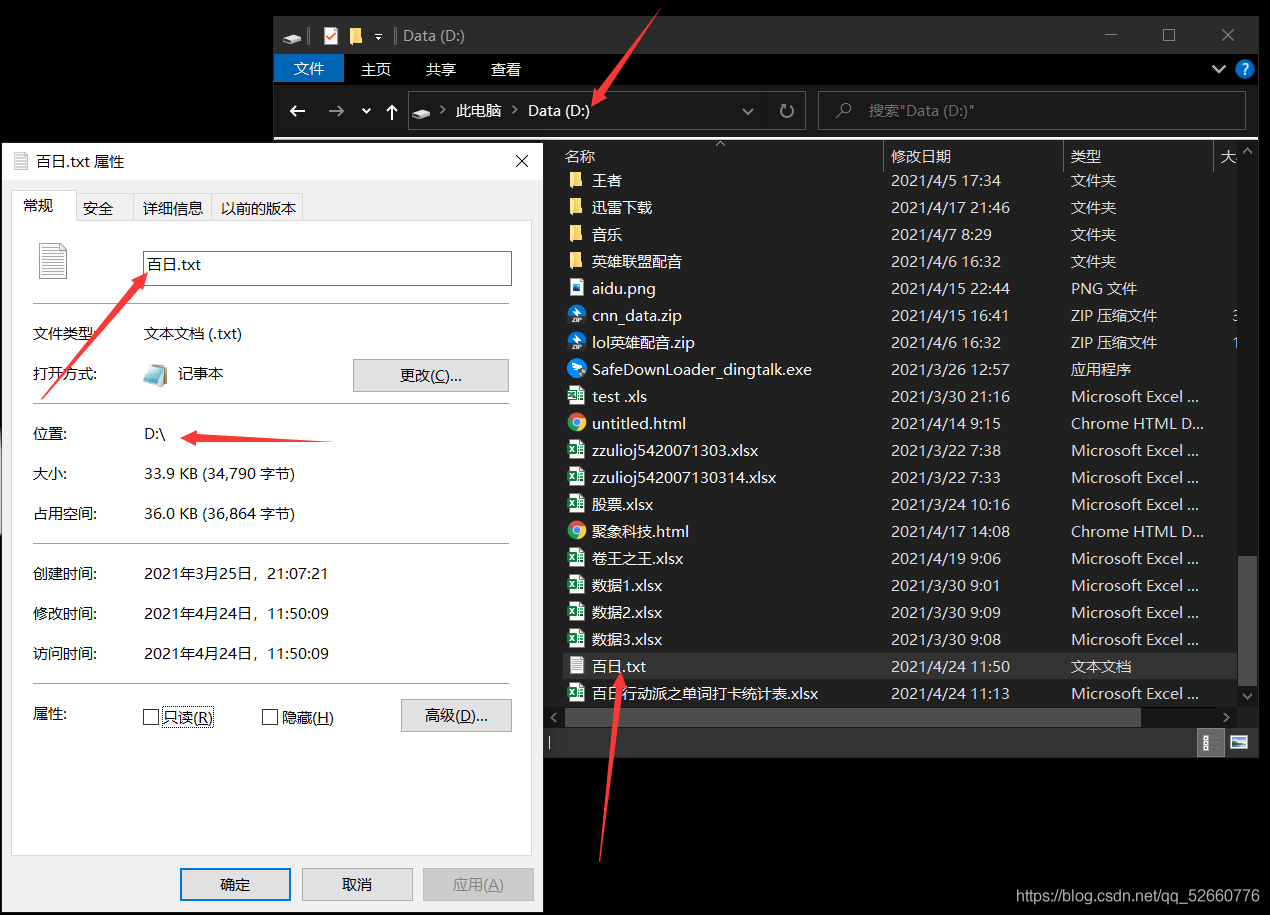
為了方便代碼處理,將導出的excel表統一放在D盤直路徑下,如果沒懂,你可以查看文件屬性,文件屬性應該是這樣:
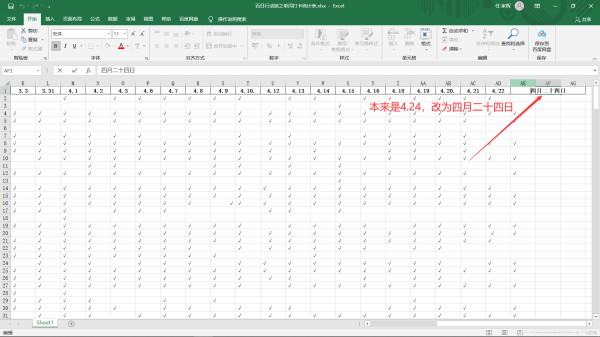
2.打開excel表,將你要統計的那天的日期改為中文(這一步很重要,因為數字索引無法進行定位,所以要改,不改就用不了)
3.因為QQ的安全防范機制做的太好了,爬蟲和抓包工具都無法獲取QQ信息,所以我只能采用最原始的方法進行數據獲取。
你想的沒錯,就是復制粘貼。用電腦打開百日單詞打卡群的相冊
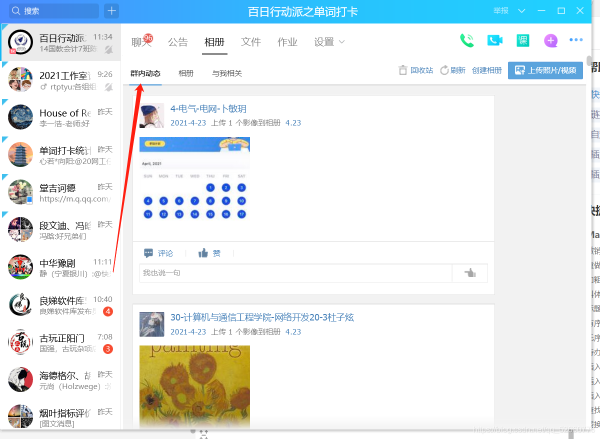
滑動滾輪,加載出統計日的所有上傳信息,然后CTRL+A全選,CTRL+C復制。
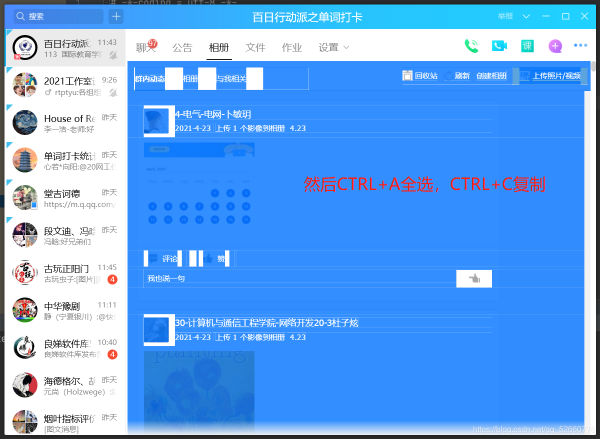
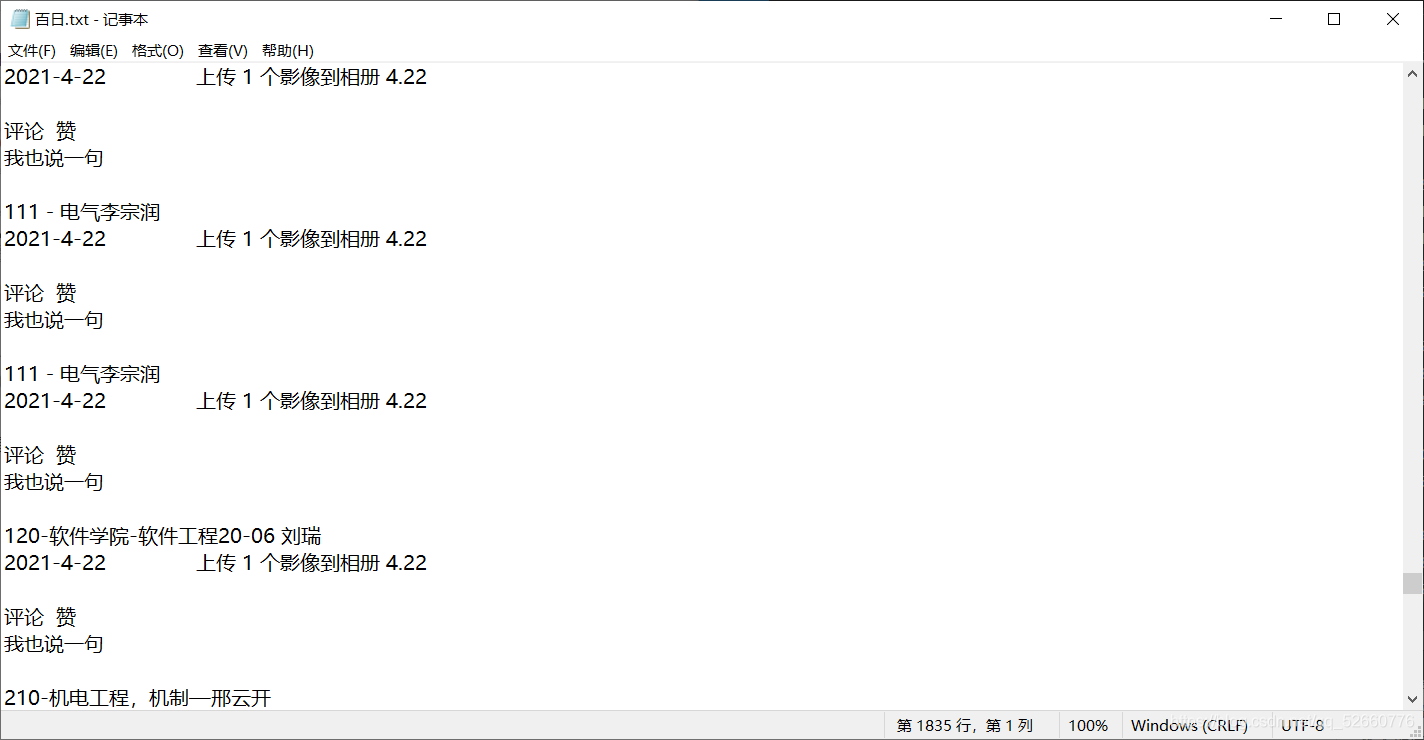
4.在D盤下,新建一個名字為:百日.txt 的文件將剛才復制的內容放進去。
5.運行代碼。所有上傳過背單詞圖片的人,就都在excel表里打上”√“了,但是為了防止有人想蒙混過關,我們再去相冊里大致瀏覽一下,找到不合格的然后在excel表里去除”√“,但總的來說這樣的情況還是極少數。
6.為了讓excel表里的格式保持一致,打開編輯好的excel表,然后將漢語日期再改回4.24格式。
7.將統計好的excel表上傳。
8.源代碼:
# -*-coding = utf-8 -*-
# @Time:2021/4/24/10:40
# @Author:seven
# @File:自填.py
# @Software:PyCharm
import pandas as pd
import re
day=input("請輸入你要統計的日期(例:4.23):")
DAY=input("請輸入的更改后的列名(例:四月二十三日):")
findlink=re.compile("贊我也說一句.*?([\u4e00-\u9fa5]{3})2021-.*? 上傳 1 個影像到相冊 "+day)
with open("D:/百日.txt","r",encoding="utf-8") as fd:
a=fd.readlines()
w=''
for i in a:
i=i.strip()
w+=i
names=re.findall(findlink,w)
path="D:/百日行動派之單詞打卡統計表.xlsx"
df=pd.read_excel(path,engine="openpyxl")
name=df.loc[0:,"姓名"]
day=df.loc[0:,DAY]
days=[]
for i in day:
days.append(i)
namelist=[]
for i in name:
namelist.append(i)
list=[]
for i in names:
try:
n=namelist.index(i)
list.append(n)
except:
print(i)
for i in list:
days[i]="√"
df.loc[0:,"四月二十四日"]=days
df.to_excel(path)
w=input("以上同學因備注格式不符未能自動統計,請自行統計")
9.如果你有使用python,可以打開編譯器導入相關庫后運行代碼,如果你沒有python,可以使用封裝后的程序。
到此這篇關于Python實戰之單詞打卡統計的文章就介紹到這了,更多相關python單詞打卡統計內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python 統計數據集標簽的類別及數目操作
- Python統計可散列的對象之容器Counter詳解
- Python 統計列表中重復元素的個數并返回其索引值的實現方法
- python之cur.fetchall與cur.fetchone提取數據并統計處理操作
- python自動統計zabbix系統監控覆蓋率的示例代碼
- python 統計代碼耗時的幾種方法分享
- Python統計列表元素出現次數的方法示例
- python統計RGB圖片某像素的個數案例
- Python jieba 中文分詞與詞頻統計的操作
- 利用Python3實現統計大量單詞中各字母出現的次數和頻率的方法
- 使用Python 統計文件夾內所有pdf頁數的小工具
- python 統計list中各個元素出現的次數的幾種方法
- python調用百度AI接口實現人流量統計
- Python代碼覆蓋率統計工具coverage.py用法詳解
- python 爬蟲基本使用——統計杭電oj題目正確率并排序
- 利用python匯總統計多張Excel
- python統計mysql數據量變化并調用接口告警的示例代碼
- 用python實現監控視頻人數統計
