目錄
- 1.引言
- 2.獲取目標網站
- 3.爬取目標網站
- 4.解析爬取內容
- 4.1. 解析全國今日總況
- 4.2. 解析全國各省份疫情情況
- 4.3. 解析江蘇各地級市疫情情況
- 5.結果可視化
- 6. 代碼
- 7. 參考
1.引言
最近江蘇南京、湖南張家界陸續爆發疫情,目前已波及8省22市,全國共有2個高風險地區,52個中風險地區。身在南京,作為兢兢業業的打工人,默默地成為了“蘇打綠”。為了關注疫情狀況,今天我們用python來爬一爬疫情的實時數據。
2.獲取目標網站
為了使用python來獲取疫情數據,我們需要找一個疫情實時追蹤數據發布網站,國內比較有名的是騰訊新聞、網易新聞等,這些網站疫情內容都大同小異,主要包括國內疫情、海外疫情,每日新增確診趨勢,疫苗接種情況等,這里我們選用騰訊新聞疫情發布頁來進行數據爬取分析。
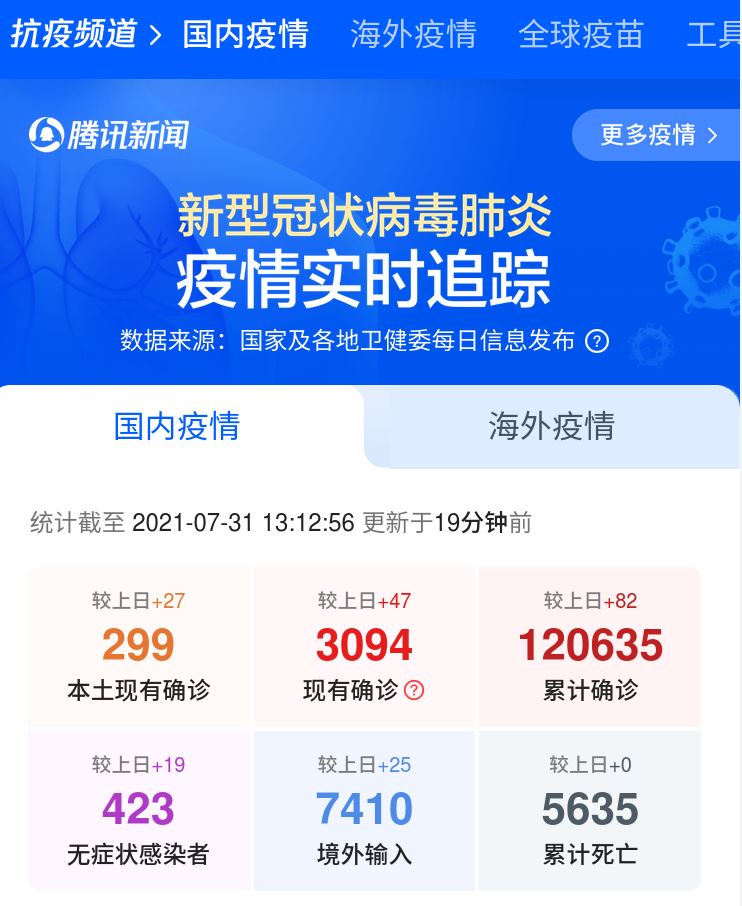
網站分析:
- 使用chrome瀏覽器 打開疫情發布頁網址 ,如上圖所示
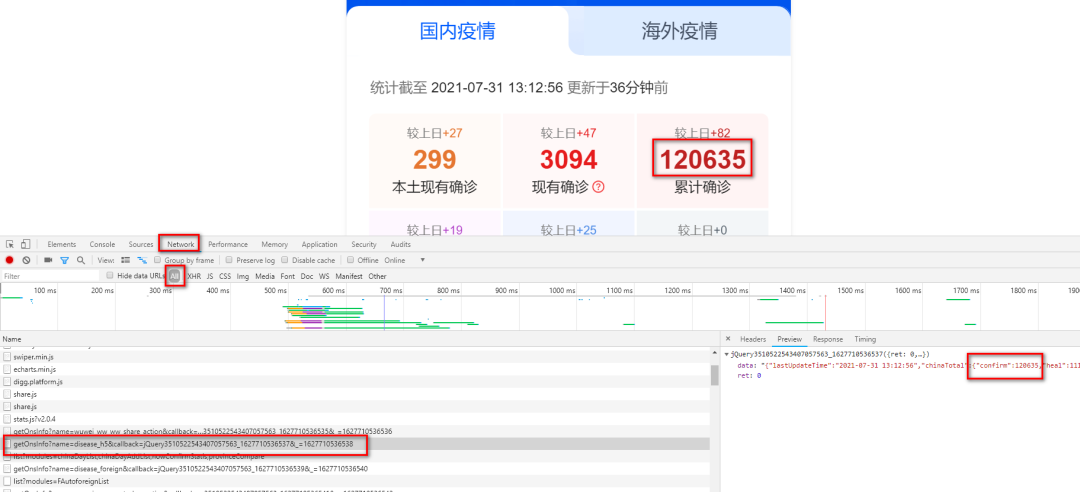
- 我們按F12 進入開發者模式,按 ctrl+R 刷新頁面
- 在Network下找到 getOnsInfo?name=disease_h5列,獲得爬取目標網址
3.爬取目標網站
我們寫爬蟲爬取網站數據,需要安裝request庫,安裝命令如下:
pip3 install requests
只需要三行代碼就可以獲取該網頁內容,代碼如下:
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
req = requests.get(url=url)
content = json.loads(req.text)
打印爬去結果如下:
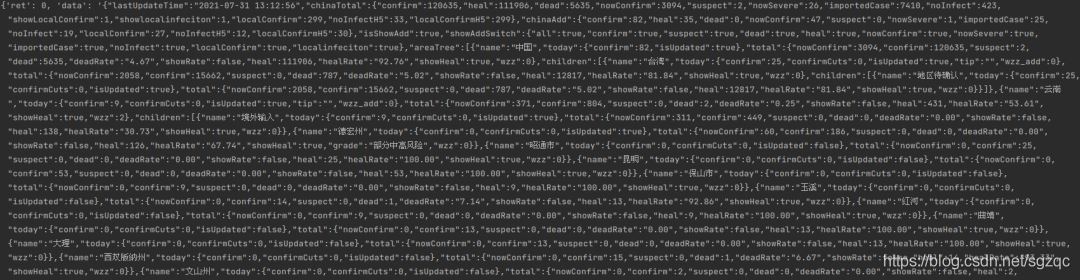
4.解析爬取內容
上述網站內容我們雖然爬取成功,接下來我們需要對爬取的結果進行解析,從中找出我們感興趣的部分。
4.1. 解析全國今日總況

相應的解析代碼如下:
def get_all_china(content):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
country = area_data[0]
country_list = []
name = country["name"]
today_confirm = country["today"]["confirm"]
now_confirm = country["total"]["nowConfirm"]
total_confirm = country["total"]["confirm"]
total_heal = country["total"]["heal"]
country_list.append([name, today_confirm, now_confirm, total_confirm, total_heal])
return country_list
打印結果如下:

輸出太丑了,這里使用PrettyTable庫對輸出進行美化,代碼如下:
def format_list_prettytable(title,province_list):
table = PrettyTable(title)
for province in province_list:
table.add_row(province)
table.border = True
return table
結果如下:

4.2. 解析全國各省份疫情情況
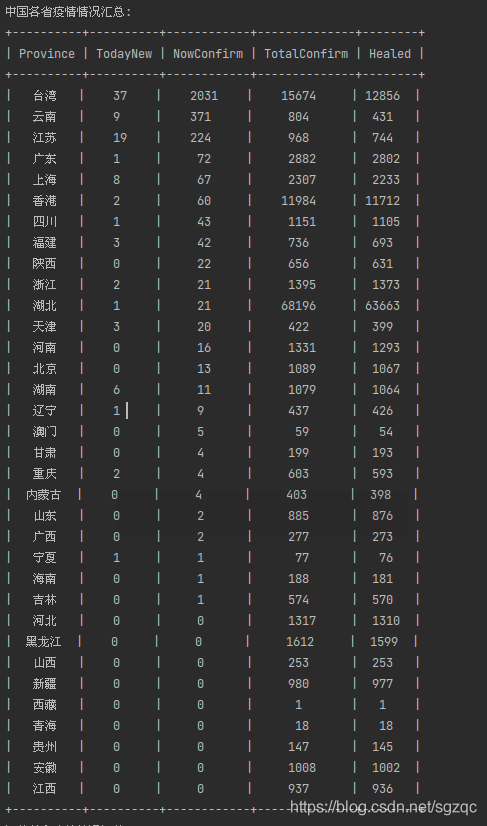
依次類推,可解析全國各省市疫情情況,代碼如下:
def get_all_province(content):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
data = area_data[0]['children']
province_list = []
for province in data:
name = province["name"]
today_confirm = province["today"]["confirm"]
now_confirm = province["total"]["nowConfirm"]
total_confirm = province["total"]["confirm"]
total_heal = province["total"]["heal"]
province_list.append([name, today_confirm, now_confirm, total_confirm, total_heal])
return province_list
結果如下:
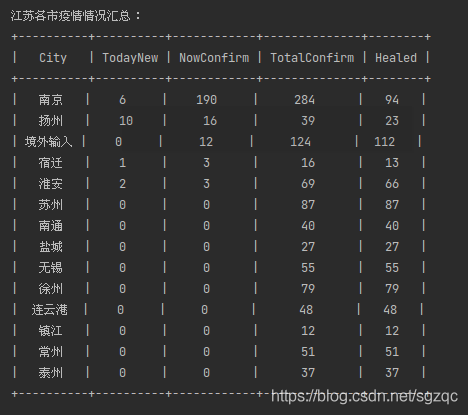
4.3. 解析江蘇各地級市疫情情況
最后,我們獲取江蘇省各地級市的疫情數據,代碼如下:
def parse_jiangsu_province(content,key_province):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
data = area_data[0]['children']
city_list = []
for province in data:
name = province["name"]
if name == key_province:
children_list = province["children"]
for children in children_list:
city = children["name"]
today_new = children["today"]["confirm"]
now_confirm = children["total"]["nowConfirm"]
total_confirm = children["total"]["confirm"]
total_heal = children["total"]["heal"]
city_list.append([city, today_new, now_confirm, total_confirm, total_heal])
return city_list
結果如下:
5.結果可視化
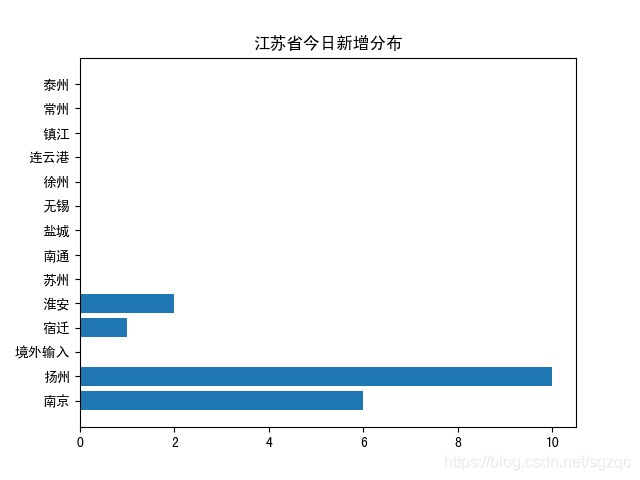
使用matplotlib對上述爬去的江蘇各地級市疫情分布可視化,得到結果如下:
今日新增可視化結果如下:
現有確診可視化結果如下:
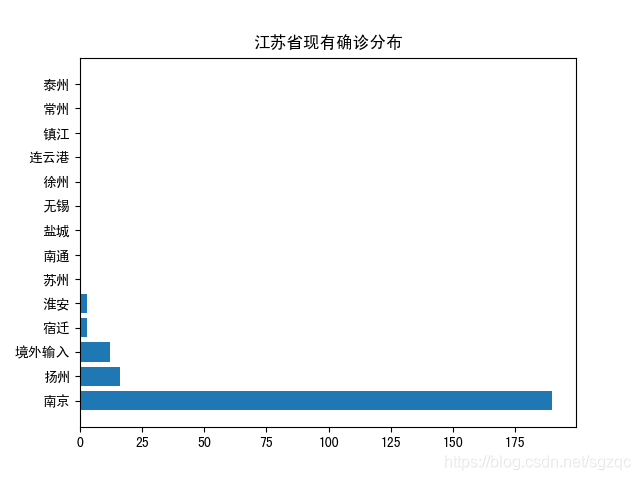
從上述圖表可以看出,今日疫情已擴散至揚州,揚州今日新增感染人數最多,需引起重視。
6. 代碼
完整代碼
https://github.com/sgzqc/wechat/tree/main/20210731
7. 參考
鏈接一
到此這篇關于Python獲取江蘇疫情實時數據及爬蟲分析的文章就介紹到這了,更多相關Python江蘇疫情內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 關于python爬蟲應用urllib庫作用分析
- python爬蟲Scrapy框架:媒體管道原理學習分析
- python爬蟲Mitmproxy安裝使用學習筆記
- Python爬蟲和反爬技術過程詳解
- python爬蟲之Appium爬取手機App數據及模擬用戶手勢
- 爬蟲Python驗證碼識別入門
- Python爬蟲技術
- Python爬蟲爬取商品失敗處理方法
- Python爬蟲之Scrapy環境搭建案例教程
- Python爬蟲中urllib3與urllib的區別是什么
- 教你如何利用python3爬蟲爬取漫畫島-非人哉漫畫
- Python爬蟲分析匯總
