為什么要對URL進行encode
在寫網絡爬蟲時,發現提交表單中的中文字符都變成了TextBox1=%B8%C5%C2%CA%C2%DB這種樣子,觀察這是中文對應的GB2312編碼,實際上是進行了GB2312編碼和urlencode。
那么為什么要對URL進行encode?
因為在標準的url規范中中文和很多的字符是不允許出現在url中的。為了字符編碼(gbk、utf-8)和特殊字符不出現在url中,url轉義是為了符合url的規范。
具體代碼
urlencode編碼:urllib中的quote方法
import urllib.parse
chinese_str = '中文'
# 先進行gb2312編碼
chinese_str = chinese_str.encode('gb2312')
# 輸出 b'\xd6\xd0\xce\xc4'
# 再進行urlencode編碼
chinese_str_url = urllib.parse.quote(chinese_str)
# 輸出 %D6%D0%CE%C4
urldecode解碼:urllib中的unquote方法
# 由于編碼問題會報錯,還未解決
urllib.parse.unquote('%D6%D0%CE%C4')
# :的url編碼為%3A,可輸出 http://www.baidu.com
urllib.parse.unquote('http%3A//www.baidu.com')
其它應用
URL中%u開頭的字符
在網頁的表單參數中,還遇到過%u開頭的字符,得知是中文對應的Unicode編碼值
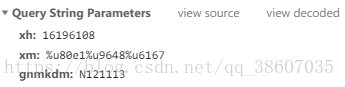
以下代碼可以實現字符與unicode編碼值的轉換
str = '姓名'
# 獲得urlencode編碼
str = str.encode('unicode_escape')
print(str)
# 輸出 b'\\u59d3\\u540d'
str=str.decode('utf-8')
print(str)
# 輸出 \u59d3\u540d
str=str.encode('utf-8')
print(str)
# 輸出 b'\\u59d3\\u540d'
str=str.decode('unicode_escape')
print(str)
# 輸出 姓名
hidden隱藏域對象作為表單參數
在爬取ASP.NET平臺的網站信息時,有VIEWSTATE、EVENTVALIDATION這樣的hidden隱藏域對象,作為表單參數發送post請求,所以需要從網頁源代碼中獲取。
但post請求中的參數值是URL編碼值,而網頁源碼中獲取到的是URL解碼值,所以需要進行urlencode編碼。
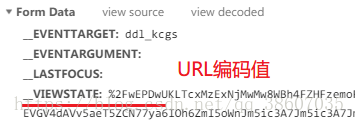
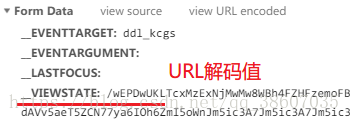

相關代碼
# 網頁源碼上得到之后,需要urlencode編碼
hid['VIEWSTATE'] = urllib.parse.quote(soup.find(id="__VIEWSTATE")['value'])
相關工具
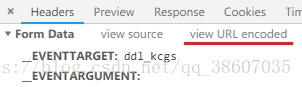
谷歌瀏覽器的開發者工具中可以查看參數的urlencode和decode值

在線URL編碼/解碼工具
可選擇編碼格式為UTF-8或GB2312
漢字字符集編碼查詢
可查漢字的GB2312等中文編碼和Unicode編碼
參考鏈接
python中的urlencode和urldecode(代碼)
到此這篇關于Python之進行URL編碼案例講解的文章就介紹到這了,更多相關Python之進行URL編碼內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 詳解python中文編碼問題
- python基礎之編碼規范總結
- Python3 json模塊之編碼解碼方法講解
- 解決python3 中的np.load編碼問題
- python 編碼中為什么要寫類型注解?
- python源文件的字符編碼知識點詳解
- Python新建項目自動添加介紹和utf-8編碼的方法
- python中字符串的編碼與解碼詳析
