目錄
- 人臉圖像特征提取方法
- (一)HOG特征提取
- (二)Dlib庫
- (三)卷積神經網絡特征提取(CNN)
人臉圖像特征提取方法
(一)HOG特征提取
1、HOG簡介
Histogram of Oriented Gridients,縮寫為HOG,是目前計算機視覺、模式識別領域很常用的一種描述圖像局部紋理的特征。它的主要思想是在一副圖像中,局部目標的表象和形狀能夠被梯度或邊緣的方向密度分布很好地描述。其本質為:梯度的統計信息,而梯度主要存在于邊緣的地方。
2、實現方法
首先將圖像分成小的連通區域,這些連通區域被叫做細胞單元。然后采集細胞單元中各像素點的梯度的或邊緣的方向直方圖。最后把這些直方圖組合起來,就可以構成特征描述符。將這些局部直方圖在圖像的更大的范圍內(叫做區間)進行對比度歸一化,可以提高該算法的性能,所采用的方法是:先計算各直方圖在這個區間中的密度,然后根據這個密度對區間中的各個細胞單元做歸一化。通過這個歸一化后,能對光照變化和陰影獲得更好的效果。
3、HOG特征提取優點
由于HOG是 在圖像的局部方格單元上操作,所以它對圖像幾何的和光學的形變都能保持很好的不變性,這兩種形變只會出現在更大的空間領域上。在粗的空域抽樣、精細的方向抽樣以及較強的局部光學歸一化等條件下,只要行人大體上能夠保持直立的姿勢,可以容許行人有一些細微的肢體動作,這些細微的動作可以被忽略而不影響檢測效果。HOG特征是特別適合于做圖像中的人體檢測的 。
4、HOG特征提取步驟
(1)色彩和伽馬歸一化
為了減少光照因素的影響,首先需要將整個圖像進行規范化(歸一化)。在圖像的紋理強度中,局部的表層曝光貢獻的比重較大,所以,這種壓縮處理能夠有效地降低圖像局部的陰影和光照變化。
(2)計算圖像梯度
計算圖像橫坐標和縱坐標方向的梯度,并據此計算每個像素位置的梯度方向值;求導操作不僅能夠捕獲輪廓,人影和一些紋理信息,還能進一步弱化光照的影響。最常用的方法是:簡單地使用一個一維的離散微分模板在一個方向上或者同時在水平和垂直兩個方向上對圖像進行處理,更確切地說,這個方法需要使用濾波器核濾除圖像中的色彩或變化劇烈的數據
(3)構建方向直方圖
細胞單元中的每一個像素點都為某個基于方向的直方圖通道投票。投票是采取加權投票的方式,即每一票都是帶有權值的,這個權值是根據該像素點的梯度幅度計算出來。可以采用幅值本身或者它的函數來表示這個權值,實際測試表明: 使用幅值來表示權值能獲得最佳的效果,當然,也可以選擇幅值的函數來表示,比如幅值的平方根、幅值的平方、幅值的截斷形式等。細胞單元可以是矩形的,也可以是星形的。直方圖通道是平均分布在0-1800(無向)或0-3600(有向)范圍內。經研究發現,采用無向的梯度和9個直方圖通道,能在行人檢測試驗中取得最佳的效果。
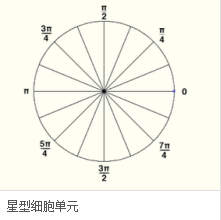
(4)將細胞單元組合成大的區間
由于局部光照的變化以及前景-背景對比度的變化,使得梯度強度的變化范圍非常大。這就需要對梯度強度做歸一化。歸一化能夠進一步地對光照、陰影和邊緣進行壓縮。
采取的辦法是:把各個細胞單元組合成大的、空間上連通的區間。這樣,HOG描述符就變成了由各區間所有細胞單元的直方圖成分所組成的一個向量。這些區間是互有重疊的,這就意味著:每一個細胞單元的輸出都多次作用于最終的描述器。
區間有兩個主要的幾何形狀——矩形區間(R-HOG)和環形區間(C-HOG)。R-HOG區間大體上是一些方形的格子,它可以有三個參數來表征:每個區間中細胞單元的數目、每個細胞單元中像素點的數目、每個細胞的直方圖通道數目。
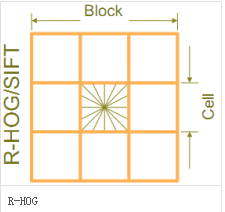
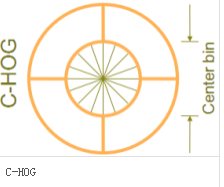
(5)收集HOG特征
把提取的HOG特征輸入到SVM分類器中,尋找一個最優超平面作為決策函數。
(二)Dlib庫
1、Dlib簡介
Dlib是一個現代化的C ++工具箱,其中包含用于在C ++中創建復雜軟件以解決實際問題的機器學習算法和工具。它廣泛應用于工業界和學術界,包括機器人,嵌入式設備,移動電話和大型高性能計算環境。Dlib的開源許可證允許您在任何應用程序中免費使用它。
2、Dlib特點
文檔齊全高質量的可移植代碼提供大量的機器學習和圖像處理算法
(三)卷積神經網絡特征提取(CNN)
1、卷積神經網絡簡介
卷積神經網絡(Convolutional Neural Network)簡稱CNN,CNN是所有深度學習課程、書籍必教的模型,CNN在影像識別方面的為例特別強大,許多影像識別的模型也都是以CNN的架構為基礎去做延伸。另外值得一提的是CNN模型也是少數參考人的大腦視覺組織來建立的深度學習模型,學會CNN之后,對于學習其他深度學習的模型也很有幫助,本文主要講述了CNN的原理以及使用CNN來達成99%正確度的手寫字體識別。
2、CNN網絡結構
基礎的CNN由 卷積(convolution), 激活(activation), and 池化(pooling)三種結構組成。CNN輸出的結果是每幅圖像的特定特征空間。當處理圖像分類任務時,我們會把CNN輸出的特征空間作為全連接層或全連接神經網絡(fully connected neural network, FCN)的輸入,用全連接層來完成從輸入圖像到標簽集的映射,即分類。當然,整個過程最重要的工作就是如何通過訓練數據迭代調整網絡權重,也就是后向傳播算法。目前主流的卷積神經網絡(CNNs),比如VGG, ResNet都是由簡單的CNN調整,組合而來。
(1)CNN
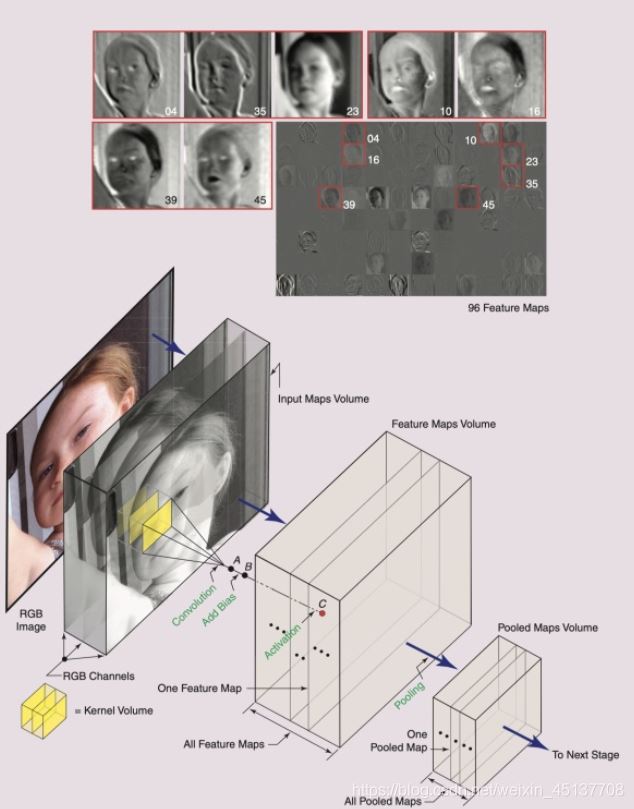
圖中,一個stage中的一個CNN,通常會由三種映射空間組成:
輸入映射空間(input maps volume)特征映射空間(feature maps volume)池化映射空間(pooled maps volume)
(2)卷積

注意卷積層的kernel可能不止一個,掃描步長,方向也有不同,進階方式如下:
可以采用多個卷積核,設為n 同時掃描,得到的feature map會增加n個維度,通常認為是多抓取n個特征。可以采取不同掃描步長,比如上例子中采用步長為n, 輸出是(510/n,510/n)padding,上例里,卷積過后圖像維度是縮減的,可以在圖像周圍填充0來保證feature map與原始圖像大小不變深度升降,例如采用增加一個1*1 kernel來增加深度,相當于復制一層當前通道作為feature map跨層傳遞feature map,不再局限于輸入即輸出, 例如ResNet跨層傳遞特征,Faster RCNN 的POI pooling
(3)激活

(4)池化
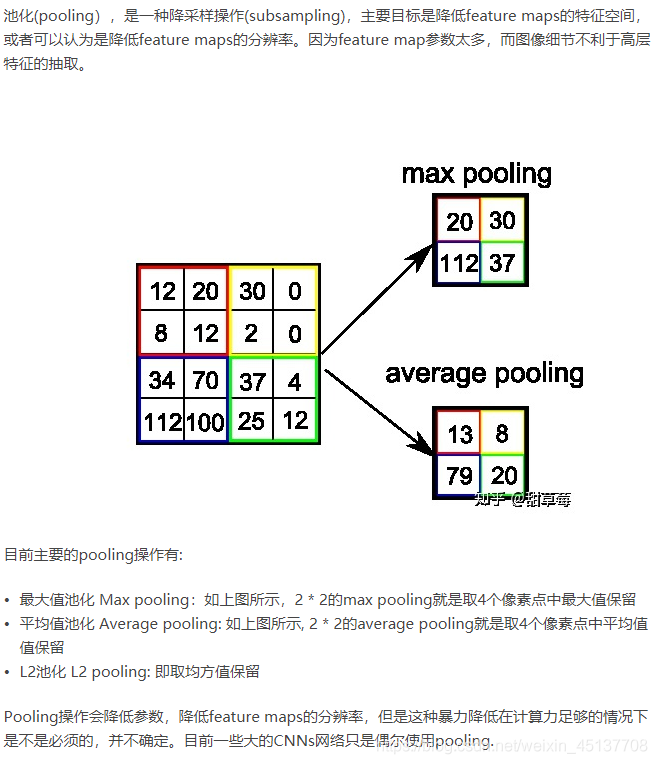
(5)全連接網絡
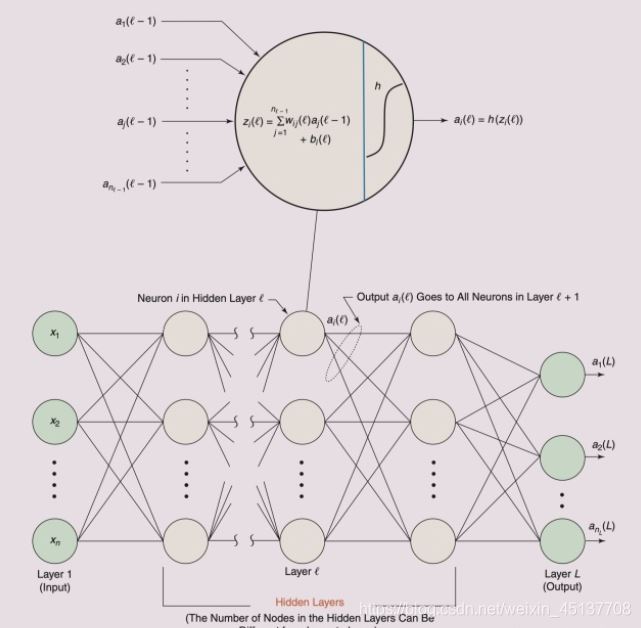
出現在CNN中的全連接網絡(fully connected network)主要目的是為了分類, 這里稱它為network的原因是,目前CNNs多數會采用多層全連接層,這樣的結構可以被認為是網絡。如果只有一層,下邊的敘述同樣適用。它的結構如下:

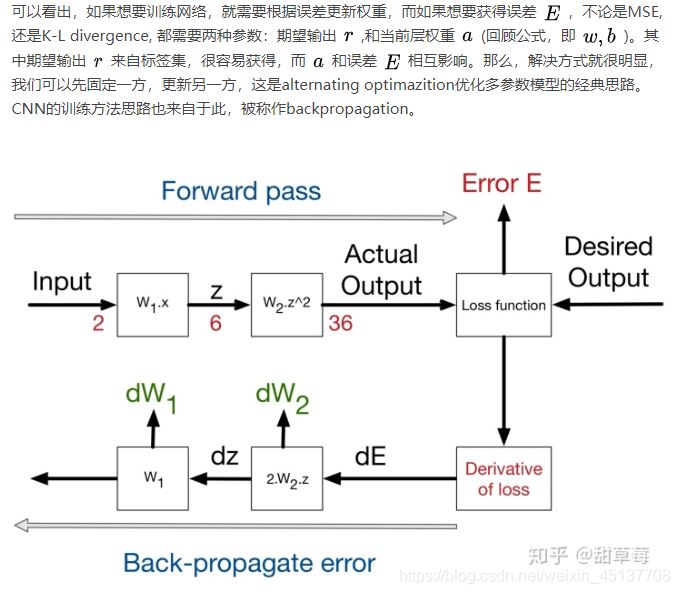
(6)目標函數和訓練方法



到此這篇關于Python中人臉圖像特征提取方法(HOG、Dlib、CNN)簡述的文章就介紹到這了,更多相關python人臉圖像特征提取內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python+opencv3.4.0 實現HOG+SVM行人檢測的示例代碼
