目錄
- 前言
- 1. 正則表達式的基本概念
- 2. python的正則表達式re模塊
- 3. 正則表達式語法
- (1)匹配單個字符
- (2)匹配多個字符
- (3)邊界匹配
- (4)分組匹配
- 4. re模塊相關方法使用
- 總結
前言
有時候字符串匹配解決不了問題,這個時候就需要正則表達式來處理。因為每一次匹配(比如找以什么開頭的,以什么結尾的字符串要寫好多個函數)都要單獨完成,我們可以給它制定一個規則。
主要應用:爬蟲的時候需要爬取各種信息,使用正則表達式可以很方便的處理需要的數據。
1. 正則表達式的基本概念
- 使用單個字符串來描述匹配一系列符合某個語法規則的字符串。
- 是對字符串操作的一種邏輯公式。
- 應用場景:處理文本和數據。
- 正則表達式過程:依次拿出表達式和文本中的字符比較,如果每一個字符都能匹配,則匹配成功,否則失敗。
2. python的正則表達式re模塊
匹配過程:r'imooc'是原字符串,先生成Pattern對象,從頭開始找,得到一個Match(或Search等)實例,最后有一個匹配結果。

# 用find和startswith找字符串
str1 = 'imooc python'
print(str1.find('11'))
-1
print(str1.find('imooc'))
0
print(str1.startswith('imooc'))
True
使用正則表達式:
import re
pa = re.compile(r'imooc') # compile生成一個pattern對象,r'imooc'讀原字符串,否則需要轉義
ma = pa.match(str1) # 匹配不到返回為None,返回一個對象
print(ma)
re.Match object; span=(0, 5), match='imooc'>
print(ma.group()) # 返回一個字符串或字符串組成的元組ma.groups()
imooc
print(ma.span()) # 返回所在字符串的位置
print(ma.string) # 返回原字符串
print(ma.re) # 返回實例
(0, 5)
imooc python
re.compile('imooc')
# 匹配大小寫,后面加上大寫
pa = re.compile(r'imooc', re.I)
print(pa)
re.compile('imooc', re.IGNORECASE)
ma = pa.match('imooc python')
print(ma.group())
imooc
ma = pa.match('Imooc python')
print(ma.group())
Imooc
# 如果只有一個,可以直接生成一個match對象,也可以達到同樣的效果
ma = re.match(r'imooc', str1)
print(ma)
print(ma.group())
re.Match object; span=(0, 5), match='imooc'>
imooc
3. 正則表達式語法
基本語法:適用于多種語言。
(1)匹配單個字符
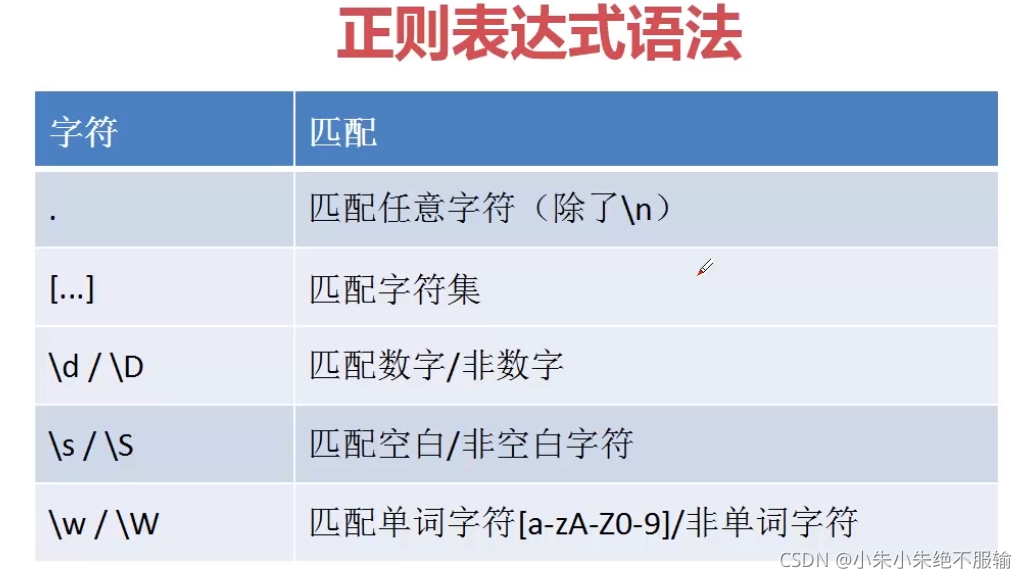
1)'.' 的匹配,可以匹配除了\n外所有字符
ma = re.match(r'a', 'a')
print(ma.group())
ma = re.match(r'a', 'b')
print(type(ma)) # 再調ma.group()則報錯
a
class 'NoneType'>
# 用.匹配字符
ma = re.match(r'.', 'b')
print(ma.group())
ma = re.match(r'.', '0')
print(ma.group())
b
0
# 匹配{}中的字符
ma = re.match(r'{.}', '{0}')
print(ma.group())
ma = re.match(r'{..}', '{01}')
print(ma.group())
{0}
{01}
2)[…]匹配字符集
# []匹配字符集
ma = re.match(r'{[abc]}', '{a}')
print(ma.group())
ma = re.match(r'{[abc]]}', 'p3xx3zz') # 匹配不到,則報錯
print(ma.group())
ma = re.match(r'{[a-z]]}', '73zzpph')
print(ma.group()) # 匹配a-z中任意一個字符
{a}
7p7zxxx
ma = re.match(r'{[a-zA-Z]}', '{A}')
print(ma.group())
{A}
ma = re.match(r'{[a-zA-Z0-9]}', '{0}')
print(ma.group())
{0}
3) \w 匹配a-zA-Z0-9, \W匹配非單詞字符
ma = re.match(r'{[\w]}', '{A}')
print(ma.group())
ma = re.match(r'{[\w]}', '{ }')
print(ma.group()) # 匹配不到
ma = re.match(r'{[\W]}', '{ }')
print(ma.group())
{A}
{ }
4)字符集[]匹配
ma = re.match(r'[[\w]]', '[a]')
print(ma.group()) # 匹配不到
# 匹配[]需要加轉義\
ma = re.match(r'\[[\w]\]', '[a]')
print(ma.group())
[a]
(2)匹配多個字符
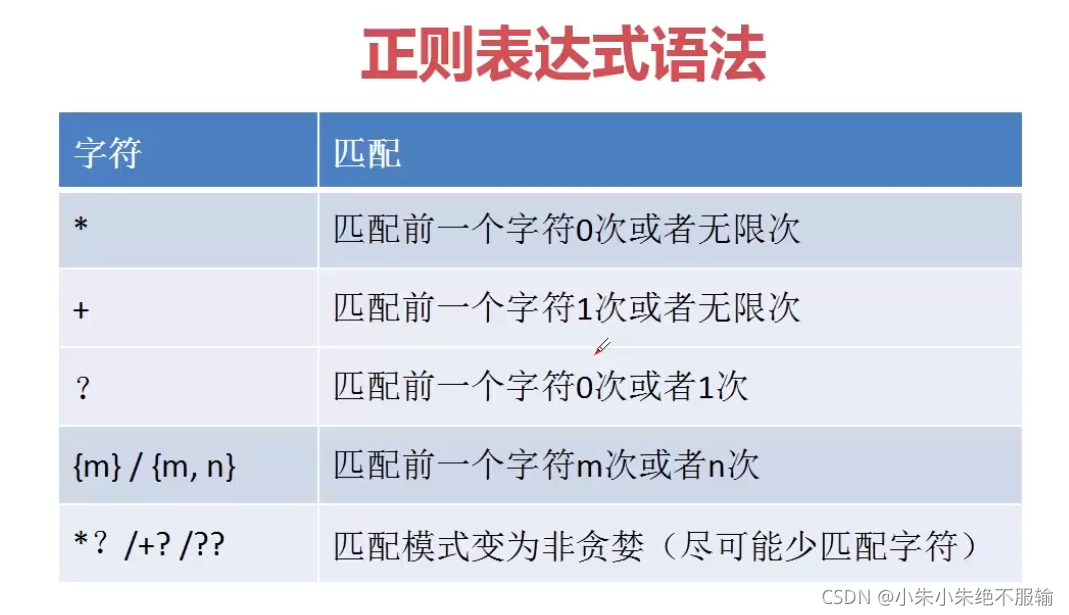
1) *匹配
ma = re.match(r'[A-Z][a-z]', 'Aa')
print(ma.group())
ma = re.match(r'[A-Z][a-z]', 'A')
print(ma.group()) # 匹配不到
ma = re.match(r'[A-Z][a-z]*', 'Aa')
print(ma.group())
ma = re.match(r'[A-Z][a-z]*', 'Aagfagsagaha')
print(ma.group())
ma = re.match(r'[A-Z][a-z]*', 'Aa123')
print(ma.group())
Aa
A
Aagfagsagaha
Aa
2)+匹配
# 匹配下劃線或字符開頭的無限次
ma = re.match(r'[_a-zA-Z]+[_\w]*', '10')
print(ma.group()) # 匹配不到
ma = re.match(r'[_a-zA-Z]+[_\w]*', '_hte10')
print(ma.group())
_hte10
3)?匹配
# 匹配0-99,01則不對
ma = re.match(r'[1-9]?[0-9]', '90')
print(ma.group())
ma = re.match(r'[1-9]?[0-9]', '9')
print(ma.group())
ma = re.match(r'[1-9]?[0-9]', '09')
print(ma.group()) # 只匹配到0
90
9
0
4){m} / {mn}匹配
# 匹配郵箱,匹配6次
ma = re.match(r'[a-zA-Z0-9]{6}', 'abc123')
print(ma.group())
abc123
ma = re.match(r'[a-zA-Z0-9]{6}', 'abc12')
print(ma.group()) # 少一個則匹配不到
ma = re.match(r'[a-zA-Z0-9]{6}', 'abc1234')
print(ma.group()) # 多則匹配前6個
abc123
ma = re.match(r'[a-zA-Z0-9]{6}@163.com', 'abc123@163.com')
print(ma.group())
abc123@163.com
# 匹配6-10位的郵箱
ma = re.match(r'[a-zA-Z0-9]{6, 10}@163.com', 'abc123@163.com')
print(ma.group())
4)*? /+? /??匹配 (盡可能少匹配)
ma = re.match(r'[0-9][a-z]*', '1abc')
print(ma.group())
ma = re.match(r'[0-9][a-z]*?', '1abc')
print(ma.group()) # 只匹配1
1abc
1
ma = re.match(r'[0-9][a-z]+?', '1abc')
print(ma.group()) # 只匹配一次
1a
(3)邊界匹配

ma = re.match(r'[\w]{4,10}@163.com', 'imooc@163.com')
print(ma.group())
imooc@163.com
ma = re.match(r'[\w]{4,10}@163.com', 'imooc@163.comabc') # 后面加上abc,match從頭開始匹配,則可以找到
print(ma.group())
imooc@163.com
ma = re.match(r'[\w]{4,10}@163.com', 'imooc@163.comabc')
print(ma.group()) # 匹配不到
ma = re.match(r'^[\w]{4,10}@163.com', 'imooc@163.comabc')
print(ma.group()) # 匹配不到
ma = re.match(r'^[\w]{4,10}@163.com', 'imooc@163.com')
print(ma.group()) # 加上^和$,限制開頭結尾
imooc@163.com
# 指定開頭結尾
ma = re.match(r'\Aimooc[\w]*', 'imoocpython')
print(ma.group())
ma = re.match(r'\Aimooc[\w]*', 'iimoocpython')
print(ma.group()) # 匹配不到
imoocpython
(4)分組匹配

這里不再舉例。
4. re模塊相關方法使用
以上舉例都是match,從頭到尾匹配,查找子串就不合適了
# 在一個字符串中查找匹配
1:search(pattern, string, flags=0)
# 找到匹配,返回所有匹配部分的列表
2:findall(pattern, string, flags=0)
# 將字符串中匹配正則表達式得部分替換為其它,repl可以替換函數
3:sub(pattern, repl, string, count=0, flags=0)
# 根據匹配分割字符串,返回分割字符串組成的列表
4:split(pattern, string, maxsplit=0, flags=0)
# search
import re
str1 = 'imooc videonum = 1000'
print(str1.find('1000')) # 數字改變則失效
17
info = re.search(r'\d+', str1)
print(info.group())
1000
str1 = 'imooc videonum = 10000'
info = re.search(r'\d+', str1)
print(info.group())
10000
# findall
# 當有多個數字時
str2 = 'a=100, b=200, c=300'
info = re.search(r'\d+', str2)
print(info.group())
100
info = re.findall(r'\d+', str2)
print(info.group())
[100, 200, 300]
# sub 替換
str3 = 'imooc videonum = 1000'
info = re.sub(r'\d+', '1001', str3)
print(info)
imooc videonum = 1001
# split
# 分割
str3 = 'imooc:C C++ Java'
print(re.split(r':| ', str4))
[imooc, C, C, Java]
以上即為python中的正則表達式的一些知識總結。
總結
到此這篇關于python正則表達式的文章就介紹到這了,更多相關python正則表達式內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 一篇文章帶你了解Python和Java的正則表達式對比
- 超詳細講解python正則表達式
- Python正則表達式保姆式教學詳細教程
- python正則表達式查找和替換內容的實例詳解
