目錄
- 1、神經網絡訓練過程
- 2、基礎概念
- 3、數據預處理手段
- 3.1 歸一化 (normalization)
- 3.2 標準化(Standardization)
- 3.3 正則化
- 3.4 獨熱碼編碼(one hot)
- 4、數據處理庫
- 4.1 numpy
- 4.2 pandas
- 4.3 matplotlib
- 5、訓練集、測試集,測試集
- 6、損失函數
- 7、優化器
- 8、激活函數
- 9、hello world
- 10、總結
推薦閱讀 點擊標題可跳轉
1、如何搭建pytorch環境的方法步驟
今天是第一篇文章,希望自己能堅持,加油。
深度神經網絡就是用一組函數去逼近原函數,訓練的過程就是尋找參數的過程。
1、神經網絡訓練過程
神經網絡的訓練過程如下:
- 收集數據,整理數據
- 實現神經網絡用于擬合目標函數
- 做一個真實值和目標函數值直接估計誤差的損失函數,一般選擇既定的損失函數
- 用損失函數值前向輸入值求導,
- 再根據導數的反方向去更新網絡參數(x),目的是讓損失函數值最終為0.,最終生成模型
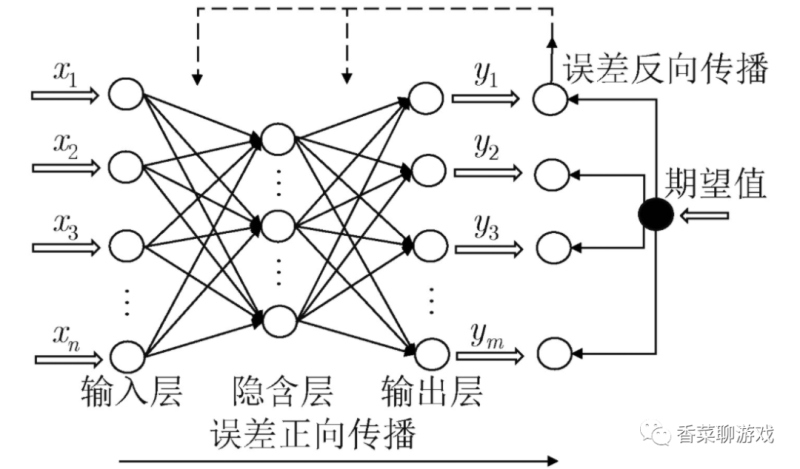
各層概念解釋
- 輸入層:就是參數輸入
- 輸出層:就是最后的輸出
- 隱藏層(隱含層):除去其他兩層之外的層都可以叫隱藏層
模型是什么:
- 模型包含兩部分,一部分是神經網絡的結構,一部分是各個參數,最后訓練的成果就是這個
2、基礎概念
2.1數學知識
2.1.1導數
導數在大學的時候還是學過的,雖然概念很簡單,但是過了這么多年幾乎也都忘了,連數學符號都不記得了,在復習之后才理解:就是表示數據變化的快慢,是變化率的概念,比如重力加速度,表示你自由落體之后每秒速度的增量。
數學公式是:
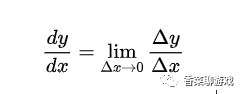
不重要,看不看的懂都行,因為在后面的學習中也不會讓你手動求導,框架里都有現成的函數
2.1.2 梯度
梯度的本意是一個向量(矢量),表示某一函數在該點處的方向導數沿著該方向取得最大值,即函數在該點處沿著該方向(此梯度的方向)變化最快,變化率最大(為該梯度的模)
梯度:是一個矢量,其方向上的方向導數最大,其大小正好是此最大方向導數。
2.2前向傳播和反向傳播
前向傳播就是前向調用,正常的函數調用鏈而已,沒什么特別的,破概念搞得神神秘秘的
比如
def a(input):
return y
def b(input):
return y2
# 前向傳播
def forward(input):
y = a(input)
y2 = b(y)
反向傳播
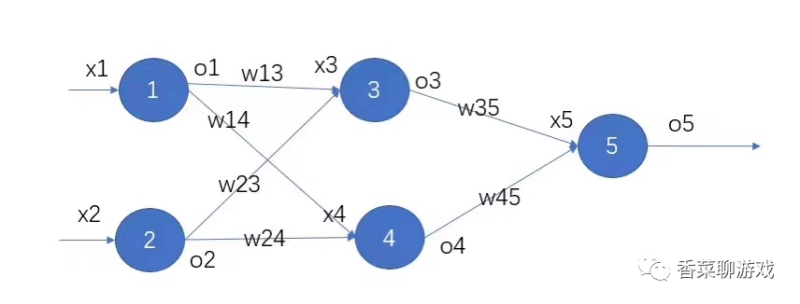
反向傳播就是根據誤差和學習率,將參數權重進行調整,具體的算法下次會專門寫一篇文章進行解析。
3、數據預處理手段
3.1 歸一化 (normalization)
將數據放縮到0~1區間,利用公式(x-min)/(max-min)
3.2 標準化(Standardization)
數據的標準化是將數據按比例縮放,使之落入一個小的特定區間。將數據轉化為標準的正態分布,均值為0,方差為1
3.3 正則化
正則化的主要作用是防止過擬合,對模型添加正則化項可以限制模型的復雜度,使得模型在復雜度和性能達到平衡。
3.4 獨熱碼編碼(one hot)
one hot編碼是將類別變量轉換為機器學習算法易于使用的一種形式的過程。one-hot通常用于特征的轉換
比如:一周七天,第三天可以編碼為 [0,0,1,0,0,00]
注:我把英語都補在了后面,并不是為了裝逼,只是為了下次看到這個單詞的時候知道這個單詞在表示什么。
4、數據處理庫
numpy ,pandas, matplotlib 這三個是數據分析常用的庫,也是深度學習中常用的三個庫
4.1 numpy
numpy 是優化版的python的列表,提高了運行效率,也提供了很多便利的函數,一般在使用的時候表示矩陣
numpy中的一個重要概念叫shape ,也就是表示維度
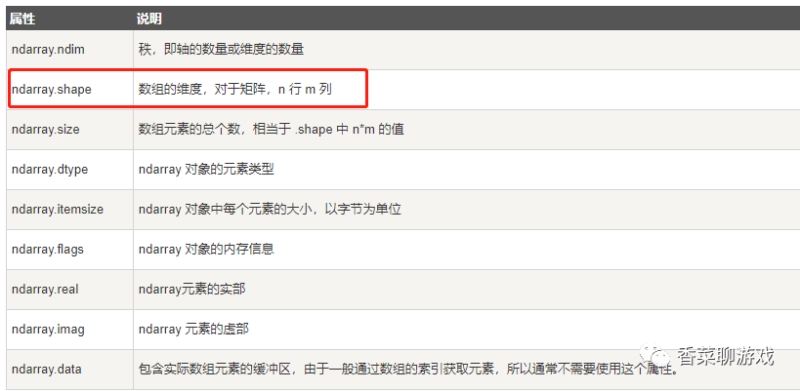
注:numpy 的api 我也使用不熟練,相信會在以后的學習過程中熟練的,使用的時候查一查,不用擔心。
4.2 pandas
Pandas 的主要數據結構是 Series (一維數據)與 DataFrame(二維數據).
[Series] 是一種類似于一維數組的對象,它由一組數據(各種Numpy數據類型)以及一組與之相關的數據標簽(即索引)組成。
DataFrame 是一個表格型的數據結構,它含有一組有序的列,每列可以是不同的值類型(數值、字符串、布爾型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 組成的字典(共同用一個索引)。
注:pandas 可以當做Excel使用,里面的api 我也使用不熟練,不用擔心,可以掃下核心概念就好
4.3 matplotlib
Matplotlib 是畫圖用的,可以用來在學習的過程中對數據進行可視化,我還沒有學習這個庫,只會照貓畫虎,所以放輕松,只是告訴你有這么個東西,不一定現在就要掌握
5、訓練集、測試集,測試集
訓練集:用來訓練模型的數據,用來學習的
驗證集:用來驗證模型的數據,主要是看下模型的訓練情況
測試集: 訓練完成之后,驗證模型的數據
一般數據的比例為6:2:2
一個形象的比喻:
訓練集----學生的課本;學生 根據課本里的內容來掌握知識。
驗證集----作業,通過作業可以知道 不同學生學習情況、進步的速度快慢。
測試集----考試,考的題是平常都沒有見過,考察學生舉一反三的能力。
6、損失函數
損失函數用來評價模型的預測值和真實值不一樣的程度,損失函數越好,通常模型的性能越好。不同的模型用的損失函數一般也不一樣.

注:f(x) 表示預測值,Y 表示真實值,
這些只是常用的損失函數,實現不同而已,在后面的開發理解各個函數就行了,API caller 不用理解具體的實現,就像你知道快速排序的算法原理,但是沒必要自己去實現,現成的實現拿來用不香嗎?
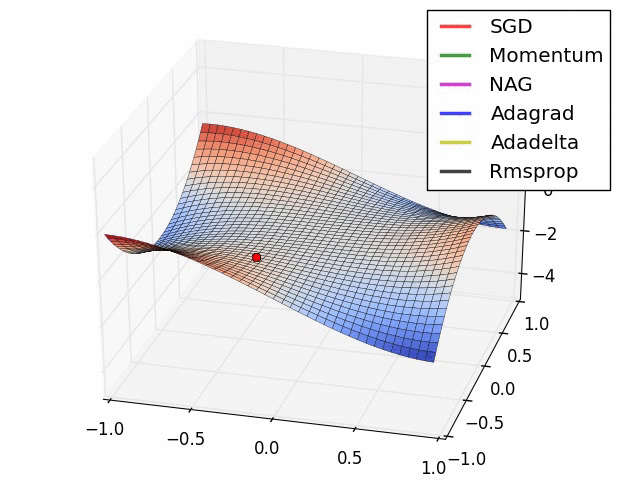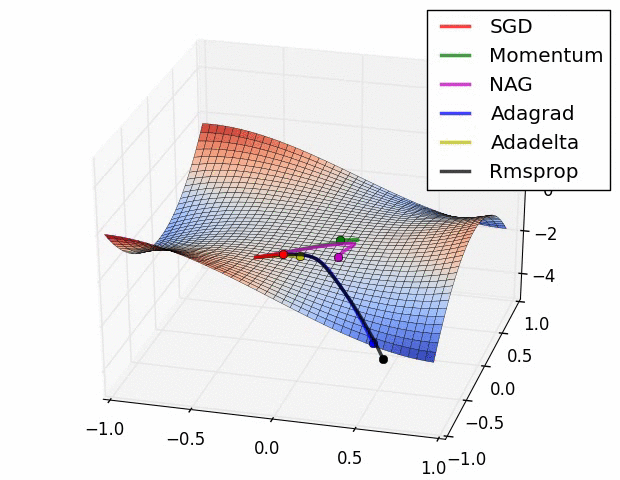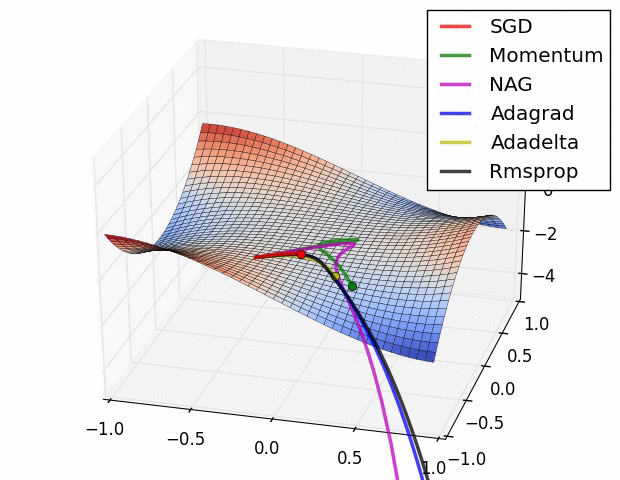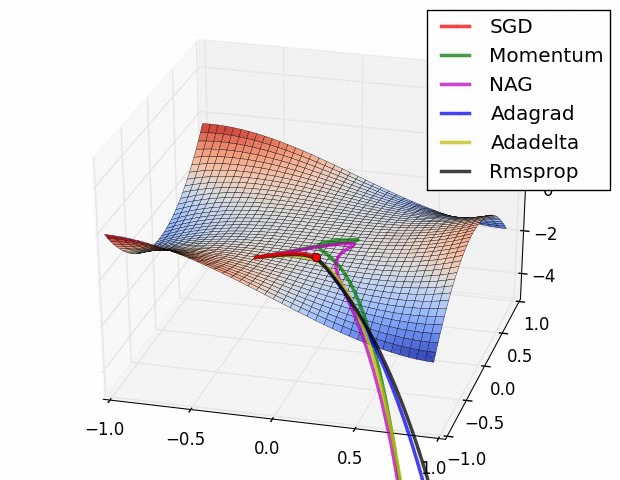
7、優化器
優化器就是在深度學習反向傳播過程中,指引損失函數(目標函數)的各個參數往正確的方向更新合適的大小,使得更新后的各個參數讓損失函數(目標函數)值不斷逼近全局最小。
常見的幾種優化器
8、激活函數
激活函數就是對輸入進行過濾,可以理解為一個過濾器
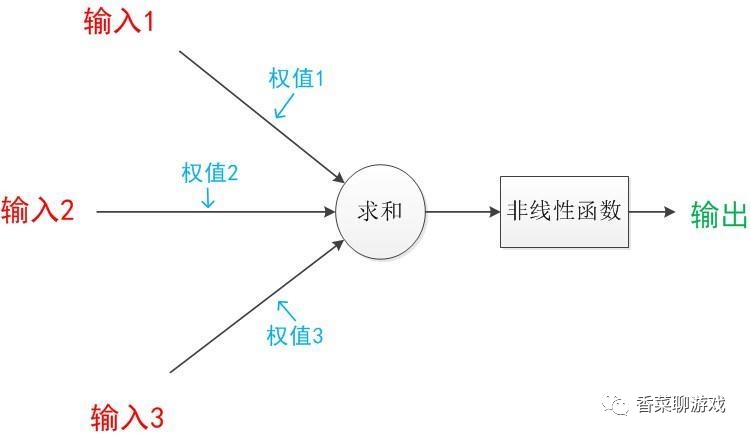
常見的非線性激活函數通常可以分為兩類,一種是輸入單個變量輸出單個變量,如sigmoid函數,Relu函數;還有一種是輸入多個變量輸出多個變量,如Softmax函數,Maxout函數。
- 對于二分類問題,在輸出層可以選擇 sigmoid 函數。
- 對于多分類問題,在輸出層可以選擇 softmax 函數。
- 由于梯度消失問題,盡量sigmoid函數和tanh的使用。
- tanh函數由于以0為中心,通常性能會比sigmoid函數好。
- ReLU函數是一個通用的函數,一般在隱藏層都可以考慮使用。
- 有時候要適當對現有的激活函數稍作修改,以及考慮使用新發現的激活函數。
9、hello world
說了很多概念,搞個demo 看看,下面是一個最簡單的線性回歸的模型。
環境的安裝在文章的開頭。
import torch as t
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
# 學習率,也就是每次參數的移動的大小
lr = 0.01
# 訓練數據集的次數
num_epochs = 100
# 輸入參數的個數
in_size = 1
#輸出參數的個數
out_size = 1
# x 數據集
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
# y 對應的真實值
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 線性回歸網絡
class LinerRegression(nn.Module):
def __init__(self, in_size, out_size):
super(LinerRegression, self).__init__()
self.fc1 = nn.Linear(in_size, out_size)
def forward(self, x):
y_hat = self.fc1(x)
return y_hat
model = LinerRegression(in_size, out_size)
# 損失函數
lossFunc = nn.MSELoss()
# 優化器
optimizer = optim.SGD(model.parameters(), lr=lr)
# 對數據集訓練的循環次數
for epoch in range(num_epochs):
x = t.from_numpy(x_train)
y = t.from_numpy(y_train)
y_hat = model(x)
loss = lossFunc(y_hat, y)
# 導數歸零
optimizer.zero_grad()
# 反向傳播,也就是修正參數,將參數往正確的方向修改
loss.backward()
optimizer.step()
print("[{}/{}] loss:{:.4f}".format(epoch+1, num_epochs, loss))
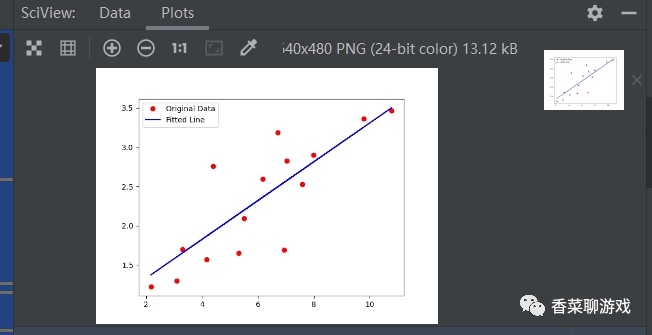
# 畫圖看下最終的模型擬合的怎么樣
y_pred = model(t.from_numpy(x_train)).detach().numpy()
plt.plot(x_train, y_train, 'ro', label='Original Data')
plt.plot(x_train, y_pred, 'b-', label='Fitted Line')
plt.legend()
plt.show()
上面是最簡單的一個線性回歸的神經網絡,沒有隱藏層,沒有激活函數。
運行很快,因為參數很少,運行的最終結果可以看下,最終達到了我們的結果,你可以試著調整一些參數
10、總結
今天寫了很多的概念,不需要全部掌握,先混個臉熟,先有個全局觀,慢慢的認識即可,里面的公式很多,不需要看懂,be easy.
到此這篇關于pytorch之深度神經網絡概念全面整理的文章就介紹到這了,更多相關pytorch神經網絡內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Tensorflow實現AlexNet卷積神經網絡及運算時間評測
- PyTorch實現AlexNet示例
- PyTorch上實現卷積神經網絡CNN的方法
- pytorch實現CNN卷積神經網絡
- Python編程pytorch深度卷積神經網絡AlexNet詳解
