本文主要是講解Spark在Windows環境是如何搭建的
一、JDK的安裝
1、1 下載JDK
首先需要安裝JDK,并且將環境變量配置好,如果已經安裝了的老司機可以忽略。JDK(全稱是JavaTM Platform Standard Edition Development Kit)的安裝,去Oracle官網下載,下載地址是Java SE Downloads。
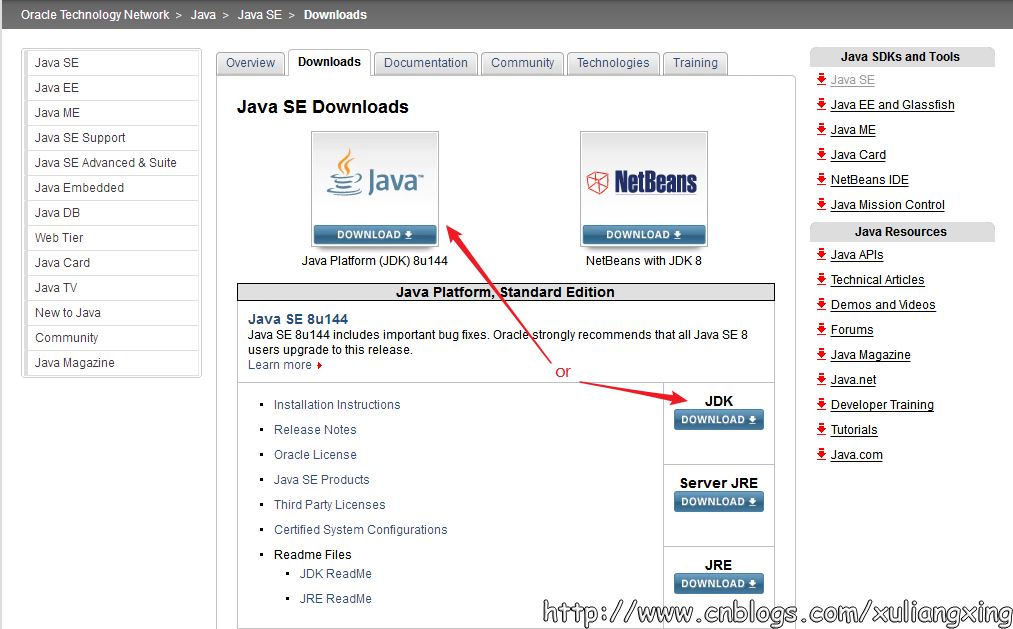
上圖中兩個用紅色標記的地方都是可以點擊的,點擊進去之后可以看到這個最新版本的一些更為詳細的信息,如下圖所示:

下載完之后,我們安裝就可以直接JDK,JDK在windows下的安裝非常簡單,按照正常的軟件安裝思路去雙擊下載得到的exe文件,然后設定你自己的安裝目錄(這個安裝目錄在設置環境變量的時候需要用到)即可。
1、2 JDK環境變量設置
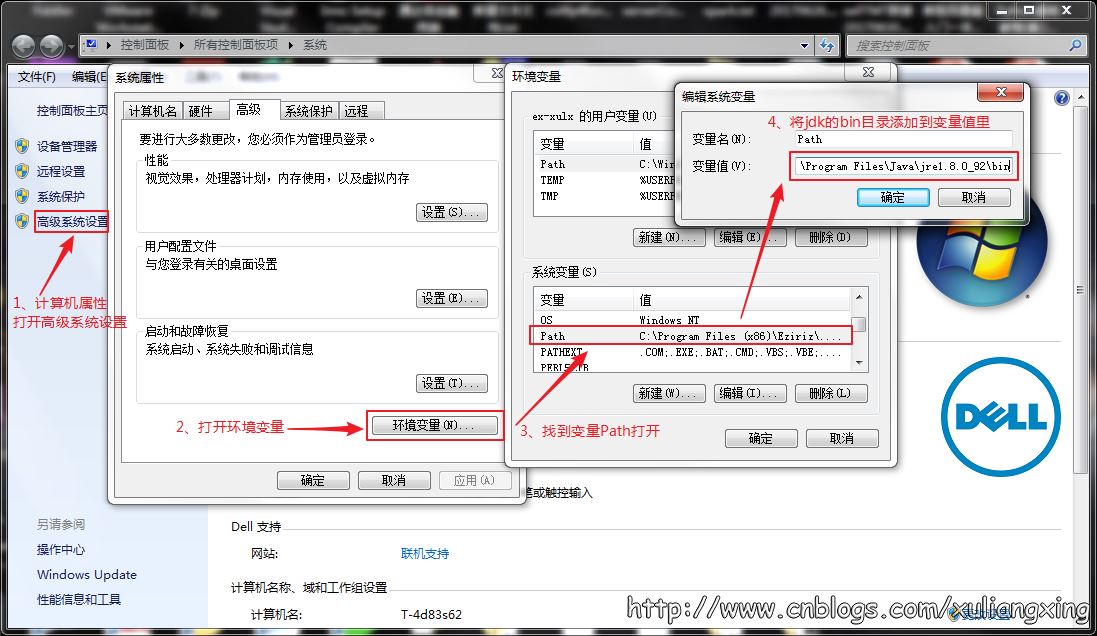
接下來設置相應的環境變量,設置方法為:在桌面右擊【計算機】--【屬性】--【高級系統設置】,然后在系統屬性里選擇【高級】--【環境變量】,然后在系統變量中找到“Path”變量,并選擇“編輯”按鈕后出來一個對話框,可以在里面添加上一步中所安裝的JDK目錄下的bin文件夾路徑名,我這里的bin文件夾路徑名是:C:\Program Files\Java\jre1.8.0_92\bin,所以將這個添加到path路徑名下,注意用英文的分號“;”進行分割。如圖所示:
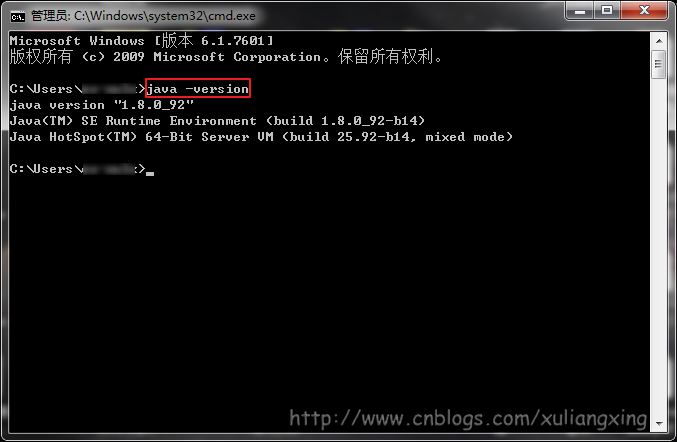
這樣設置好后,便可以在任意目錄下打開的cmd命令行窗口下運行下面命令。查看是否設置成功。
觀察是否能夠輸出相關java的版本信息,如果能夠輸出,說明JDK安裝這一步便全部結束了。如圖所示:
二、Scala的安裝
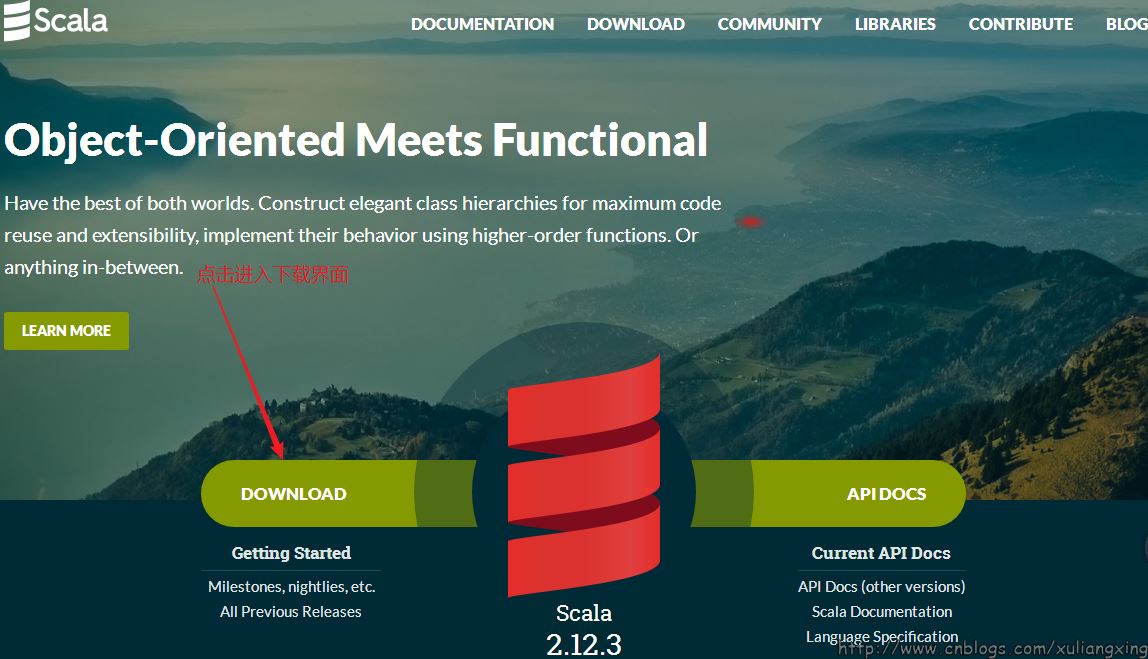
我們從官網:http://www.scala-lang.org/下載Scala,最新的版本為2.12.3,如圖所示
因為我們是在Windows環境下,這也是本文的目的,我們選擇對應的Windows版本下載,如圖所示:
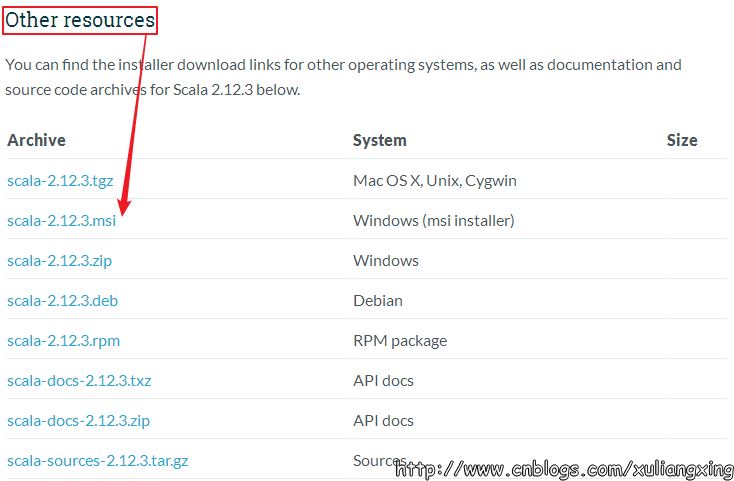
下載得到Scala的msi文件后,可以雙擊執行安裝。安裝成功后,默認會將Scala的bin目錄添加到PATH系統變量中去(如果沒有,和上面JDK安裝步驟中類似,將Scala安裝目錄下的bin目錄路徑,添加到系統變量PATH中),為了驗證是否安裝成功,開啟一個新的cmd窗口,輸入scala然后回車,如果能夠正常進入到Scala的交互命令環境則表明安裝成功。如下圖所示:
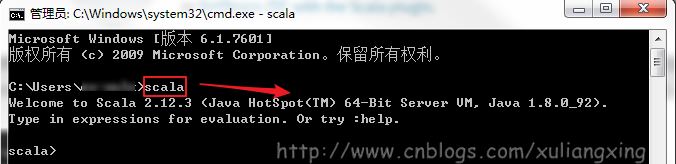
備注:如果不能顯示版本信息,并且未能進入Scala的交互命令行,通常有兩種可能性:
1、Path系統變量中未能正確添加Scala安裝目錄下的bin文件夾路徑名,按照JDK安裝中介紹的方法添加即可。
2、Scala未能夠正確安裝,重復上面的步驟即可。
三、Spark的安裝
我們到Spark官網進行下載:http://spark.apache.org/,我們選擇帶有Hadoop版本的Spark,如圖所示:
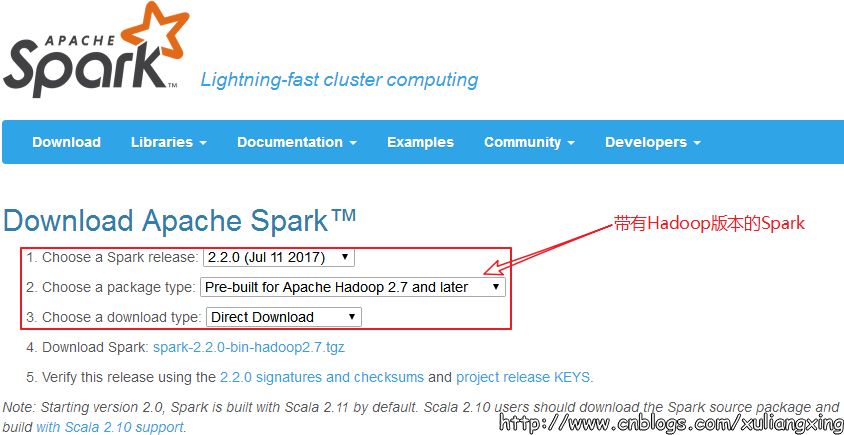
下載后得到了大約200M的文件: spark-2.2.0-bin-hadoop2.7
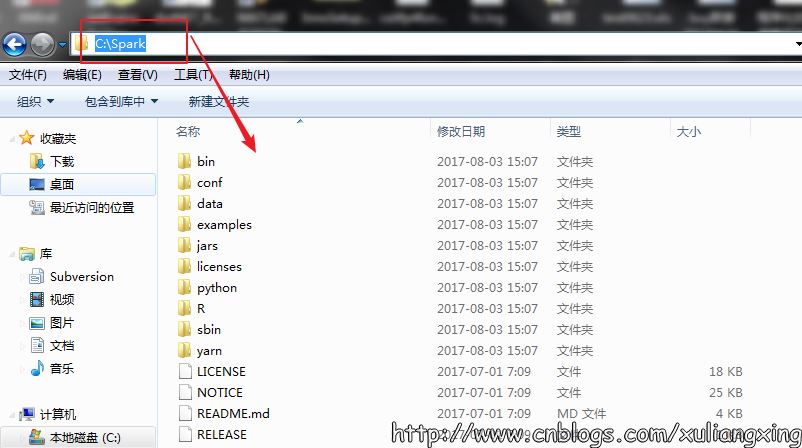
這里使用的是Pre-built的版本,意思就是已經編譯了好了,下載來直接用就好,Spark也有源碼可以下載,但是得自己去手動編譯之后才能使用。下載完成后將文件進行解壓(可能需要解壓兩次),最好解壓到一個盤的根目錄下,并重命名為Spark,簡單不易出錯。并且需要注意的是,在Spark的文件目錄路徑名中,不要出現空格,類似于“Program Files”這樣的文件夾名是不被允許的。我們在C盤新建一個Spark文件夾存放,如圖所示:
解壓后基本上就差不多可以到cmd命令行下運行了。但這個時候每次運行spark-shell(spark的命令行交互窗口)的時候,都需要先cd到Spark的安裝目錄下,比較麻煩,因此可以將Spark的bin目錄添加到系統變量PATH中。例如我這里的Spark的bin目錄路徑為D:\Spark\bin,那么就把這個路徑名添加到系統變量的PATH中即可,方法和JDK安裝過程中的環境變量設置一致,設置完系統變量后,在任意目錄下的cmd命令行中,直接執行spark-shell命令,即可開啟Spark的交互式命令行模式。
系統變量設置后,就可以在任意當前目錄下的cmd中運行spark-shell,但這個時候很有可能會碰到各種錯誤,這里主要是因為Spark是基于hadoop的,所以這里也有必要配置一個Hadoop的運行環境。錯誤如圖所示:
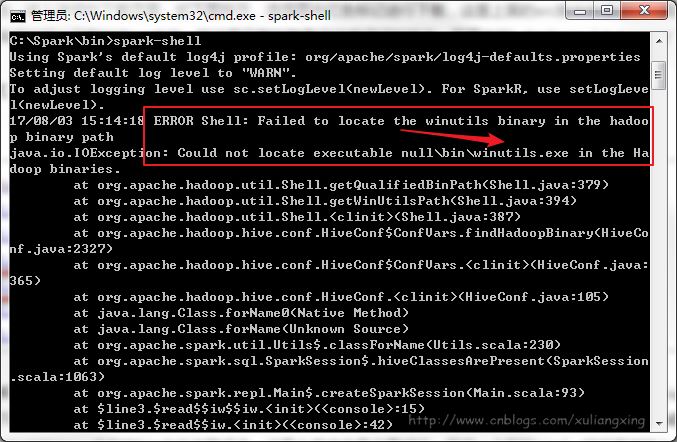
接下來,我們還需要安裝Hadoop。
四、Hadoop的安裝
在Hadoop Releases里可以看到Hadoop的各個歷史版本,這里由于下載的Spark是基于Hadoop 2.7的(在Spark安裝的第一個步驟中,我們選擇的是Pre-built for Hadoop 2.7),我這里選擇2.7.1版本,選擇好相應版本并點擊后,進入詳細的下載頁面,如下圖所示:

選擇圖中紅色標記進行下載,這里上面的src版本就是源碼,需要對Hadoop進行更改或者想自己進行編譯的可以下載對應src文件,我這里下載的就是已經編譯好的版本,即圖中的“hadoop-2.7.1.tar.gz”文件。
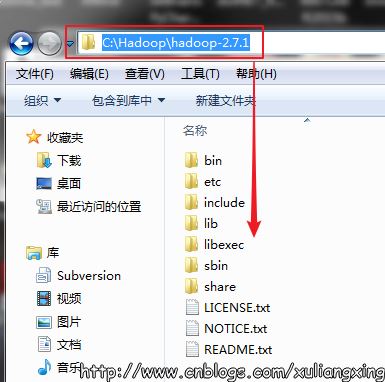
下載并解壓到指定目錄,,我這里是C:\Hadoop,如圖所示:
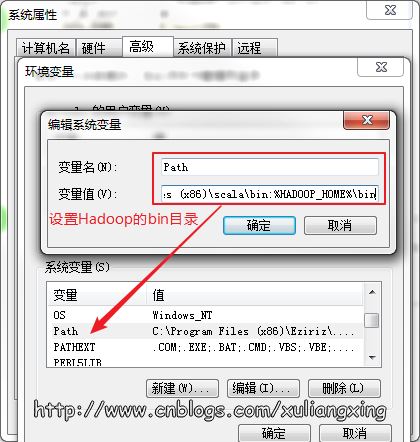
然后到環境變量部分設置HADOOP_HOME為Hadoop的解壓目錄,如圖所示:

然后再設置該目錄下的bin目錄到系統變量的PATH下,我這里也就是C:\Hadoop\bin,如果已經添加了HADOOP_HOME系統變量,也可用%HADOOP_HOME%\bin來指定bin文件夾路徑名。這兩個系統變量設置好后,開啟一個新的cmd窗口,然后直接輸入spark-shell命令。如圖所示:
正常情況下是可以運行成功并進入到Spark的命令行環境下的,但是對于有些用戶可能會遇到空指針的錯誤。這個時候,主要是因為Hadoop的bin目錄下沒有winutils.exe文件的原因造成的。這里的解決辦法是:
可以去https://github.com/steveloughran/winutils選擇你安裝的Hadoop版本號,然后進入到bin目錄下,找到winutils.exe文件,下載方法是點擊winutils.exe文件,進入之后在頁面的右上方部分有一個Download按鈕,點擊下載即可。 如圖所示:
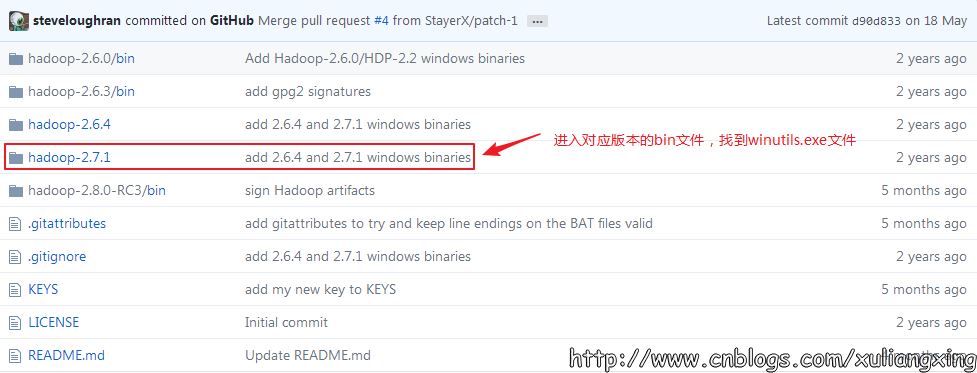
下載winutils.exe文件
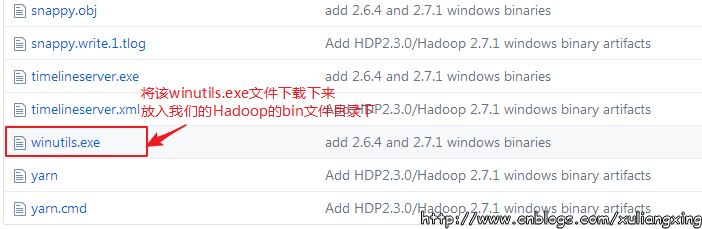
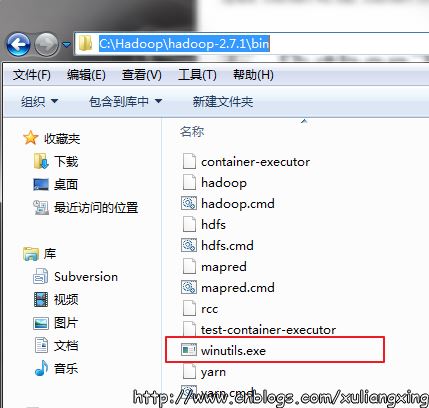
將下載好winutils.exe后,將這個文件放入到Hadoop的bin目錄下,我這里是C:\Hadoop\hadoop-2.7.1\bin。
在打開的cmd中輸入
復制代碼 代碼如下:
C:\Hadoop\hadoop-2.7.1\bin\winutils.exe chmod 777 /tmp/Hive //修改權限,777是獲取所有權限
但是我們發現報了一些其他的錯(Linux環境下也是會出現這個錯誤)
console>:14: error: not found: value spark
import spark.implicits._
^
console>:14: error: not found: value spark
import spark.sql
其原因是沒有權限在spark中寫入metastore_db 這個文件。
處理方法:我們授予777的權限
Linux環境,我們在root下操作:
sudo chmod 777 /home/hadoop/spark
#為了方便,可以給所有的權限
sudo chmod a+w /home/hadoop/spark
window環境下:
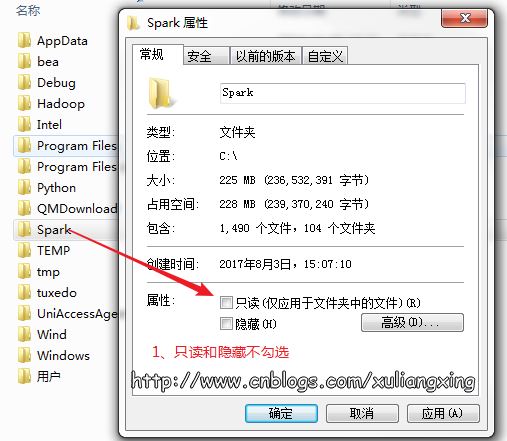
存放Spark的文件夾不能設為只讀和隱藏,如圖所示:
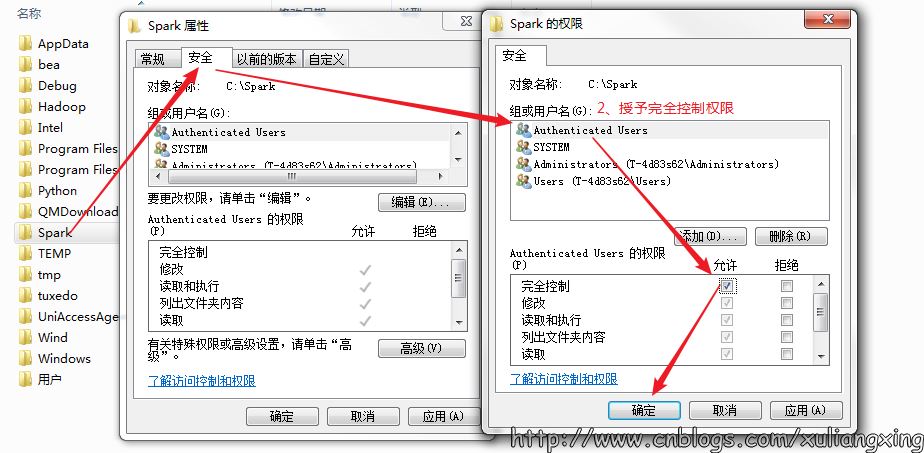
授予完全控制的權限,如圖所示:
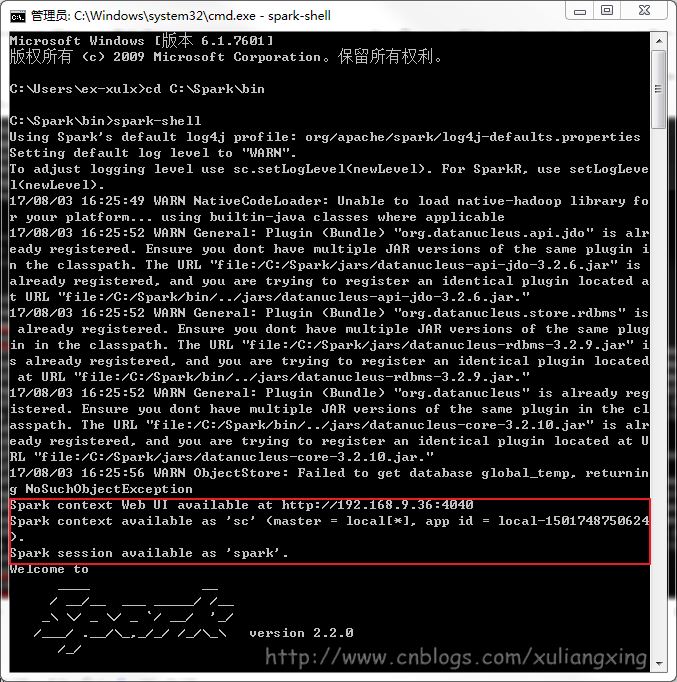
經過這幾個步驟之后,然后再次開啟一個新的cmd窗口,如果正常的話,應該就可以通過直接輸入spark-shell來運行Spark了。正常的運行界面應該如下圖所示:
六、Python下Spark開發環境搭建
下面簡單講解Python下怎么搭建Spark環境
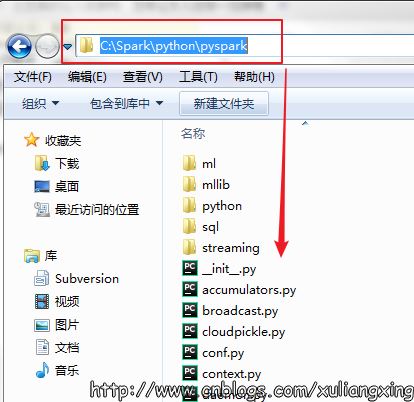
1、將spark目錄下的pyspark文件夾(C:\Spark\python\pyspark)復制到python安裝目錄C:\Python\Python35\Lib\site-packages里。如圖所示
spark的pysaprk
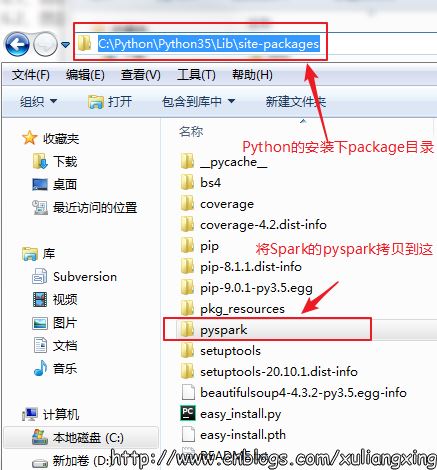
將pyspark拷貝至Python的安裝的packages目錄下。
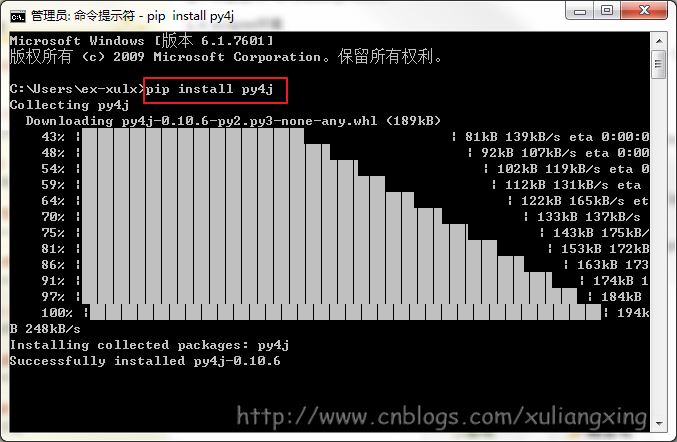
2、然后使用cd命令,進入目錄D:\python27\Scripts,運行pip install py4j安裝py4j庫。如圖所示:
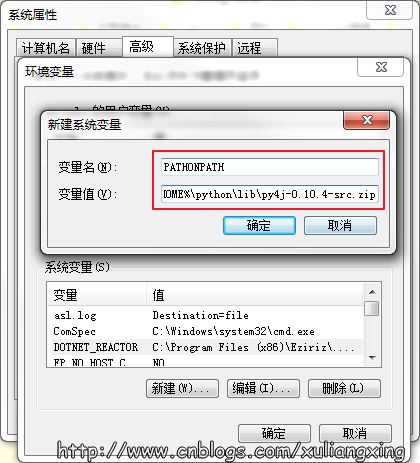
如果需要在python中或者在類似于IDEA IntelliJ或者PyCharm(筆者用的就是PyCharm)等IDE中使用PySpark的話,需要在系統變量中新建一個PYTHONPATH的系統變量,然后設置好下面變量值就可以了
PATHONPATH=%SPARK_HOME%\python;%SPARK_HOME%\python\lib\py4j-0.10.4-src.zip
后面的事情就交給PyCharm了。
至此,Spark在Windows環境下的搭建講解已結束。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持腳本之家。
您可能感興趣的文章:- Spark在Win10下的環境搭建過程
- windows下pycharm搭建spark環境并成功運行 附源碼
- PyCharm搭建Spark開發環境的實現步驟
- Python搭建Spark分布式集群環境
- PyCharm搭建Spark開發環境實現第一個pyspark程序
- Linux下搭建Spark 的 Python 編程環境的方法
- 使用docker快速搭建Spark集群的方法教程
- Spark集群框架的搭建與入門
