正則表達式應用非常廣泛,例如:php,Python,java等,但在linux中最常用的正則表達式的命令就是grep(egrep),sed,awk等,換句話 說linux三劍客要想能工作的更高效,就一定離不開正則表達式的配合。
1、什么是正則表達式?
簡單的說,正則表達式就是為處理大量的字符串而定義的一套規則和方法。通過定義的這些特殊符號的輔助,系統管理員就可以快速過濾、替換或者輸出需要的字符串。linux正則表達式一般以行為單位處理的。
2、為什么要學正則表達式
在企業工作中,我們每天做的linux運維工作中,時刻都會面對大量帶有字符串的文本配置、程序、命令輸出及日志文件等,而我們經常會有迫切的需要從大量的字符串內容中查找符合工作需要的特定字符串,這就要靠正則表達式,因此,可以說正則表達式就是為過濾這樣字符串的需求而生的!
3、容易混淆的兩個注意事項:
1)linux正則表達式一般是以行為單位處理的。
2)正則表達式和我們常用的通配符特殊字符是有本質區別的,例如:ls *.txt 這里的*就是通配符(表示所有),不是正則表達式。
注意字符集問題:
確保字符集:export LC_ALL=C
---------------------------------------------
基礎正則表達式+擴展正則表達式含義解釋:
---------------------------------------------
. 代表且只能代表任意一個字符(不包括空行)
* 重復前面任意0個或多個字符
.* 匹配所有字符。(包括空行)
sed -ri 's#(.*)#\1#g' bqh.txt
把前面正則匹配的括號內的結果,在后面用\1取出來操作。
^ 表示以什么開頭,^bqh 以bqh開頭
$ 是以什么結尾
^$ 表示空行。
\ 例\. 就只代表點本身,轉義符號,讓有著特殊身份移動的字符,脫掉馬甲,還原原型\$
^.* 以任意多個字符開頭。
.*$ 以任意多個字符結尾。
(.*) 從第一字符匹配,到空格停止,
[abc] 匹配字符集合內的任意一個字符【a-zA-Z】
[^abc] 匹配不包括^后的任意字符的內容;中括號里的^為取反,注意和以...開頭區別。
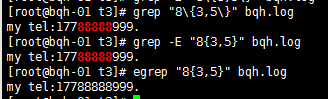
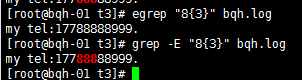
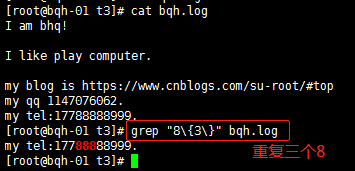
a\{n,m\} 重復n到m次,前一個重復的字符。如果有用egrep/sed -r 可以去掉斜線。
\{n,\} 重復至少n次,前一個重復的字符。如果有用egrep/sed -r 可以去掉斜線。
\{n\} 重復n次,前一個重復的字符。如果有用egrep/sed -r 可以去掉斜線。
①^word 搜索以word開頭的;vi ^ 一行的開夠
②word$ 搜索以word結尾的;vi $ 一行的開頭
③^$ 表示空行。
擴展的正則表達式:ERP(egrep或grep -E)
+ 重復一個或一個以上前面的字符
? 復0個或一個0前面的字符
| 用或的方式查找多個符合的字符串
() 找出“用戶組”字符串
實戰舉例:
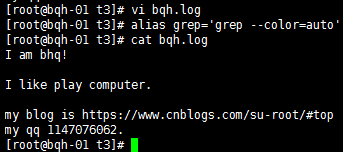
^m 搜索以m開頭的

p$搜索以p結尾的

^$表示空號
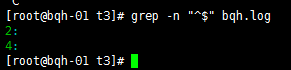
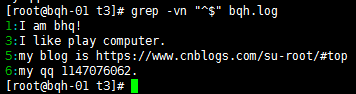
去掉空行:grep –v “^$” bqh.log
查看去掉的后的空行內容:grep -vn “^$” bqh.log
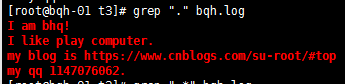
. 代表且只能代表任意一個字符(不包括空行)
查找帶0的字符:

.* 匹配所有字符。(包括空行)
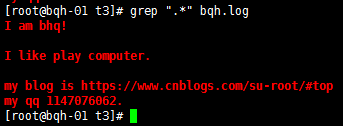
查找以.結尾的字符:
錯誤方法:grep ".$" bqh.log
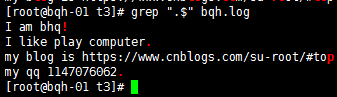
正確方法:
grep “\.$” bqh.log
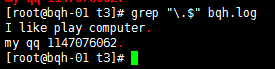
注意:\. 就只代表點本身,轉義符號,讓有著特殊身份移動的字符,脫掉馬甲,還原原型\$
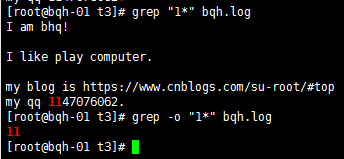
* 例1*重復1個或多個前面的一個字符。
grep –o “1*” bqh.log //-o精確匹配
^.* 以任意多個字符開頭。

.*$ 以任意多個字符結尾。

[abc] 匹配字符集合內的任意一個字符【a-zA-Z】
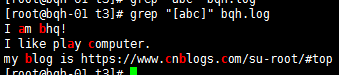
匹配字符集合內的a-z任意一個小寫字符:
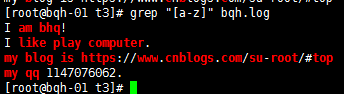
[^abc] 匹配不包括^后的任意字符的內容;中括號里的^為取反,注意和以...開頭區別
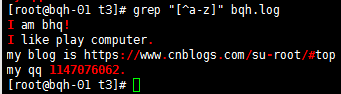
匹配非數字的任意字符:
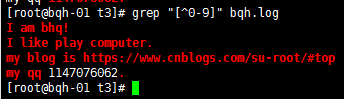
a\{n,m\} 重復n到m次,前一個重復的字符。如果有用egrep/sed -r /grep -E可以去掉斜線。
\{n,\} 重復至少n次,前一個重復的字符。如果有用egrep/sed -r 可以去掉斜線。
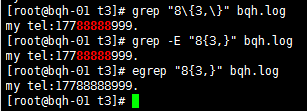
\{n\} 重復n次,前一個重復的字符。如果有用egrep/sed -r 可以去掉斜線。
注意:egrep,grep -E或sed -r過濾一般特殊字符可以不轉義。多使用參數。
---------------------------------------------------------------------------------
擴展的正則表達式:ERP(egrep或grep -E)
+ 重復一個或一個以上前面的字符
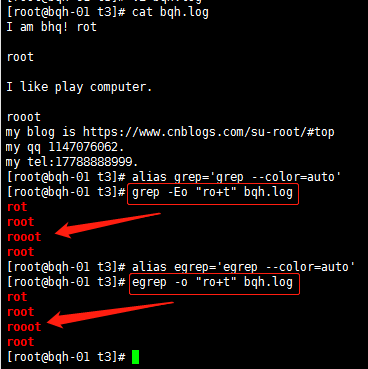
? 復0個或一個0前面的字符
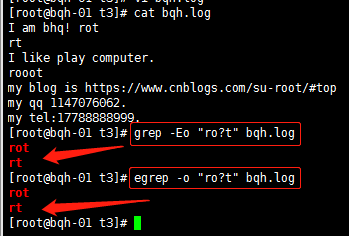
| 用或的方式查找多個符合的字符串
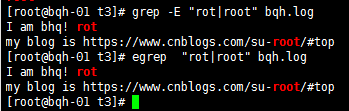
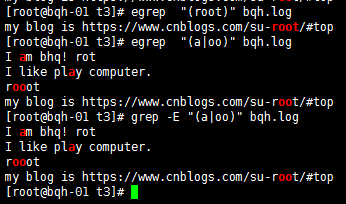
() 找出“用戶組”字符串
總結
以上所述是小編給大家介紹的詳解linux正則表達式(基礎正則表達式+擴展正則表達式),希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對腳本之家網站的支持!
您可能感興趣的文章:- Linux中的特殊符號與正則表達式
- 淺談Linux grep與正則表達式
- linux下的通配符與正則表達式
- 詳解Linux命令中的正則表達式
- 詳解基于Linux下正則表達式(基本正則和擴展正則命令使用實例)
- linux shell 路徑截取正則表達式
- 使用Linux正則表達式靈活搜索文件中的文本
- linux正則表達式awk詳解
