昨天在《js 正則學習小記之匹配字符串字面量》談到 /"(?:\\.|[^"])*"/ 是個不錯的表達式,因為可以滿足我們的要求,所以這個表達式可用,但不一定是最好的。
從性能上來說,他非常糟糕,為什么這么說呢,因為 傳統型NFA引擎 遇到分支是從左往右匹配的,
所以它會用 \\. 去匹配每一個字符,發現不對后才用 [^"] 去匹配。
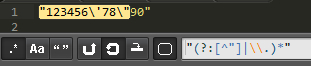
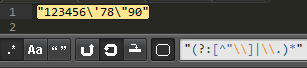
比如這樣一個字符串: "123456\'78"90"
共 16 個字符,除了第一個 " 直接匹配成功,還剩余 15 個,只有 2 個轉義(4 個字符),所以 \. 會失敗 10 次,只有 2 次成功。
這 10 次匹配失敗,需要回溯后用 [^"] 才能匹配成功,當然最后一個 " 會直接匹配成功。
很明顯,正常的字符串不可能全是轉義,正常的字符串才是主流,當然不排除有人故意全轉義的情況。
所以這個正則需要10次回溯后才能匹配完成,如果字符串增長到 1K 1M 腫么破呢?
所以我們要修改下這個正則,前后換下位置么?
難道是 /"(?:[^"]|\.)*"/ ? 呵呵,好像不太對,這樣的話轉義就不能被匹配了。
所以還要修改下 /"(?:[^"\\]|\.)*"/ 這樣就OK了,遇到 \ 轉義就會用 \\. 去嘗試匹配。
可是還是有問題,因為我們在 [^"\\] 過濾掉了 n 所以沒法匹配多行字符的情況。

js 中 字符串用 折行是允許的,但是修改后的 正則 沒法匹配這樣的字符串了,所以我們還得繼續修復。
因為 . 沒法匹配換行,所以我們要用其他方式表達。
. 是用于匹配除換行符之外的所有字符,難道我們要 [.\n] 來表示么?
這樣是不對的,因為 [] 字符集中的 . 不再表示除換行符之外的所有字符,而是字符 . 也就是他本身一個字符而已。
那怎么辦呢?
其實換個思路,
d 表示 0-9
D 表示 [^0-9]
那么 [\d\D] 就表示所有了,不是么。(新人朋友不知道能不能消化這個知識點。)
同理 [\s\S] [\w\W] 同樣可以。
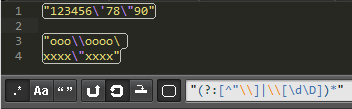
所以 /"(?:[^"\\]|\[\d\D])*"/ 這樣就滿足我們的要求了。
效果不錯。
回頭過來分分析下他現在的性能吧。
還是這個字符串: "123456'78\"90" , 正則 /"(?:[^"\\]|\\[\d\D])*"/
共 16 個字符,除了第一個 " 直接匹配成功,還剩余 15 個,有 2 個轉義(4 個字符),[^"\\] 能匹配成功 10 個字符,只有 2 次失敗。
為什么不是 4 次失敗呢,明明有4個字符啊。\\ 雖然是2個字符,但是讀到第一個 \ 就匹配失敗,然后用 \\[\d\D] 匹配成功,
占用掉了兩個字符 \\ 下次用下一個o開始匹配,所以只有2次回溯。
只有 2 次需要回溯,然后用 \\[\d\D] 匹配成功。當然最后一個 " 還是會直接匹配成功。
所以從 10 次回溯,減少到了 2 次,雖然正則比昨天臃腫了很多,但至少性能提升了不止一個等級。
OK,今天的分享完畢,明天見。
您可能感興趣的文章:- js 正則表達式學習筆記之匹配字符串
- 正則匹配密碼只能是數字和字母組合字符串功能【php與js實現】
- String字符串匹配javascript 正則表達式
- js正則學習小記之匹配字符串字面量
- JavaScript正則表達式匹配字符串字面量
- 一個關于JS正則匹配的踩坑記錄
