Canal的介紹
Canal的歷史由來
在早期的時候,阿里巴巴公司因為杭州和美國兩個地方的機房都部署了數據庫實例,但因為跨機房同步數據的業務需求 ,便孕育而生出了Canal,主要是基于trigger(觸發器)的方式獲取增量變更。從2010年開始,阿里巴巴公司開始逐步嘗試數據庫日志解析,獲取增量變更的數據進行同步,由此衍生出了增量訂閱和消費業務。
當前的Canal支持的數據源端MySQL版本包括:5.1.x 、5.5.x 、5.6.x、5.7.x、8.0.x。
Canal的應用場景
目前普遍基于日志增量訂閱和消費的業務,主要包括:
- 基于數據庫增量日志解析,提供增量數據訂閱和消費
- 數據庫鏡像 數據庫實時備份
- 索引構建和實時維護(拆分異構索引、倒排索引等)
- 業務Cache刷新
- 帶業務邏輯的增量數據處理
- Canal的工作原理
在介紹Canal的原理之前,我們先來了解下MySQL主從復制的原理。
MySQL主從復制原理
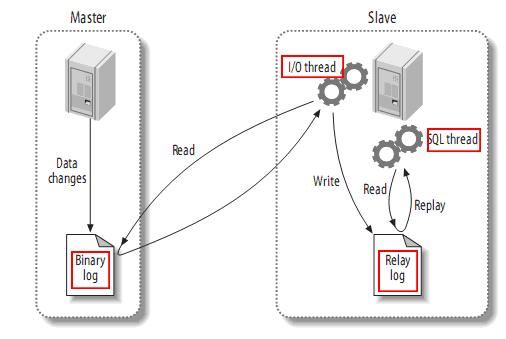
- MySQL Master將數據變更的操作寫入二進制日志binary log中, 其中記錄的內容叫做二進制日志事件binary log events,可以通過show binlog events命令進行查看
- MySQL Slave會將Master的binary log中的binary log events拷貝到它的中繼日志relay log
- MySQL Slave重讀并執行relay log中的事件,將數據變更映射到它自己的數據庫表中
了解了MySQL的工作原理,我們可以大致猜想到Canal應該也是采用類似的邏輯去實現增量數據訂閱的功能,那么接下來我們看看實際上Canal的工作原理是怎樣的?
Canal工作原理
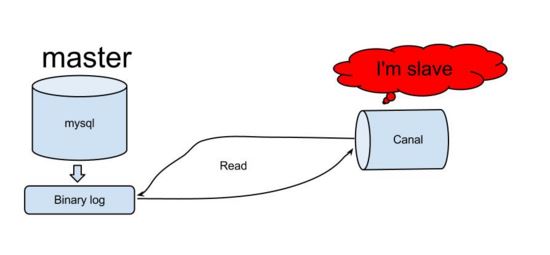
- Canal模擬MySQL Slave的交互協議,偽裝自己為MySQL Slave,向MySQL Master發送dump協議
- MySQL Master收到dump請求,開始推送binary log給Slave(也就是Canal)
- Canal解析binary log對象(數據為byte流)
基于這樣的原理與方式,便可以完成數據庫增量日志的獲取解析,提供增量數據訂閱和消費,實現MySQL實時增量數據傳輸的功能。
既然Canal是這樣的一個框架,又是純Java語言編寫而成,那么我們接下來就開始學習怎么使用它并把它用到我們的實際工作中。
Canal的Docker環境準備
因為目前容器化技術的火熱,本文通過使用Docker來快速搭建開發環境,而傳統方式的環境搭建,在我們學會了Docker容器環境搭建后,也能自行依葫蘆畫瓢搭建成功。由于本篇主要講解Canal,所以關于Docker的內容不會涉及太多,主要會介紹Docker的基本概念和命令使用。 如果你想和更多容器技術專家交流,可以加我微信liyingjiese,備注『加群』。群里每周都有全球各大公司的最佳實踐以及行業最新動態 。
什么是Docker
相信絕大多數人都使用過虛擬機VMware,在使用VMware進行環境搭建的時候,只需提供了一個普通的系統鏡像并成功安裝,剩下的軟件環境與應用配置還是如我們在本機操作一樣在虛擬機里也操作一遍,而且VMware占用宿主機的資源較多,容易造成宿主機卡頓,而且系統鏡像本身也占用過多空間。
為了便于大家快速理解Docker,便與VMware做對比來做介紹,Docker提供了一個開始,打包,運行APP的平臺,把APP(應用)和底層infrastructure(基礎設施)隔離開來。Docker中最主要的兩個概念就是鏡像(類似VMware的系統鏡像)與容器(類似VMware里安裝的系統)。
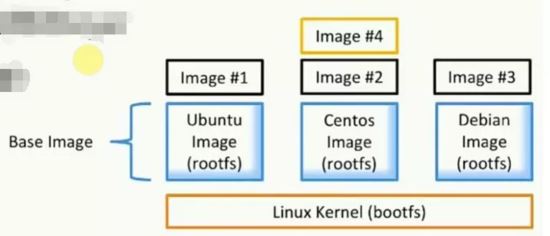
什么是Image(鏡像)
- 文件和meta data的集合(root filesystem)
- 分層的,并且每一層都可以添加改變刪除文件,成為一個新的image
- 不同的image可以共享相同的layer
- Image本身是read-only的
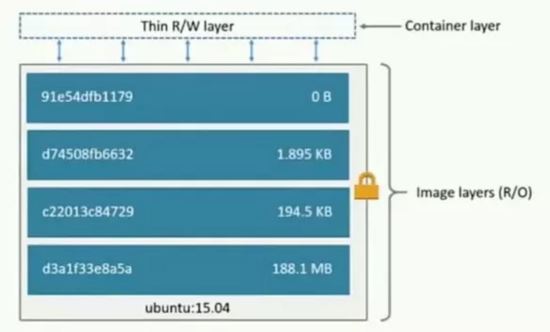
什么是Container(容器)
- 通過Image創建(copy)
- 在Image layer之上建立一個container layer(可讀寫)
- 類比面向對象:類和實例
- Image負責APP的存儲和分發,Container負責運行APP
Docker的網絡介紹
Docker的網絡類型有三種:
- Bridge:橋接網絡。默認情況下啟動的Docker容器,都是使用Bridge,Docker安裝時創建的橋接網絡,每次Docker容器重啟時,會按照順序獲取對應的IP地址,這個就導致重啟下,Docker的IP地址就變了。
- None:無指定網絡。使用 --network=none,Docker容器就不會分配局域網的IP。
- Host:主機網絡。使用--network=host,此時,Docker容器的網絡會附屬在主機上,兩者是互通的。例如,在容器中運行一個Web服務,監聽8080端口,則主機的8080端口就會自動映射到容器中。
創建自定義網絡:(設置固定IP)
docker network create --subnet=172.18.0.0/16 mynetwork
查看存在的網絡類型docker network ls:

搭建Canal環境
附上Docker的下載安裝地址==> Docker Download 。
下載Canal鏡像docker pull canal/canal-server:
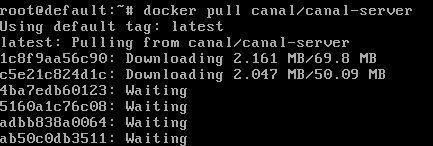
下載MySQL鏡像docker pull mysql,下載過的則如下圖:

查看已經下載好的鏡像docker images:

接下來通過鏡像生成MySQL容器與canal-server容器:
##生成mysql容器
docker run -d --name mysql --net mynetwork --ip 172.18.0.6 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root mysql
##生成canal-server容器
docker run -d --name canal-server --net mynetwork --ip 172.18.0.4 -p 11111:11111 canal/canal-server
## 命令介紹
--net mynetwork #使用自定義網絡
--ip #指定分配ip
查看Docker中運行的容器docker ps:

MySQL的配置修改
以上只是初步準備好了基礎的環境,但是怎么讓Canal偽裝成Salve并正確獲取MySQL中的binary log呢?
對于自建MySQL,需要先開啟Binlog寫入功能,配置binlog-format為ROW模式,通過修改MySQL配置文件來開啟bin_log,使用find / -name my.cnf查找my.cnf,修改文件內容如下:
[mysqld]
log-bin=mysql-bin # 開啟binlog
binlog-format=ROW # 選擇ROW模式
server_id=1 # 配置MySQL replaction需要定義,不要和Canal的slaveId重復
進入MySQL容器docker exec -it mysql bash。
創建鏈接MySQL的賬號Canal并授予作為MySQL slave的權限,如果已有賬戶可直接GRANT:
mysql -uroot -proot
# 創建賬號
CREATE USER canal IDENTIFIED BY 'canal';
# 授予權限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
# 刷新并應用
FLUSH PRIVILEGES;
數據庫重啟后,簡單測試 my.cnf 配置是否生效:
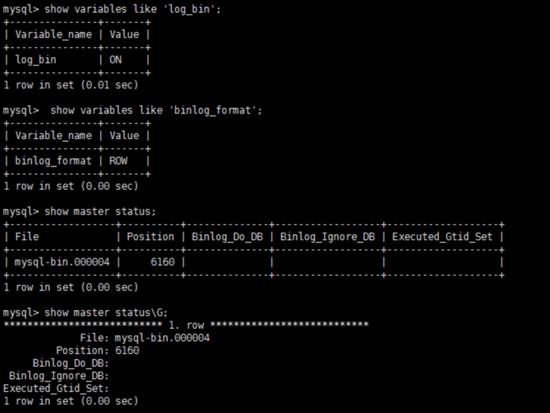
show variables like 'log_bin';
show variables like 'log_bin';
show master status;
canal-server的配置修改
進入canal-server容器docker exec -it canal-server bash。
編輯canal-server的配置vi canal-server/conf/example/instance.properties:

更多配置請參考==>Canal配置說明 。
重啟canal-server容器docker restart canal-server 進入容器查看啟動日志:
docker exec -it canal-server bash
tail -100f canal-server/logs/example/example.log

至此,我們的環境工作準備完成!
拉取數據并同步保存到ElasticSearch
本文的ElasticSearch也是基于Docker環境搭建,所以讀者可執行如下命令:
# 下載對鏡像
docker pull elasticsearch:7.1.1
docker pull mobz/elasticsearch-head:5-alpine
# 創建容器并運行
docker run -d --name elasticsearch --net mynetwork --ip 172.18.0.2 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.1.1
docker run -d --name elasticsearch-head --net mynetwork --ip 172.18.0.5 -p 9100:9100 mobz/elasticsearch-head:5-alpine
環境已經準備好了,現在就要開始我們的編碼實戰部分了,怎么通過應用程序去獲取Canal解析后的binlog數據。首先我們基于Spring Boot搭建一個canal demo應用。結構如下圖所示:
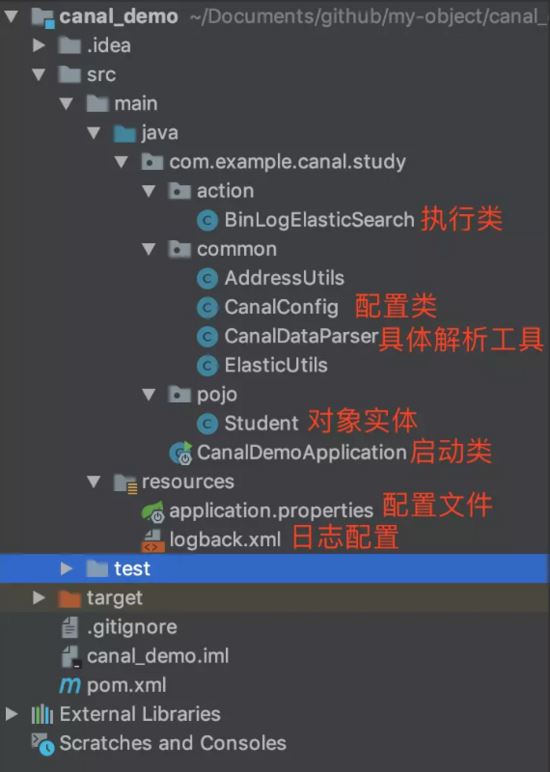
Student.java
package com.example.canal.study.pojo;
import lombok.Data;
import java.io.Serializable;
// @Data 用戶生產getter、setter方法
@Data
public class Student implements Serializable {
private String id;
private String name;
private int age;
private String sex;
private String city;
}
CanalConfig.java
package com.example.canal.study.common;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.net.InetSocketAddress;
/**
* @author haha
*/
@Configuration
public class CanalConfig {
// @Value 獲取 application.properties配置中端內容
@Value("${canal.server.ip}")
private String canalIp;
@Value("${canal.server.port}")
private Integer canalPort;
@Value("${canal.destination}")
private String destination;
@Value("${elasticSearch.server.ip}")
private String elasticSearchIp;
@Value("${elasticSearch.server.port}")
private Integer elasticSearchPort;
@Value("${zookeeper.server.ip}")
private String zkServerIp;
// 獲取簡單canal-server連接
@Bean
public CanalConnector canalSimpleConnector() {
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress(canalIp, canalPort), destination, "", "");
return canalConnector;
}
// 通過連接zookeeper獲取canal-server連接
@Bean
public CanalConnector canalHaConnector() {
CanalConnector canalConnector = CanalConnectors.newClusterConnector(zkServerIp, destination, "", "");
return canalConnector;
}
// elasticsearch 7.x客戶端
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost(elasticSearchIp, elasticSearchPort))
);
return client;
}
}
CanalDataParser.java
由于這個類的代碼較多,文中則摘出其中比較重要的部分,其它部分代碼可從GitHub上獲取:
public static class TwoTuple<A, B> {
public final A eventType;
public final B columnMap;
public TwoTuple(A a, B b) {
eventType = a;
columnMap = b;
}
}
public static List<TwoTuple<EventType, Map>> printEntry(List<Entry> entrys) {
List<TwoTuple<EventType, Map>> rows = new ArrayList<>();
for (Entry entry : entrys) {
// binlog event的事件事件
long executeTime = entry.getHeader().getExecuteTime();
// 當前應用獲取到該binlog鎖延遲的時間
long delayTime = System.currentTimeMillis() - executeTime;
Date date = new Date(entry.getHeader().getExecuteTime());
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 當前的entry(binary log event)的條目類型屬于事務
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN) {
TransactionBegin begin = null;
try {
begin = TransactionBegin.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
// 打印事務頭信息,執行的線程id,事務耗時
logger.info(transaction_format,
new Object[]{entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader().getLogfileOffset()),
String.valueOf(entry.getHeader().getExecuteTime()),
simpleDateFormat.format(date),
entry.getHeader().getGtid(),
String.valueOf(delayTime)});
logger.info(" BEGIN ----> Thread id: {}", begin.getThreadId());
printXAInfo(begin.getPropsList());
} else if (entry.getEntryType() == EntryType.TRANSACTIONEND) {
TransactionEnd end = null;
try {
end = TransactionEnd.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
// 打印事務提交信息,事務id
logger.info("----------------\n");
logger.info(" END ----> transaction id: {}", end.getTransactionId());
printXAInfo(end.getPropsList());
logger.info(transaction_format,
new Object[]{entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader().getLogfileOffset()),
String.valueOf(entry.getHeader().getExecuteTime()), simpleDateFormat.format(date),
entry.getHeader().getGtid(), String.valueOf(delayTime)});
}
continue;
}
// 當前entry(binary log event)的條目類型屬于原始數據
if (entry.getEntryType() == EntryType.ROWDATA) {
RowChange rowChage = null;
try {
// 獲取儲存的內容
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
// 獲取當前內容的事件類型
EventType eventType = rowChage.getEventType();
logger.info(row_format,
new Object[]{entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader().getLogfileOffset()), entry.getHeader().getSchemaName(),
entry.getHeader().getTableName(), eventType,
String.valueOf(entry.getHeader().getExecuteTime()), simpleDateFormat.format(date),
entry.getHeader().getGtid(), String.valueOf(delayTime)});
// 事件類型是query或數據定義語言DDL直接打印sql語句,跳出繼續下一次循環
if (eventType == EventType.QUERY || rowChage.getIsDdl()) {
logger.info(" sql ----> " + rowChage.getSql() + SEP);
continue;
}
printXAInfo(rowChage.getPropsList());
// 循環當前內容條目的具體數據
for (RowData rowData : rowChage.getRowDatasList()) {
List<CanalEntry.Column> columns;
// 事件類型是delete返回刪除前的列內容,否則返回改變后列的內容
if (eventType == CanalEntry.EventType.DELETE) {
columns = rowData.getBeforeColumnsList();
} else {
columns = rowData.getAfterColumnsList();
}
HashMap<String, Object> map = new HashMap<>(16);
// 循環把列的name與value放入map中
for (Column column: columns){
map.put(column.getName(), column.getValue());
}
rows.add(new TwoTuple<>(eventType, map));
}
}
}
return rows;
}
ElasticUtils.java
package com.example.canal.study.common;
import com.alibaba.fastjson.JSON;
import com.example.canal.study.pojo.Student;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.elasticsearch.action.DocWriteRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
import java.io.IOException;
import java.util.Map;
/**
* @author haha
*/
@Slf4j
@Component
public class ElasticUtils {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 新增
* @param student
* @param index 索引
*/
public void saveEs(Student student, String index) {
IndexRequest indexRequest = new IndexRequest(index)
.id(student.getId())
.source(JSON.toJSONString(student), XContentType.JSON)
.opType(DocWriteRequest.OpType.CREATE);
try {
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
log.info("保存數據至ElasticSearch成功:{}", response.getId());
} catch (IOException e) {
log.error("保存數據至elasticSearch失敗: {}", e);
}
}
/**
* 查看
* @param index 索引
* @param id _id
* @throws IOException
*/
public void getEs(String index, String id) throws IOException {
GetRequest getRequest = new GetRequest(index, id);
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
Map<String, Object> fields = response.getSource();
for (Map.Entry<String, Object> entry : fields.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
/**
* 更新
* @param student
* @param index 索引
* @throws IOException
*/
public void updateEs(Student student, String index) throws IOException {
UpdateRequest updateRequest = new UpdateRequest(index, student.getId());
updateRequest.upsert(JSON.toJSONString(student), XContentType.JSON);
UpdateResponse response = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("更新數據至ElasticSearch成功:{}", response.getId());
}
/**
* 根據id刪除數據
* @param index 索引
* @param id _id
* @throws IOException
*/
public void DeleteEs(String index, String id) throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(index, id);
DeleteResponse response = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("刪除數據至ElasticSearch成功:{}", response.getId());
}
}
BinLogElasticSearch.java
package com.example.canal.study.action;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.example.canal.study.common.CanalDataParser;
import com.example.canal.study.common.ElasticUtils;
import com.example.canal.study.pojo.Student;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.List;
import java.util.Map;
/**
* @author haha
*/
@Slf4j
@Component
public class BinLogElasticSearch {
@Autowired
private CanalConnector canalSimpleConnector;
@Autowired
private ElasticUtils elasticUtils;
//@Qualifier("canalHaConnector")使用名為canalHaConnector的bean
@Autowired
@Qualifier("canalHaConnector")
private CanalConnector canalHaConnector;
public void binLogToElasticSearch() throws IOException {
openCanalConnector(canalHaConnector);
// 輪詢拉取數據
Integer batchSize = 5 * 1024;
while (true) {
Message message = canalHaConnector.getWithoutAck(batchSize);
// Message message = canalSimpleConnector.getWithoutAck(batchSize);
long id = message.getId();
int size = message.getEntries().size();
log.info("當前監控到binLog消息數量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//1. 解析message對象
List<CanalEntry.Entry> entries = message.getEntries();
List<CanalDataParser.TwoTuple<CanalEntry.EventType, Map>> rows = CanalDataParser.printEntry(entries);
for (CanalDataParser.TwoTuple<CanalEntry.EventType, Map> tuple : rows) {
if(tuple.eventType == CanalEntry.EventType.INSERT) {
Student student = createStudent(tuple);
// 2。將解析出的對象同步到elasticSearch中
elasticUtils.saveEs(student, "student_index");
// 3.消息確認已處理
// canalSimpleConnector.ack(id);
canalHaConnector.ack(id);
}
if(tuple.eventType == CanalEntry.EventType.UPDATE){
Student student = createStudent(tuple);
elasticUtils.updateEs(student, "student_index");
// 3.消息確認已處理
// canalSimpleConnector.ack(id);
canalHaConnector.ack(id);
}
if(tuple.eventType == CanalEntry.EventType.DELETE){
elasticUtils.DeleteEs("student_index", tuple.columnMap.get("id").toString());
canalHaConnector.ack(id);
}
}
}
}
}
/**
* 封裝數據至Student
* @param tuple
* @return
*/
private Student createStudent(CanalDataParser.TwoTuple<CanalEntry.EventType, Map> tuple){
Student student = new Student();
student.setId(tuple.columnMap.get("id").toString());
student.setAge(Integer.parseInt(tuple.columnMap.get("age").toString()));
student.setName(tuple.columnMap.get("name").toString());
student.setSex(tuple.columnMap.get("sex").toString());
student.setCity(tuple.columnMap.get("city").toString());
return student;
}
/**
* 打開canal連接
*
* @param canalConnector
*/
private void openCanalConnector(CanalConnector canalConnector) {
//連接CanalServer
canalConnector.connect();
// 訂閱destination
canalConnector.subscribe();
}
/**
* 關閉canal連接
*
* @param canalConnector
*/
private void closeCanalConnector(CanalConnector canalConnector) {
//關閉連接CanalServer
canalConnector.disconnect();
// 注銷訂閱destination
canalConnector.unsubscribe();
}
}
CanalDemoApplication.java(Spring Boot啟動類)
package com.example.canal.study;
import com.example.canal.study.action.BinLogElasticSearch;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author haha
*/
@SpringBootApplication
public class CanalDemoApplication implements ApplicationRunner {
@Autowired
private BinLogElasticSearch binLogElasticSearch;
public static void main(String[] args) {
SpringApplication.run(CanalDemoApplication.class, args);
}
// 程序啟動則執行run方法
@Override
public void run(ApplicationArguments args) throws Exception {
binLogElasticSearch.binLogToElasticSearch();
}
}
application.properties
server.port=8081
spring.application.name = canal-demo
canal.server.ip = 192.168.124.5
canal.server.port = 11111
canal.destination = example
zookeeper.server.ip = 192.168.124.5:2181
zookeeper.sasl.client = false
elasticSearch.server.ip = 192.168.124.5
elasticSearch.server.port = 9200
Canal集群高可用的搭建
通過上面的學習,我們知道了單機直連方式的Canala應用。在當今互聯網時代,單實例模式逐漸被集群高可用模式取代,那么Canala的多實例集群方式如何搭建呢!
基于ZooKeeper獲取Canal實例
準備ZooKeeper的Docker鏡像與容器:
docker pull zookeeper
docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper
docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server
1、機器準備:
- 運行Canal的容器IP: 172.18.0.4 , 172.18.0.8
- ZooKeeper容器IP:172.18.0.3:2181
- MySQL容器IP:172.18.0.6:3306
2、按照部署和配置,在單臺機器上各自完成配置,演示時instance name為example。
3、修改canal.properties,加上ZooKeeper配置并修改Canal端口:
canal.port=11113
canal.zkServers=172.18.0.3:2181
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
4、創建example目錄,并修改instance.properties:
canal.instance.mysql.slaveId = 1235
#之前的canal slaveId是1234,保證slaveId不重復即可
canal.instance.master.address = 172.18.0.6:3306
注意: 兩臺機器上的instance目錄的名字需要保證完全一致,HA模式是依賴于instance name進行管理,同時必須都選擇default-instance.xml配置。
啟動兩個不同容器的Canal,啟動后,可以通過tail -100f logs/example/example.log查看啟動日志,只會看到一臺機器上出現了啟動成功的日志。
比如我這里啟動成功的是 172.18.0.4:
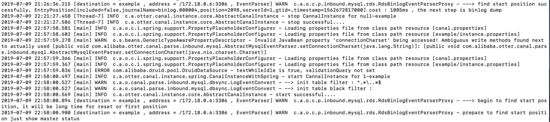
查看一下ZooKeeper中的節點信息,也可以知道當前工作的節點為172.18.0.4:11111:
[zk: localhost:2181(CONNECTED) 15] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}
客戶端鏈接, 消費數據
可以通過指定ZooKeeper地址和Canal的instance name,canal client會自動從ZooKeeper中的running節點獲取當前服務的工作節點,然后與其建立鏈接:
[zk: localhost:2181(CONNECTED) 0] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}
對應的客戶端編碼可以使用如下形式,上文中的CanalConfig.java中的canalHaConnector就是一個HA連接:
CanalConnector connector = CanalConnectors.newClusterConnector("172.18.0.3:2181", "example", "", "");
鏈接成功后,canal server會記錄當前正在工作的canal client信息,比如客戶端IP,鏈接的端口信息等(聰明的你,應該也可以發現,canal client也可以支持HA功能):
[zk: localhost:2181(CONNECTED) 4] get /otter/canal/destinations/example/1001/running
{"active":true,"address":"192.168.124.5:59887","clientId":1001}
數據消費成功后,canal server會在ZooKeeper中記錄下當前最后一次消費成功的binlog位點(下次你重啟client時,會從這最后一個位點繼續進行消費):
[zk: localhost:2181(CONNECTED) 5] get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.LogPosition","identity":{"slaveId":-1,"sourceAddress":{"address":"mysql.mynetwork","port":3306}},"postion":{"included":false,"journalName":"binlog.000004","position":2169,"timestamp":1562672817000}}
停止正在工作的172.18.0.4的canal server:
docker exec -it canal-server bash
cd canal-server/bin
sh stop.sh
這時172.18.0.8會立馬啟動example instance,提供新的數據服務:
[zk: localhost:2181(CONNECTED) 19] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.8:11111","cid":1}
與此同時,客戶端也會隨著canal server的切換,通過獲取ZooKeeper中的最新地址,與新的canal server建立鏈接,繼續消費數據,整個過程自動完成。
異常與總結
elasticsearch-head無法訪問Elasticsearch
es與es-head是兩個獨立的進程,當es-head訪問es服務時,會存在一個跨域問題。所以我們需要修改es的配置文件,增加一些配置項來解決這個問題,如下:
[root@localhost /usr/local/elasticsearch-head-master]# cd ../elasticsearch-5.5.2/config/
[root@localhost /usr/local/elasticsearch-5.5.2/config]# vim elasticsearch.yml
# 文件末尾加上如下配置
http.cors.enabled: true
http.cors.allow-origin: "*"
修改完配置文件后需重啟es服務。
elasticsearch-head查詢報406 Not Acceptable
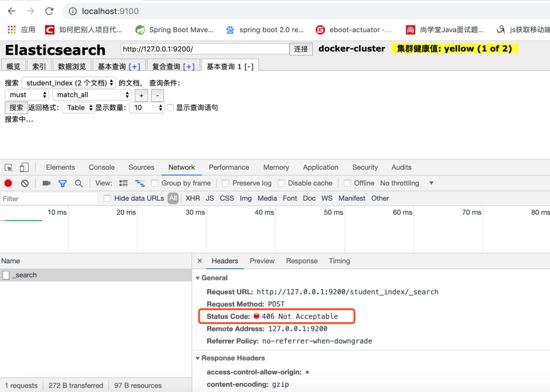
解決方法:
1、進入head安裝目錄;
2、cd _site/
3、編輯vendor.js 共有兩處
#6886行 contentType: "application/x-www-form-urlencoded
改成 contentType: "application/json;charset=UTF-8"
#7574行 var inspectData = s.contentType === "application/x-www-form-urlencoded" &&
改成 var inspectData = s.contentType === "application/json;charset=UTF-8" &&
使用elasticsearch-rest-high-level-client報org.elasticsearch.action.index.IndexRequest.ifSeqNo
#pom中除了加入依賴
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.1.1</version>
</dependency>
#還需加入
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.1.1</version>
</dependency>
相關參考: git hub issues 。
為什么ElasticSearch要在7.X版本不能使用type?
參考: 為什么ElasticSearch要在7.X版本去掉type?
使用spring-data-elasticsearch.jar報org.elasticsearch.client.transport.NoNodeAvailableException
由于本文使用的是elasticsearch7.x以上的版本,目前spring-data-elasticsearch底層采用es官方TransportClient,而es官方計劃放棄TransportClient,工具以es官方推薦的RestHighLevelClient進行調用請求。 可參考 RestHighLevelClient API 。
設置Docker容器開啟啟動
如果創建時未指定 --restart=always ,可通過update 命令
docker update --restart=always [containerID]
Docker for Mac network host模式不生效
Host模式是為了性能,但是這卻對Docker的隔離性造成了破壞,導致安全性降低。 在性能場景下,可以用--netwokr host開啟Host模式,但需要注意的是,如果你用Windows或Mac本地啟動容器的話,會遇到Host模式失效的問題。原因是Host模式只支持Linux宿主機。
參見官方文檔: https://docs.docker.com/network/host/ 。
客戶端連接ZooKeeper報authenticate using SASL(unknow error)

- zookeeper.jar與Dokcer中的ZooKeeper版本不一致
- zookeeper.jar使用了3.4.6之前的版本
出現這個錯的意思是ZooKeeper作為外部應用需要向系統申請資源,申請資源的時候需要通過認證,而sasl是一種認證方式,我們想辦法來繞過sasl認證。避免等待,來提高效率。
在項目代碼中加入System.setProperty("zookeeper.sasl.client", "false");,如果是Spring Boot項目可以在application.properties中加入zookeeper.sasl.client=false。
參考: Increased CPU usage by unnecessary SASL checks 。
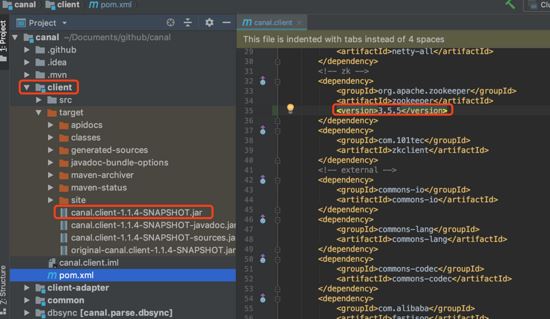
如果更換canal.client.jar中依賴的zookeeper.jar的版本
把Canal的官方源碼下載到本機git clone https://github.com/alibaba/canal.git ,然后修改client模塊下pom.xml文件中關于ZooKeeper的內容,然后重新mvn install:
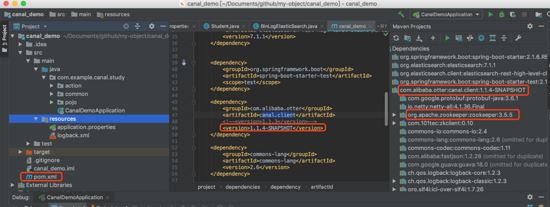
把自己項目依賴的包替換為剛剛mvn install生產的包:
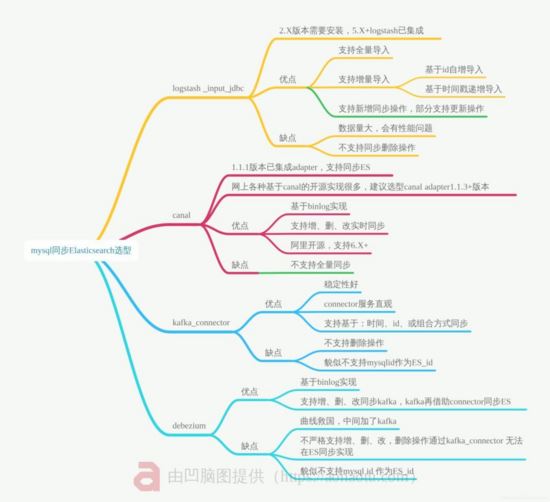
關于選型的取舍
總結
以上所述是小編給大家介紹的基于Docker結合Canal實現MySQL實時增量數據傳輸功能,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對腳本之家網站的支持!
如果你覺得本文對你有幫助,歡迎轉載,煩請注明出處,謝謝!
