目錄
- 1. Spark 與 Hadoop 比較
- 1.1 Haoop 的缺點
- 1.2 相較于Hadoop MR的優點
- 2. Spark 生態系統
- 2.1 大數據處理的三種類型
- 1. 復雜的批量數據處理
- 2. 基于歷史數據的交互式查詢
- 3. 基于實時數據流的數據處理
- 2.2 BDAS架構
- 2.3 Spark 生態系統
- 3. 基本概念與架構設計
- 3.1 基本概念
- 3.2 運行架構
- 3.3 各種概念之間的相互關系
- 4. Spark運行基本流程
- 5. Spark的部署和應用方式
- 5.1 Spark的三種部署方式
- 5.1.1 Standalone
- 5.1.2 Spark on Mesos
- 5.1.3 Spark on YARN
- 5.2 從Hadoop+Storm架構轉向Spark架構
- Hadoop+Storm架構
- 用Spark架構滿足批處理和流處理需求
- Spark架構的優點:
- 5.3 Hadoop和Spark的統一部署
1. Spark 與 Hadoop 比較
1.1 Haoop 的缺點
- 1. 表達能力有限;
- 2. 磁盤IO開銷大;
- 3. 延遲高;
- 4. 任務之間的銜接涉及IO開銷;
- 5. 在前一個任務執行完之前,其他任務就無法開始,難以勝任復雜、多階段的計算任務。
1.2 相較于Hadoop MR的優點
- 1. Spark的計算模式也屬于MR,但不局限于Map和Reduce操作,它還提供了多種數據集操作類型,編程模式也比Hadoop MR更靈活;
- 2. Spark提供了內存計算,可將中間結果放到內存中,對于迭代運算效率更高;
- 3. Spark 基于DAG的任務調度執行機制,要優于Hadoop MR的迭代執行機制。
|
Spark |
MapReduce |
| 數據存儲結構 |
使用內存構建彈性分布式數據集RDD,對數據進行運算和cache。 |
磁盤HDFS文件系統的split |
| 編程范式 |
DAG(Transformation+Action) |
Map+Reduce |
| 計算中間結果的存儲 |
在內存中維護,存取速度比磁盤高幾個數量級 |
落到磁盤,IO及序列化、反序列化代價大 |
| Task維護方式 |
線程 |
進程 |
| 時間 |
對于小數據集讀取能夠達到亞秒級的延遲 |
需要數秒時間才能啟動任務 |
2. Spark 生態系統
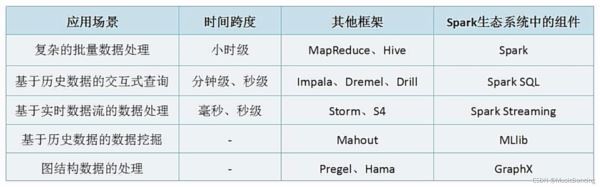
2.1 大數據處理的三種類型
1. 復雜的批量數據處理
時間跨度在數十分鐘到數小時
Haoop MapReduce
2. 基于歷史數據的交互式查詢
時間跨度在數十秒到數分鐘
Cloudera、Impala 這兩者實時性均優于hive。
3. 基于實時數據流的數據處理
時間跨度在數百毫秒到數秒
Storm
2.2 BDAS架構
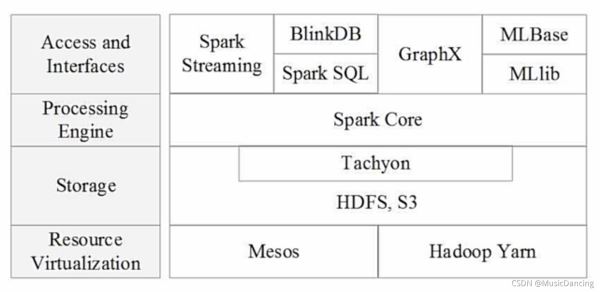
2.3 Spark 生態系統
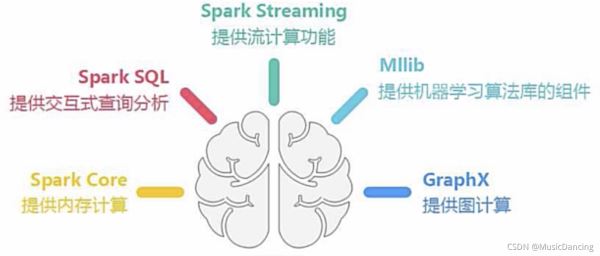
3. 基本概念與架構設計
3.1 基本概念
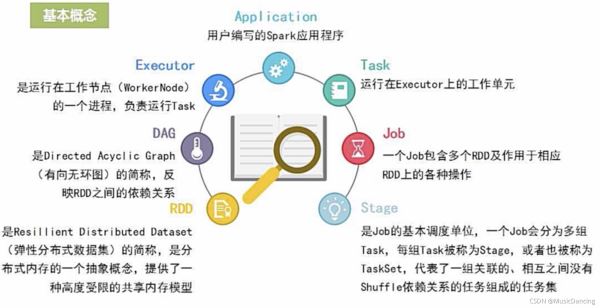
3.2 運行架構
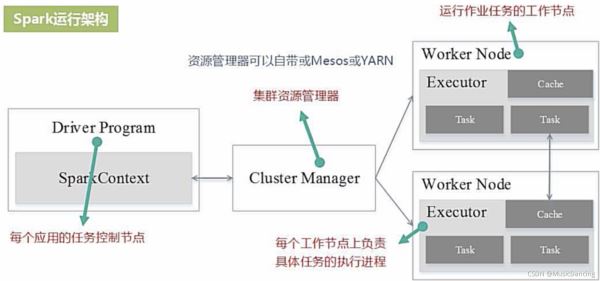
Spark采用Executor的優點:(相比于Hadoop的MR)
- 1. 利用多線程來執行具體的任務,減少任務的啟動開銷;
- 2. Executor中有一個BlockManager存儲模塊,會將內存和磁盤共同作為存儲設備,有效減少IO開銷。
3.3 各種概念之間的相互關系
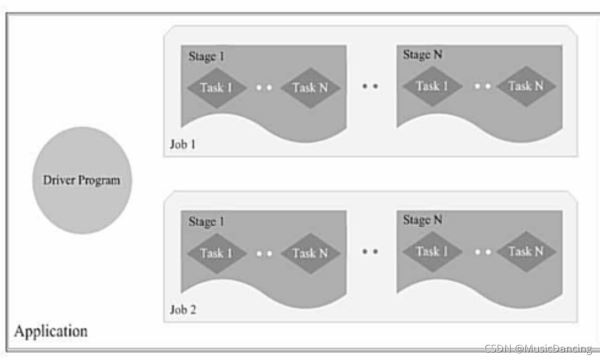
- 一個Application由一個Driver和若干個Job構成
- 一個Job由多個Stage構成
- 一個Stage由多個沒有shuffle關系的Task組成
當執行一個Application時,Driver會向集群管理器申請資源,啟動Executor,
并向Executor發送應用程序代碼和文件,然后在Executor上執行Task,運行結束后,
執行結果會返回給Driver,或者寫到HDFS或者其他數據庫中。
4. Spark運行基本流程
4.1 運行流程
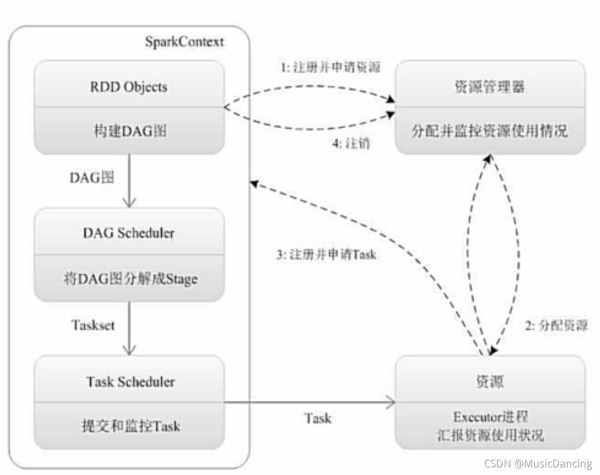
1. 為應用構建起基本的運行環境,即由Driver創建一個SparkContext進行資源的申請、任務的分配和監控。
2. 資源管理器為Executor分配資源,并啟動Executor進程。
- 3.1 SparkContext根據RDD的依賴關系構建DAG圖,DAG圖提交給DAGScheduler解析成Stage,然后把一個個TaskSet提交給底層調度器TaskScheduler處理。
- 3.2 Executor向SparkContext申請Task,TaskScheduler將Task發送給Executor運行并提供應用程序代碼。
4. Task在Executor上運行把執行結果反饋給TaskScheduler,然后反饋給DAGScheduler,運行完畢后寫入數據并釋放所有資源。
4.2 運行架構特點
1. 每個Application都有自己專屬的Executor進程,并且該進程在Application運行期間一直駐留。Executor進程以多線程的方式運行Task。
2. Spark運行過程與資源管理器無關,只要能夠獲取Executor進程并保持通信即可。
3. Task采用了數據本地性和推測執行等優化機制。(計算向數據靠攏。)
5. Spark的部署和應用方式
5.1 Spark的三種部署方式
5.1.1 Standalone
類似于MR1.0,slot為資源分配單位,但性能并不好。
5.1.2 Spark on Mesos
Mesos和Spark有一定的親緣關系。
5.1.3 Spark on YARN
mesos和yarn的聯系
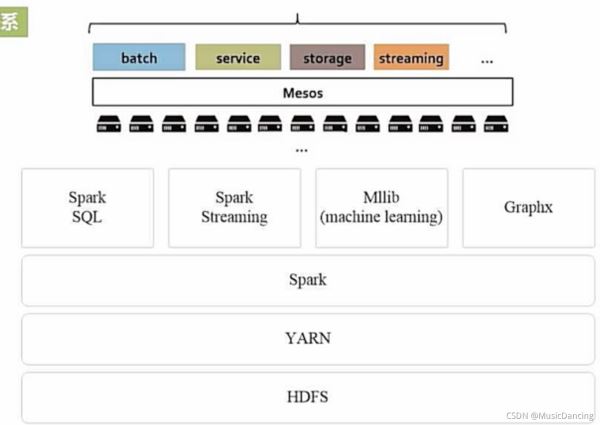
5.2 從Hadoop+Storm架構轉向Spark架構
Hadoop+Storm架構
這種部署方式較為繁瑣。
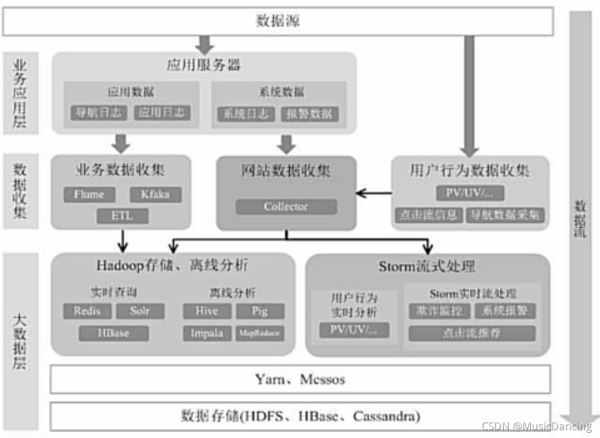
用Spark架構滿足批處理和流處理需求
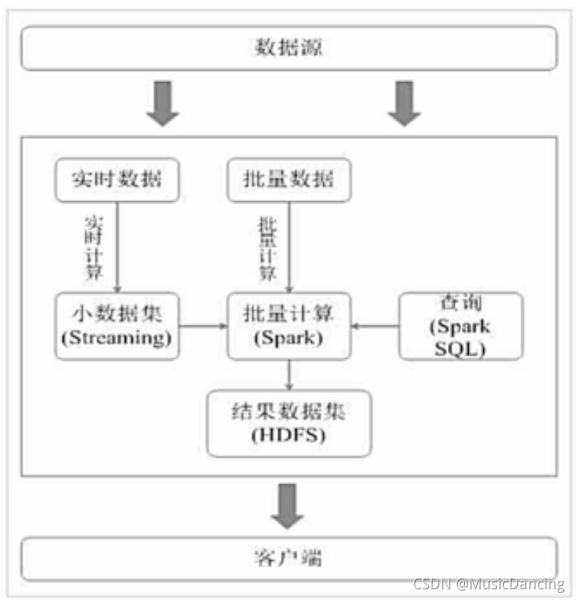
Spark用快速的小批量計算模擬流計算,并非真實的流計算。
無法實現毫秒級的流計算,對于需要毫秒級實時響應的企業應用而言,仍需采用流計算框架Storm等。
Spark架構的優點:
- 1. 實現一鍵式安裝和配置,線程級別的任務監控和告警;
- 2. 降低硬件集群、軟件維護、任務監控和應用開發的難度;
- 3. 便于做成統一的硬件、計算平臺資源池。
5.3 Hadoop和Spark的統一部署
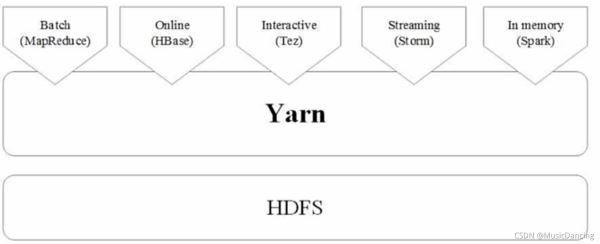
不同計算框架統一運行在YARN中
好處如下:
- 1. 計算資源按需伸縮;
- 2. 不用負載應用混搭,集群利用率高;
- 3. 共享底層存儲,避免數據跨集群遷移
現狀:
1. Spark目前還是無法取代Hadoop生態系統中的一些組件所實現的功能。
2. 現有的Hadoop組件開發的應用,完全遷移到Spark上需要一定的成本。
到此這篇關于Spark簡介以及與Hadoop對比分析的文章就介紹到這了,更多相關Spark與Hadoop內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
