近日,百度在語音識別技術方面再獲突破,將圖像識別技術成功“跨界”到語音領域,利用深層卷積神經(jīng)網(wǎng)絡(DeepCNN)應用于語音識別聲學建模中,將其與基于長短時記憶單元(LSTM)和連接時序分類(CTC)的端對端語音識別技術相結合,錯誤率相對降低10%,大幅度提升語音識別產(chǎn)品性能,是繼端對端語音識別后取得的另一次重大技術突破。
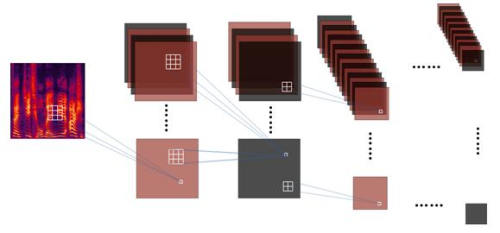
Deep CNN語音識別的建模過程
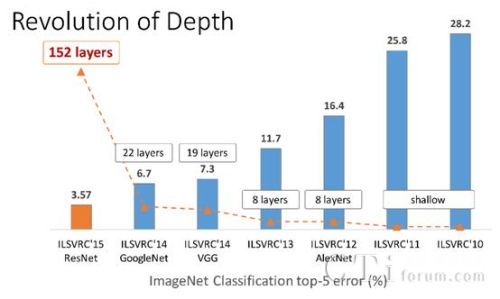
近年來,運用CNN技術的圖像識別成果頗豐,越來越深的CNN不斷刷新著圖像識別的精準度,以人臉識別為例,識別準確率高達99.7%。但CNN的進展在語音識別方面沒有得到充分的應用。作為一家在語音技術上有著深入研究的人工智能公司,百度將DeepCNN視為語音識別技術的下一個突破口。
ImageNet競賽中,越來越深的CNN不斷刷新著其性能
在商用領域的端對端語音識別技術中,百度首次嘗試引入更深層的CNN神經(jīng)網(wǎng)絡,使錯誤率相對降低10%。端對端技術則使用一個單獨的學習算法來完成從任務輸入端到輸出端的所有過程,減少了中間單元以及人為干預,在海量數(shù)據(jù)的支持下模型效果提升明顯。目前,百度的端對端技術處于業(yè)界領先水平。值得一提的是,語音識別都是基于時頻分析后的語音譜完成的,將整個語音信號分析得到的時頻譜當作一張圖像,就可以采用圖像中已廣泛應用的CNN進行識別,克服了語音信號多樣性的問題,且通過引入更深層的CNN,使語音識別性能得到顯著提升,正如百度語音技術部識別技術負責人李先剛博士所言:‘The Deeper,The Better’。
與學術研究不同,百度語音的研發(fā)立足點,聚焦于技術的實際應用,技術難度和實現(xiàn)程度更高。針對語音識別產(chǎn)品而言,必須具備在大規(guī)模語音數(shù)據(jù)庫上體現(xiàn)性能提升以及具有適合語音在線識別產(chǎn)品運行的模型。百度采用數(shù)千小時進行實驗的研究,并在近十萬小時的產(chǎn)品語音數(shù)據(jù)庫中進行驗證,且充足的語音數(shù)據(jù)資源,使基于端對端技術的語音識別系統(tǒng)明顯優(yōu)于以往的框架性能。
百度語音識別技術每年迭代算法模型
除此之外,百度語音技術在數(shù)據(jù)、計算能力、算法等三方面優(yōu)勢顯著。百度擁有約10萬小時的精準標注語音數(shù)據(jù),以及基于數(shù)百個GPU的高性能計算平臺。在算法方面,百度每年都在不斷優(yōu)化、迭代模型算法,語音識別效果顯著提升,領先業(yè)界。
此前,百度便利用端對端技術研發(fā)了Deep Speech 2深度語音識別技術,用于提高在嘈雜環(huán)境下語音識別的準確率。在噪音環(huán)境下,其錯誤率低于谷歌、微軟以及蘋果的語音系統(tǒng)。目前,百度語音識別準確率高達97%,并被美國權威科技雜志《麻省理工評論》列為2016年十大突破技術之一。另據(jù)李先剛博士透露,目前的確正在加緊Deep Speech 3的研發(fā)工作,而本次公布的Deep CNN不排除將會是Deep Speech 3的核心組成部分。