在《數據庫原理》里面,對聚簇索引的解釋是:聚簇索引的順序就是數據的物理存儲順序,而對非聚簇索引的解釋是:索引順序與數據物理排列順序無關。正式因為如此,所以一個表最多只能有一個聚簇索引。
不過這個定義太抽象了。在SQL Server中,索引是通過二叉樹的數據結構來描述的,我們可以這么理解聚簇索引:索引的葉節點就是數據節點。而非聚簇索引的葉節點仍然是索引節點,只不過有一個指針指向對應的數據塊。如下圖:
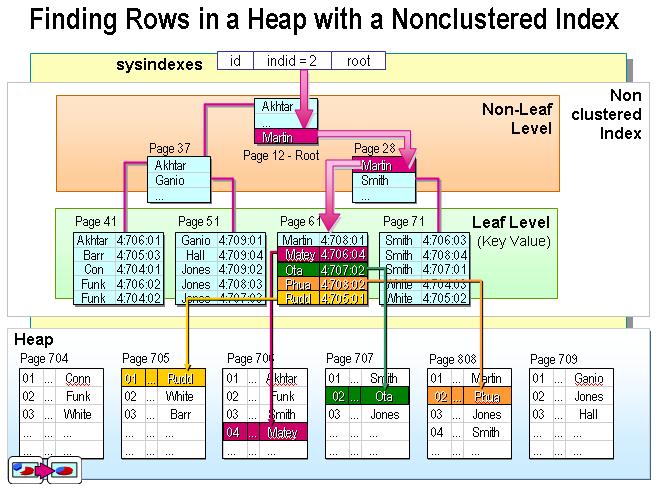
非聚簇索引
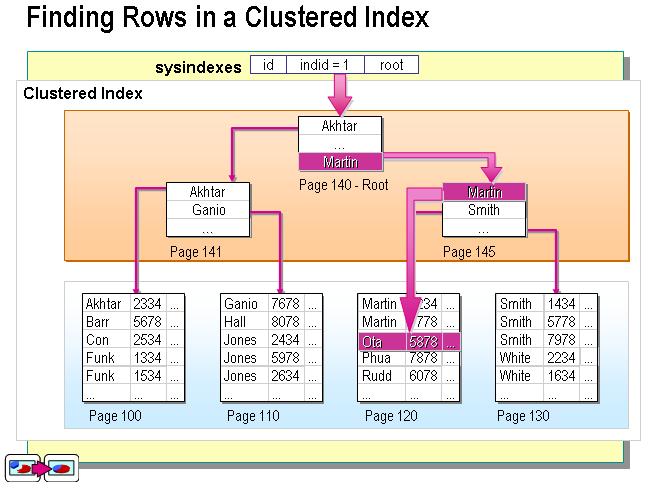
聚簇索引
聚簇索引與非聚簇索引的本質區別到底是什么?什么時候用聚簇索引,什么時候用非聚簇索引?
這是一個很復雜的問題,很難用三言兩語說清楚。我在這里從SQL Server索引優化查詢的角度簡單談談(如果對這方面感興趣的話,可以讀一讀微軟出版的《Microsoft SQL Server 2000數據庫編程》第3單元的數據結構引論以及第6、13、14單元)。
一、索引塊與數據塊的區別
大家都知道,索引可以提高檢索效率,因為它的二叉樹結構以及占用空間小,所以訪問速度塊。讓我們來算一道數學題:如果表中的一條記錄在磁盤上占用 1000字節的話,我們對其中10字節的一個字段建立索引,那么該記錄對應的索引塊的大小只有10字節。我們知道,SQL Server的最小空間分配單元是“頁(Page)”,一個頁在磁盤上占用8K空間,那么這一個頁可以存儲上述記錄8條,但可以存儲索引800條。現在我 們要從一個有8000條記錄的表中檢索符合某個條件的記錄,如果沒有索引的話,我們可能需要遍歷8000條×1000字節/8K字節=1000個頁面才能 夠找到結果。如果在檢索字段上有上述索引的話,那么我們可以在8000條×10字節/8K字節=10個頁面中就檢索到滿足條件的索引塊,然后根據索引塊上 的指針逐一找到結果數據塊,這樣IO訪問量要少的多。
二、索引優化技術
是不是有索引就一定檢索的快呢?答案是否。有些時候用索引還不如不用索引快。比如說我們要檢索上述表中的所有記錄,如果不用索引,需要訪問8000 條×1000字節/8K字節=1000個頁面,如果使用索引的話,首先檢索索引,訪問8000條×10字節/8K字節=10個頁面得到索引檢索結果,再根 據索引檢索結果去對應數據頁面,由于是檢索所有數據,所以需要再訪問8000條×1000字節/8K字節=1000個頁面將全部數據讀取出來,一共訪問了 1010個頁面,這顯然不如不用索引快。
SQL Server內部有一套完整的數據檢索優化技術,在上述情況下,SQL Server的查詢計劃(Search Plan)會自動使用表掃描的方式檢索數據而不會使用任何索引。那么SQL Server是怎么知道什么時候用索引,什么時候不用索引的呢?SQL Server除了日常維護數據信息外,還維護著數據統計信息,下圖是數據庫屬性頁面的一個截圖:
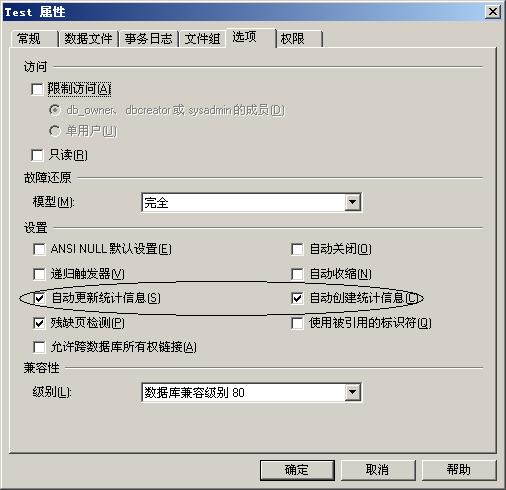
從圖中我們可以看到,SQL Server自動維護統計信息,這些統計信息包括數據密度信息以及數據分布信息,這些信息幫助SQL Server決定如何制定查詢計劃以及查詢是是否使用索引以及使用什么樣的索引(這里就不再解釋它們到底如何幫助SQL Server建立查詢計劃的了)。我們還是來做個實驗。建立一張表:tabTest(ID, unqValue,intValue),其中ID是整形自動編號主索引,unqValue是uniqueidentifier類型,在上面建立普通索 引,intValue 是整形,不建立索引。之所以掛上一個沒有索引的intValue字段,就是防止SQL Server使用索引覆蓋查詢優化技術,這樣實驗就起不到作用了。向表中錄入10000條隨機記錄,代碼如下:
CREATE TABLE [dbo].[tabTest] (
[ID] [int] IDENTITY (1, 1) NOT NULL ,
[unqValue] [uniqueidentifier] NOT NULL ,
[intValue] [int] NOT NULL
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tabTest] WITH NOCHECK ADD
CONSTRAINT [PK_tabTest] PRIMARY KEY CLUSTERED
(
[ID]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tabTest] ADD
CONSTRAINT [DF_tabTest_unqValue] DEFAULT (newid()) FOR [unqValue]
GO
CREATE INDEX [IX_tabTest_unqValue] ON [dbo].[tabTest]([unqValue]) ON[PRIMARY]
GO
declare @i int
declare @v int
set @i=0
while @i10000
begin
set @v=rand()*1000
insert into tabTest ([intValue]) values (@v)
set @i=@i+1
end
然后我們執行兩個查詢并查看執行計劃,如圖:(在查詢分析器的查詢菜單中可以打開查詢計劃,同時圖上第一個查詢的GUID是我從數據庫中找的,大家做實驗的時候可以根據自己數據庫中的值來定):
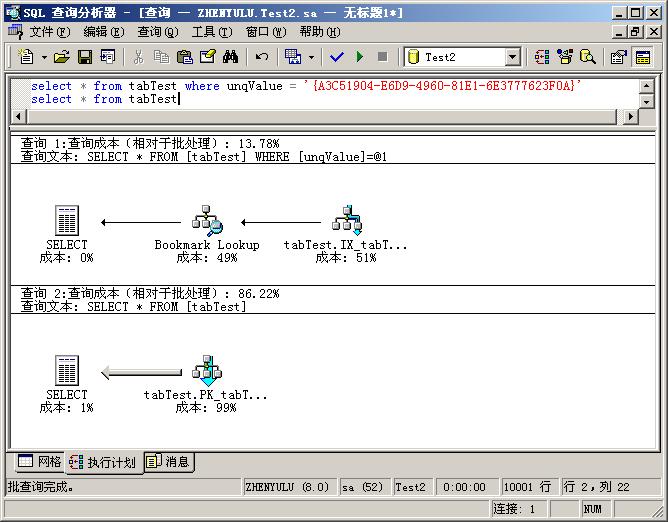
從圖中可以看出,在第一個查詢中,SQL Server使用了IX_tabTest_unqValue索引,根據箭頭方向,計算機先在索引范圍內找,找到后,使用Bookmark Lookup將索引節點映射到數據節點上,最后給出SELECT結果。在第二個查詢中,系統直接遍歷表給出結果,不過它使用了聚簇索引,為什么呢?不要忘 了,聚簇索引的頁節點就是數據節點!這樣使用聚簇索引會更快一些(不受數據刪除、更新留下的存儲空洞的影響,直接遍歷數據是要跳過這些空洞的)。
下面,我們在SQL Server中將ID字段的聚簇索引更改為非聚簇索引,然后再執行select * from tabTest,這回我們看到的執行計劃變成了:
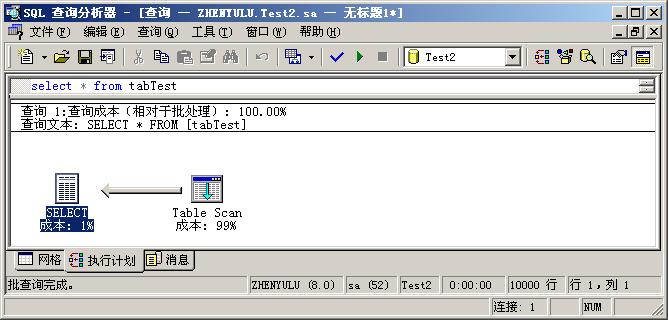
SQL Server沒有使用任何索引,而是直接執行了Table Scan,因為只有這樣,檢索效率才是最高的。
三、聚簇索引與非聚簇索引的本質區別
現在可以討論聚簇索引與非聚簇索引的本質區別了。正如本文最前面的兩個圖所示,聚簇索引的葉節點就是數據節點,而非聚簇索引的頁節點仍然是索引檢點,并保留一個鏈接指向對應數據塊。
還是通過一道數學題來看看它們的區別吧:假設有一8000條記錄的表,表中每條記錄在磁盤上占用1000字節,如果在一個10字節長的字段上建立非 聚簇索引主鍵,需要二叉樹節點16000個(這16000個節點中有8000個葉節點,每個頁節點都指向一個數據記錄),這樣數據將占用8000條 ×1000字節/8K字節=1000個頁面;索引將占用16000個節點×10字節/8K字節=20個頁面,共計1020個頁面。
同樣一張表,如果我們在對應字段上建立聚簇索引主鍵,由于聚簇索引的頁節點就是數據節點,所以索引節點僅有8000個,占用10個頁面,數據仍然占有1000個頁面。
下面我們看看在執行插入操作時,非聚簇索引的主鍵為什么比聚簇索引主鍵要快。主鍵約束要求主鍵不能出現重復,那么SQL Server是怎么知道不出現重復的呢?唯一的方法就是檢索。對于非聚簇索引,只需要檢索20個頁面中的16000個節點就知道是否有重復,因為所有主鍵 鍵值在這16000個索引節點中都包含了。但對于聚簇索引,索引節點僅僅包含了8000個中間節點,至于會不會出現重復必須檢索另外1000個頁數據節點 才知道,那么相當于檢索10+1000=1010個頁面才知道是否有重復。所以聚簇索引主鍵的插入速度要比非聚簇索引主鍵的插入速度慢很多。
讓我們再來看看數據檢索的效率,如果對上述兩表進行檢索,在使用索引的情況下(有些時候SQL Server執行計劃會選擇不使用索引,不過我們這里姑且假設一定使用索引),對于聚簇索引檢索,我們可能會訪問10個索引頁面外加1000個數據頁面得 到結果(實際情況要比這個好),而對于非聚簇索引,系統會從20個頁面中找到符合條件的節點,再映射到1000個數據頁面上(這也是最糟糕的情況),比較 一下,一個訪問了1010個頁面而另一個訪問了1020個頁面,可見檢索效率差異并不是很大。所以不管非聚簇索引也好還是聚簇索引也好,都適合排序,聚簇 索引僅僅比非聚簇索引快一點。
結語
好了,寫了半天,手都累了。關于聚簇索引與非聚簇索引效率問題的實驗就不做了,感興趣的話可以自己使用查詢分析器對查詢計劃進行分析。SQL Server是一個很復雜的系統,尤其是索引以及查詢優化技術,Oracle就更復雜了。了解索引以及查詢背后的事情不是什么壞事,它可以幫助我們更為深 刻的了解我們的系統。
您可能感興趣的文章:- mysql聚簇索引的頁分裂原理實例分析
- MySQL 索引的優缺點以及創建索引的準則
- MySQL btree索引與hash索引區別
- MySQL 函數索引的優化方案
- Mysql索引性能優化問題解決方案
- 導致MySQL索引失效的一些常見寫法總結
- 詳解MySQL 聚簇索引與非聚簇索引
