spark要配合Hadoop的hdfs使用,然而Hadoop的特點就是分布式,在一臺主機上搭建集群有點困難,百度后發現可以使用docker構建搭建,于是開搞:
github項目:https://github.com/kiwenlau/hadoop-cluster-docker
參考文章:https://www.jb51.net/article/109698.htm
docker安裝
文章中安裝的是docker.io
但是我推薦安裝docker-ce,docker.io版本太老了,步驟如下:
1、國際慣例更新下APT軟件包的源
2、安裝軟件包以允許apt通過HTTPS使用存儲庫
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
3、因為被墻使用教育網鏡像:
復制代碼 代碼如下:
curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add
4、同樣
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
5、更新下我們的軟件源
6、安裝docker
sudo apt-get install docker-ce
7、啟動docker服務
sudo service docker start
or
sudo systemctl start docker
8、覺得有必要可以設置開機自帶啟動
sudo systemctl enable docker
9、關閉自啟動
sudo systemctl disable docker
10、國內訪問docker會受限制,可以使用加速服務,阿里云、網易云、DaoCloud
11、運行 docker run hello-world 測試是否安裝成功
12、想要安裝其他image 可以到docker hub上找
https://hub.docker.com/
或是直接在github上搜索相應docker
搭建Hadoop集群
搭建過程很簡單
https://github.com/kiwenlau/hadoop-cluster-docker
上步驟說明很詳細:
1、pull鏡像,速度慢的換國內鏡像源
sudo docker pull kiwenlau/hadoop:1.0
200多m不算大,我下過jupyter官方pyspark的docker 5g…
2、克隆項目到本地
git clone https://github.com/kiwenlau/hadoop-cluster-docker
其實只用到里面的 start-container.sh 文件也可以單獨下,復制粘貼啥的
3、start-container.sh 需要修改一下 cd 到文件目錄
sudo gedit start-container.sh 修改如下
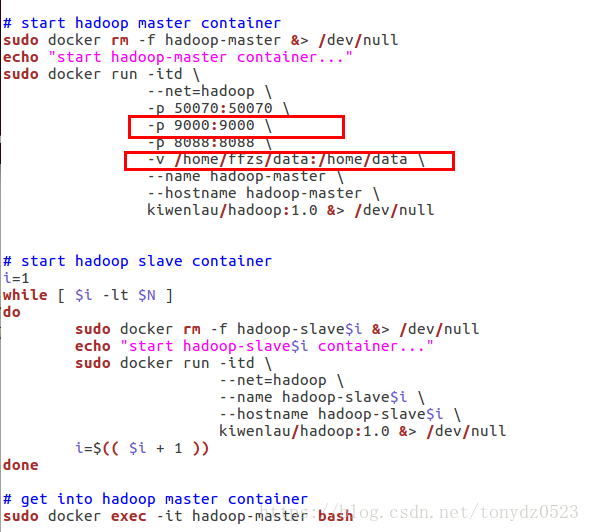
開放9000端口還有創建共享文件夾方便以后使用
4、保存之后,創建docker-Hadoop網絡
sudo docker network create --driver=bridge hadoop
5、開啟容器
sudo ./start-container.sh

6、開啟Hadoop集群
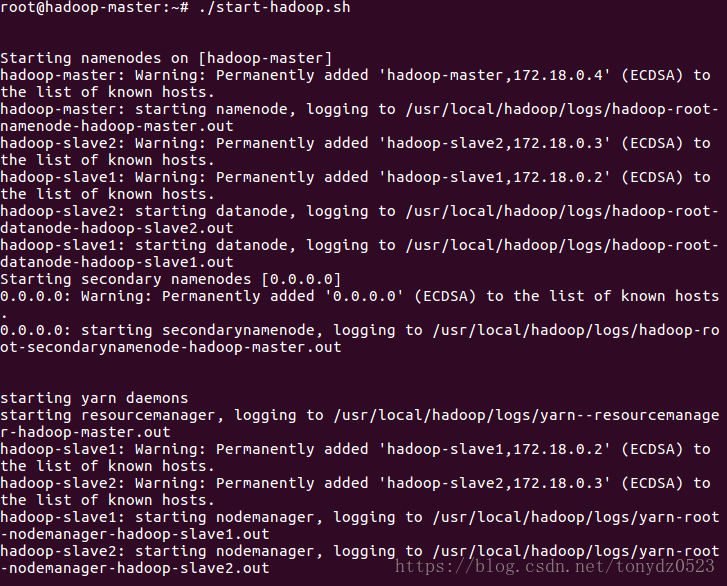
7、測試一下Hadoop,在hdfs上創建 test/input 目錄
hadoop fs -mkdir -p /test/input
hadoop fs -ls /test

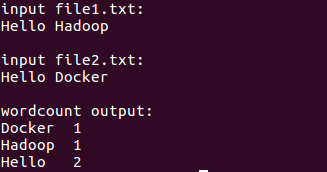
8、運行word-count程序
結果如下
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持腳本之家。
